# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2K 图像 210ms 解码,4K 细节直接生成,传统「解码 + 超分」流水线可能要被重写了。
文生图模型现已内卷至 4K、超写实、电影级光影水准,但一张 AI 图像要想像 GPT-Image2 一样呈现高级质感,只靠增加扩散主干的参数规模和训练数据就足够了吗?
主流文生图模型通常分两步:在「潜空间」生成压缩的潜在表征(latent),再由「解码器」(decoder)还原为像素图。传统解码器仅负责「解压」,不主动创造细节。但在生成 2K、4K 高精图片时,解码器能否处理纹理细节,兼顾速度与显存,已成为高精渲染的瓶颈。这个长期被低估的「从 latent 到 pixel」转换环节,正是决定最终图片质感的关键。
现在,英伟达 Spatial Intelligence Lab 团队提出了一种新解法:Pixel diffusion Decoder (PiD)。

简单说,PiD 把 latent decoding 本身改造成一个生成式 pixel diffusion 过程,并且在解码的同时还做到了 4 倍甚至 8 倍的上采样,让最终的图像增加了惊人的细节。
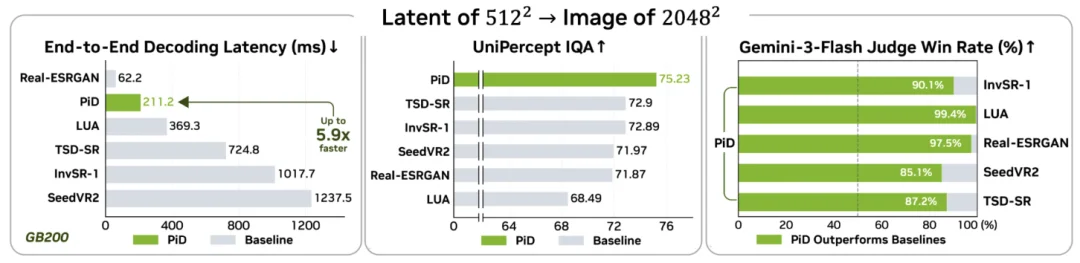
PiD 可以把对应 512×512 图像的 latent,直接解码成 2048×2048 的像素输出;在 GB200 上 2K 分辨率解码延迟约 210ms;在消费级 RTX 5090 上也能做到 1 秒以内,峰值显存约 13GB。更重要的是,它不仅快,而且细节更锐、质感更强,在多个图像质量指标上超过传统扩散超分级联方案。
这或许揭示了 GPT-Image2 这类高精图像模型背后一个更通用的趋势:高分辨率和多细节生成的关键,不只是「更大的生成模型」,也可能是「更会生成细节的 decoder」。


当前主流文生图模型大多基于潜在扩散模型(latent diffusion model)。
它们不会直接在完整像素空间里生成图像,而是先在一个压缩后的潜空间中完成去噪和构图,再通过 VAE decoder 把潜在表示还原为像素图像。
这个设计极大降低了生成成本,也让 Stable Diffusion、FLUX 等模型成为可能。
但问题也随之出现:传统 decoder 本质上是重建型模块,它的目标是尽可能还原编码器压缩的信息,而不是主动生成新的高频细节。
当目标分辨率来到 2K、4K 时,这个弱点会被放大。
一方面,latent 中本来就丢失了一些细节;另一方面,VAE decoder 往往会把 latent 里的噪声、瑕疵、伪影一起传递到最终图像中。而为了实现高分辨率生成,很多系统不得不在后面再接一个 超分辨率模型,这就是典型的级联流水线:
低分辨率潜在表示 → VAE 解码 → 超分扩散模型 → 高分辨率图像
看起来合理,但代价很高:步骤多、延迟高、显存压力大,而且每一环都可能引入新的失真。
PiD 要做的,就是砍掉这条流水线。

