# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

6月4日,Boson AI 与 SGLang-Omni 团队宣布,SGLang-Omni 已完成对 Higgs Audio v3 TTS 的端到端 Serving 支持。作为一家成立于 2023 年的 AI 基础设施公司,李沐与 Alex Smola共同创立了 Boson AI,聚焦大模型时代的系统与基础设施创新。而 SGLang 团队则是当前开源推理领域的重要力量,其维护的 SGLang 已成为业界广泛采用的大模型推理框架之一。
此次接入的 Higgs Audio v3 TTS,是 Boson AI 面向对话场景推出的新一代语音生成模型。该模型能够在低延迟条件下生成自然且富有表现力的语音输出,并支持开发者直接通过文本控制情绪、风格、韵律乃至环境音效。同时,模型覆盖超过 100 种语言,实现个位数 WER/CER,并具备零样本声音克隆能力,在语音交互、多语言 AI Agent 和数字人等场景展现出较强的应用潜力。
不过,对于 SGLang-Omni 团队而言,接入 Higgs Audio v3 TTS 的意义并不止于新增一个模型支持。更重要的是,Higgs 所代表的正是一类正在快速兴起的新型生成模型:其推理过程不再依赖单一路径的自回归解码,而是由多个计算特征差异显著的阶段协同完成。随着语音、多模态和 Agent 系统的发展,这种 Multi-Stage 架构正变得越来越普遍。比传统针对单一 Decode Loop 优化的推理框架,SGLang-Omni 从系统层面对多阶段生成流程进行调度与优化,使不同计算阶段能够高效协同运行,从而为下一代语音模型、多模态模型以及复杂 Agent 系统提供更具扩展性的推理能力。
相比传统 TTS 模型,面向 AI Agent 和实时交互场景的语音生成系统,对延迟和连续性提出了更高要求。
对话式 TTS 的难点,不只是把一段完整文字读得好听。真实的语音智能体往往只能先拿到半句话,甚至几个字,就需要开始回应;后续文本还在持续到来,生成出来的声音却不能前后割裂。Higgs Audio v3 TTS 从设计上就面向这种流式对话场景:它不需要等到完整句子或标点出现,就可以开始合成语音,并在后续文本继续输入时保持音色、情绪和语速的一致。
从架构上看,Higgs 基于 Qwen3-4B backbone,是一个约 4B 参数的自回归解码器。模型消费交错排列的文本 token 和音频 token。音频会先由 Higgs Tokenizer 编码成 25 fps、8 路离散 codebook,再通过 delayed pattern 交错排列;多 codebook embedding 被融合后送入 backbone,最后由融合的多 codebook head 解码回 24 kHz 波形。整个生成过程在文本块与音频块之间交替推进,使得每个新的音频片段都能同时参考提示音频和已经生成的上下文。
在多语言能力方面,Higgs Audio v3 TTS 已覆盖 111 种语言和方言。
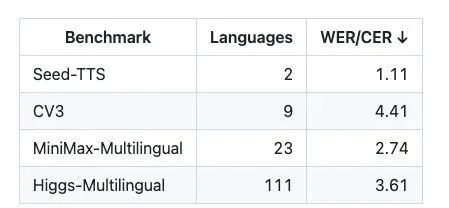
根据 Boson AI 公布的数据,在内部 Higgs-Multilingual 评测集中,模型在其中 100 种语言上的 WER/CER 均达到个位数水平。在公开的多语言声音克隆 Benchmark 中,Higgs Audio v3 在 Seed-TTS、CV3 以及 MiniMax-Multilingual 等测试集上的 Macro-average WER/CER 同样保持个位数表现。
与此同时,模型支持零样本声音克隆,仅需一段较短的参考音频即可复现目标音色,并支持跨语言迁移生成,即同一参考声音可以直接应用于不同语言的语音合成任务。
下表展示了 Higgs Audio v3 TTS 在零样本声音克隆场景下的 WER/CER(↓,%)表现。所有结果均基于对应 Benchmark 的语言集合进行 Macro-average 统计,评测指标及归一化流程均可复现。
Higgs Audio v3 TTS 不只追求音质,也重视可控性。开发者可以把控制标记直接写进输入文本,在同一段文本流里切换情绪、说话风格、语速、音高,插入停顿,甚至触发音效:控制标记覆盖 20 多种情绪
Higgs Audio v3 TTS 的 Serving 由 SGLang-Omni 提供支持。
与标准大语言模型不同,Higgs 这类新一代语音生成模型很难被纳入单一的自回归解码流程。其端到端生成过程往往由多个计算特征不同的阶段组成:有些阶段类似传统 AR Decoding,有些更接近轻量级函数计算,还有些阶段需要持续接收文本并实时输出音频。
SGLang-Omni 的目标,就是让这类 multi-stage 模型可以用统一而清晰的方式被服务起来:每个 stage 按自己的计算特性调度,stage 之间用低开销通信连接,显存和进程拓扑则在框架层统一管理。