PiD 的核心思想很直接:既然像素扩散模型已经证明自己擅长生成高频细节,那为什么不直接让它承担 decoder 的角色?
于是,PiD 把潜在表示解码重新定义为一个条件像素扩散模型(conditional pixel diffusion model)。
潜在表示负责提供全局结构、语义布局和主体信息;像素扩散模型负责在目标分辨率下合成纹理、边缘、文字、皮肤、毛发、布料等细节。
换句话说,PiD 不再是「从 latent 里还原信息」,而是「以 latent 为条件,在高分辨率像素空间里重新生成一张图」。
这也是它和传统 VAE decoder 的根本区别:
VAE decoder 更像一个压缩文件的解压器,PiD 更像一个带生成能力的高分辨率渲染器。
论文中,PiD 基于 PixelDiT 这类像素空间扩散模型构建,并加入一个轻量级适配器,将低分辨率 latent 注入到高分辨率像素扩散主干中。为了让模型知道什么时候该相信 latent、什么时候该发挥生成先验,团队还设计了 sigma-aware gate:潜在表征越干净,注入越强;潜在表征越嘈杂,模型越依赖自身的像素生成先验。
这让 PiD 不仅能处理完整去噪后的 latent,还能处理尚未完全去噪的中间 latent。
这个设计带来了一个非常实用的能力:提前终止 latent diffusion。
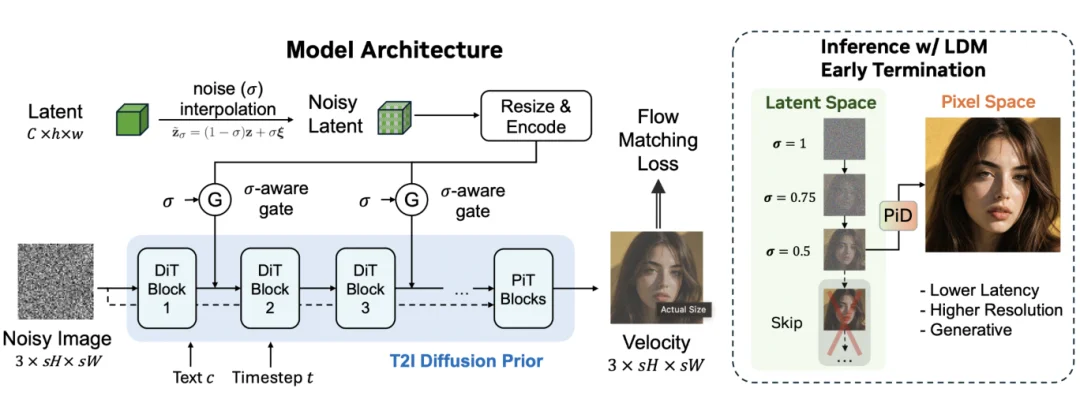
在 FLUX.1 [dev] 这类模型中,完整生成通常需要 28 个 denoising step。PiD 的设计让推理变得更加有趣:不一定要等 latent diffusion 全部跑完。
论文中,PiD 可以在 FLUX.1 [dev] 第 24 步甚至更早就接管尚未完全去噪潜在表征,并直接生成 2048×2048 图像。
这意味着,潜空间的去噪过程可以更早停下来,剩余的细节生成交给 PiD 在像素空间完成。
论文实验显示,完全跑满 denoising step 时,PiD 更忠实于原始 latent;而在中间 step 接管时,由于 latent 还没有把所有细节「钉死」,PiD 反而有更多空间去补充高频纹理,部分场景中会生成更锐利、更丰富的细节。
这相当于把高精渲染过程拆成两层:
这对于商业图像生成系统尤其重要,因为延迟、成本、显存占用,都直接影响服务规模。

在 2048×2048 解码任务上,PiD 的速度数据非常亮眼。
以 GB200 + torch.compile 为例,PiD 2K 解码约 211ms。对比常见扩散超分基线:
也就是说,相比扩散式超分管线,PiD 大约快 3 到 6 倍。
而它并不是用画质换速度。
论文使用 MUSIQ、NIQE、DEQA、MANIQA、Q-Align、Unipercept、VisualQuality-R1 等多种图像质量指标评测。结果显示,在 FLUX.1、FLUX.2、SD3、Z-Image 等 VAE latent,以及 DINOv2、SigLIP 等 vision encoder latent 上,PiD 在大多数指标上取得最优或接近最优表现。
论文还用闭源多模态大模型做图像质量评判,让模型比较 PiD 结果和级联超分结果。在 Claude 4.6 Opus、Gemini 3 Flash、GPT 5.5 系列评测器中,PiD 对比所有方法均以高胜率胜出。
换句话说,PiD 不仅快,而且效果还能更好。

PiD 生成更好的毛发细节,且耗时更短
PiD 具有更高的图像质量指标
PiD 另一个值得注意的地方,它被验证可以适配多种 latent 来源,包括而不限于:FLUX.1、FLUX.2、SDXL、SD3、Z-Image、DINOv2、SigLIP-2……
这点很关键。
这证明了 PiD 是一个通用的范式:只要潜在表征能提供结构和语义,PiD 就可以把它转化为高分辨率图像。
尤其是在 RAE 这类表征自编码器(representation autoencoder) 中,使用 DINOv2 / SigLIP-2 这些视觉编码器的潜空间,他们表征往往更语义化,保留了高层结构,但对底层纹理约束不充分。传统解码器很难补齐这些缺失的外观细节,而 PiD 正好可以用生成式能力来补充这部分细节。
这意味着,未来潜空间的设计可以更大胆:潜在表征不必负责保存所有像素细节,只要保住结构和语义,剩下的高频细节可以交给 PiD 这类生成式 decoder。
高分辨率图像生成还有另一条路线:原生生成 2K 图像。
问题是,成本非常高。
论文将 FLUX.2 原生 2K、PixelDiT 原生 2K,以及 FLUX.2 先生成 512×512 latent 再接 PiD 解码 2K 图像的方案进行了对比。
结果显示,在单张 GB200 上、不使用 torch.compile 的设置下:
也就是说,FLUX.2 + PiD 的路线比 PixelDiT 快 1.87 倍,比 FLUX.2 native 2K 快 14.3 倍。
在画面表现上,FLUX.2 + PiD 比 PixelDiT 有着更强指令跟随能力和画质;和 FLUX.2 相比仍然保持有竞争力的视觉质量,在一些细节甚至更锐。
这给高分辨率生成提供了一个新的可靠的工程方案:
这种解耦方式,对于在线图像生成服务、批量内容生产、广告创意、电商图、游戏资产、影视概念图等场景,都有直接价值。

PiD 不只停留在 2K。
论文进一步展示了 4K 解码结果:给定低分辨率潜在表征,PiD 可以直接生成 4096×4096 图像,并补充更多细节。
从实验设置看,4K 版本沿用了 2K 的训练范式:先训练 4K 分辨率下的像素扩散模型先验,再加入潜在表征适配器,最后通过 DMD2 蒸馏成 4-step 的模型。不需要额外的设计和改动,自然的 scale up 到了 4K 分辨率。
在显存方面,论文报告显示 PiD 的扩展性也优于传统 VAE decoder。标准 FLUX.1 VAE decoder 在 4K 高分辨率下直接爆掉了 H100 的 80G 显存,不得不采取 tiling 的工程 trick 来解码图像。而 PiD 的 4K decoding 下仅需约 22.5GB 峰值显存。
这意味着,PiD 并不是一个只能在小图上跑的概念验证,而是面向 2K、4K 生成服务的实际 decoder 组件。

从工程角度看,PiD 能把速度压到这么低,关键不只是换了一个 decoder,而是整套训练和推理流程的设计。
首先,它把高分辨率像素扩散模型先验作为基础,让模型一开始就拥有强像素生成能力。
其次,它通过轻量级适配器往主干注入潜在表征,sigma-aware gate 控制条件注入强度。推理时可以自然处理「还没完全去噪」的中间潜在表征。
最后,PiD 通过 DMD2 进行蒸馏,把原本多步采样的模型压缩为 4 步。论文结果显示,4 步的蒸馏版本不仅显著加速,视觉指标上还可以超过多步版本。
这也是 PiD 能在 210ms 级别完成 2K 解码的重要原因。
PiD 的意义,不只是让某个超分环节更快。
它实际上重新定义了图像生成系统里的 decoder:decoder 不再是被动的重建模块,而是主动的高分辨率生成模块。
这会改变高分辨率图像系统的设计方式。
过去,研究重点更多放在潜在扩散模型的主干网络:模型更大、训练数据更多。PiD 则提醒我们,最终解码的这一步同样是决定最终画质的关键战场。
当解码器具备生成能力后,基础模型不必承担所有像素细节;高分辨率纹理、锐化、细节补全,可以交给更专门的 pixel diffusion decoder 完成。
对于未来的图像生成、视频生成、world model 和闭环仿真系统,这种模块化思路都很有想象空间。
高精图像生成看起来像魔法,但拆开来看,它有一个非常工程化的问题:潜在表征里有了结构和语义之后,谁来负责把它变成真正清晰、锐利、细节丰富的像素?
PiD 给出的答案是:让 decoder 自己成为一个生成模型。
从 512×512 latent 直出 2048×2048 图像,从 2K 210ms 解码到 4K 扩展,从 FLUX、SD3 到 DINOv2、SigLIP,PiD 展示了一种新的高分辨率生成范式。
未来,当我们讨论 GPT-Image2 这类模型为什么能生成惊人细节时,答案也许不只在更强的 prompt 理解和更大的 diffusion backbone 中,还在这个长期被低估的「最后一公里」:
如何把潜在表征变成高质量像素。
而英伟达这篇 PiD,正是把这件事推到了台前。
PiD 论文第一作者 Yifan Lu 是多伦多大学的博士生,师从 Sanja Fidler 教授。同时也是 NVIDIA Spatial Intelligence Lab 的研究员,研究方向为 Generative model 和 3D Vision。

文章来自于"机器之心",作者 "机器之心"。



【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