事实上,随着语音、多模态和 Agent 系统的发展,越来越多模型开始呈现 Multi-Stage 特征。除了 Higgs Audio,Qwen3-Omni 的 Thinker-Talker-MTP 架构、Fish Audio S2-Pro 的 Dual-AR 方案,以及 Ming-Omni、LLaDA2.0-Uni 等全模态模型,都属于这一范式。
为此,SGLang-Omni 从设计之初便围绕 Stage 抽象构建运行时系统。模型配置负责定义整个 Pipeline 的阶段划分、GPU 部署和进程拓扑;Coordinator 负责请求在不同阶段之间的路由;而每个 Stage 则拥有独立的 Scheduler,以适配不同类型的计算任务。
其中,自回归阶段继承了 SGLang 在 Continuous Batching、Prefill/Decode 混合调度、KV Cache 管理和 CUDA Graph 等方面的优化能力;而轻量级 Encoder、聚合器等非自回归模块,则采用更简洁的调度机制。对于 Vocoder 等流式模块,系统则针对 Chunk 的持续输入与输出进行了专门优化。
为了保证多阶段推理能够高效运行,SGLang-Omni 重点解决了三个核心问题:首先是通信层解耦,控制信号与 Tensor 数据分离传输,降低跨阶段协同开销;其次是统一管理进程、GPU 与阶段之间的部署拓扑,使单机部署和大规模分布式部署能够采用同一套架构;最后是显存隔离机制,将显存资源从“模型级”管理升级到“阶段级”管理,避免不同阶段在运行过程中相互争抢资源。
从某种意义上说,SGLang-Omni 并不仅仅是在支持 Higgs Audio 这一款模型,而是在为越来越复杂的 Multi-Stage 生成模型构建一套通用推理基础设施。随着语音、多模态和 Agent 系统不断演进,这种面向多阶段生成流程的推理架构,也正在成为下一代 AI 系统的重要底座。
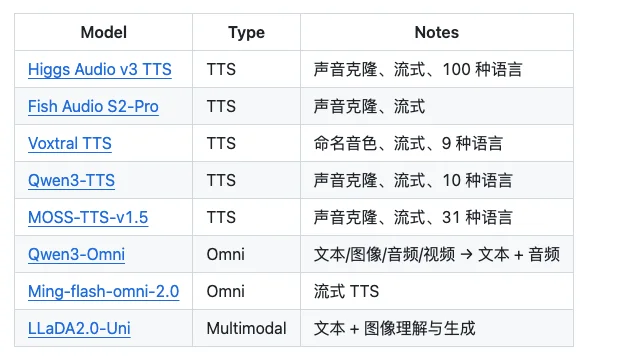
Higgs 已经加入 SGLang-Omni 支持的 TTS 与 omni 模型生态:
除了底层框架设计之外,SGLang-Omni 还围绕 Higgs Audio v3 TTS 进行了一轮端到端优化。
优化覆盖了整个推理链路:在自回归 Backbone 侧,团队引入 CUDA Graph 捕获、异步解码以及设备与主机之间的数据传输优化,减少解码过程中的同步开销;在编码器侧,将部分预处理流程并入推理阶段,并为参考音频引入缓存机制,以降低重复请求的计算成本;在声码器环节,则增加批量解码能力,进一步提升吞吐效率。
针对语音克隆场景,团队还对缓存系统进行了优化。通过将缓存按参考音频进行划分,相同声音的重复请求能够直接复用已有前缀计算结果,从而减少额外推理开销。
与此同时,SGLang-Omni 重新统一了调度体系。团队弃用了 Higgs 早期的定制调度方案,转而采用共享的 OmniScheduler,并实现了真正意义上的 SSE 流式调度能力,使模型能够更快返回首个音频片段,显著降低用户感知延迟。
在性能测试中,团队基于 Seed-TTS 英文测试集对 Higgs Audio v3 TTS 进行了评估。测试环境为单张 H100 GPU,服务端开启 CUDA Graph,并采用 BF16 精度运行。
结果显示,在不同并发配置下,系统能够持续保持稳定吞吐,并实现低于实时播放速度的实时因子(RTF)。这意味着模型生成语音的速度已经超过音频本身的播放速度,具备支撑实时语音交互和大规模在线服务的能力。
对于 SGLang-Omni 而言,支持 Higgs Audio 并非终点,而是验证 Multi-Stage 推理架构的重要一步。
接下来,团队将继续跟进 SGLang 主线演进,使自回归模块持续受益于 CUDA、Kernel 优化、调度机制以及 Speculative Decoding 等最新能力;同时推进模型抽象层重构,希望未来新模型接入能够从“工程适配”转变为“声明式配置”,降低复杂模型的接入成本。
另一项重要方向是将 SGLang-Omni 扩展为后训练基础设施。团队计划支持端到端强化学习训练(End-to-End RL),使框架不仅承担在线 Serving 任务,也能够成为 Omni 模型与语音模型的高吞吐 Rollout 后端,进一步打通推理与后训练流程。
与此同时,跨节点 Multi-Stage Pipeline 以及更完整的 Diffusion Stage 支持也在持续推进中。随着语音、多模态和 Agent 系统不断复杂化,SGLang-Omni 希望通过统一的 Stage 抽象、调度接口、通信机制和资源管理体系,构建面向下一代生成模型的通用推理基础设施。
文章来自于微信公众号 "Z Potentials",作者 "Z Potentials"



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】MockingBird是一个5秒钟即可克隆你的声音的AI项目。
项目地址:https://github.com/babysor/MockingBird
【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
