# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
6 月 15 日,斯坦福大学胡佛研究所和人类中心人工智能研究院(HAI)发布了一份白皮书,追踪 DeepSeek 七篇核心论文背后 356 名研究者的职业轨迹。

https://hoover-s3-website.s3.us-west-2.amazonaws.com/s3fs-public/research/docs/WhitePaper_Hoover_HAI_DeepSeek_FINAL%203.pdf
报告揭示的核心数据揭示了全新结论,80 位拥有美国机构经历的 DeepSeek 研究者,平均被引用 4108 次,是整个作者池中学术成就最高的群体。他们中的绝大多数,现在在中国。
13 位在美国深耕五年以上的长期研究者,累计在美国学术机构度过了 119 年以上的时间。其中 9 人最终回到了中国。在美国待得越久,回去的概率并没有变低。
一位研究者在美国的 Beth Israel Deaconess、洛克菲勒大学、MIT、贝勒医学院和加州大学圣迭戈分校辗转了 18 年,最后回到中国。
另一位在美国待了 28 年、拥有近 3 万次引用,留了下来,但这是少数。
这份报告由胡佛研究所技术政策加速器主任 Amy Zegart 和研究助理 Emerson Johnston 联合撰写,是 2025 年首份 DeepSeek 人才报告的年度更新。

Amy Zegart

Emerson Johnston
356 人,一份人才 X 光片
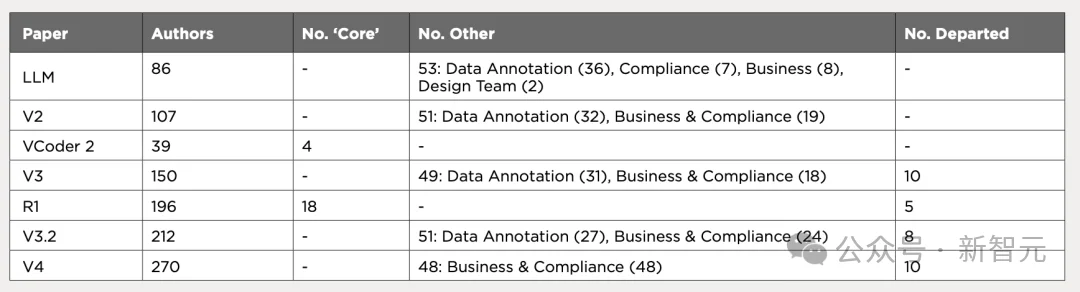
报告的分析范围从 2025 年的 5 篇论文扩展到 7 篇,新增了 DeepSeek V3.2(2025 年 12 月)和 V4(2026 年 4 月)。
作者池从 223 人增长到 356 人,其中 282 人可以通过学术数据库 OpenAlex 构建完整的机构履历档案,追溯时间最早可到 1989 年。
方法论上有一个重要调整。
这次分析只统计研究和工程团队成员,排除了数据标注、商务和合规人员。
按可比口径计算,团队一年内扩张了 57%,最近两篇论文在 14 个月内净增 141 名新贡献者。
同期离开的只有 33 人,招 4 个走 1 个。
团队的结构呈现出一种稳定的「双轨制」。
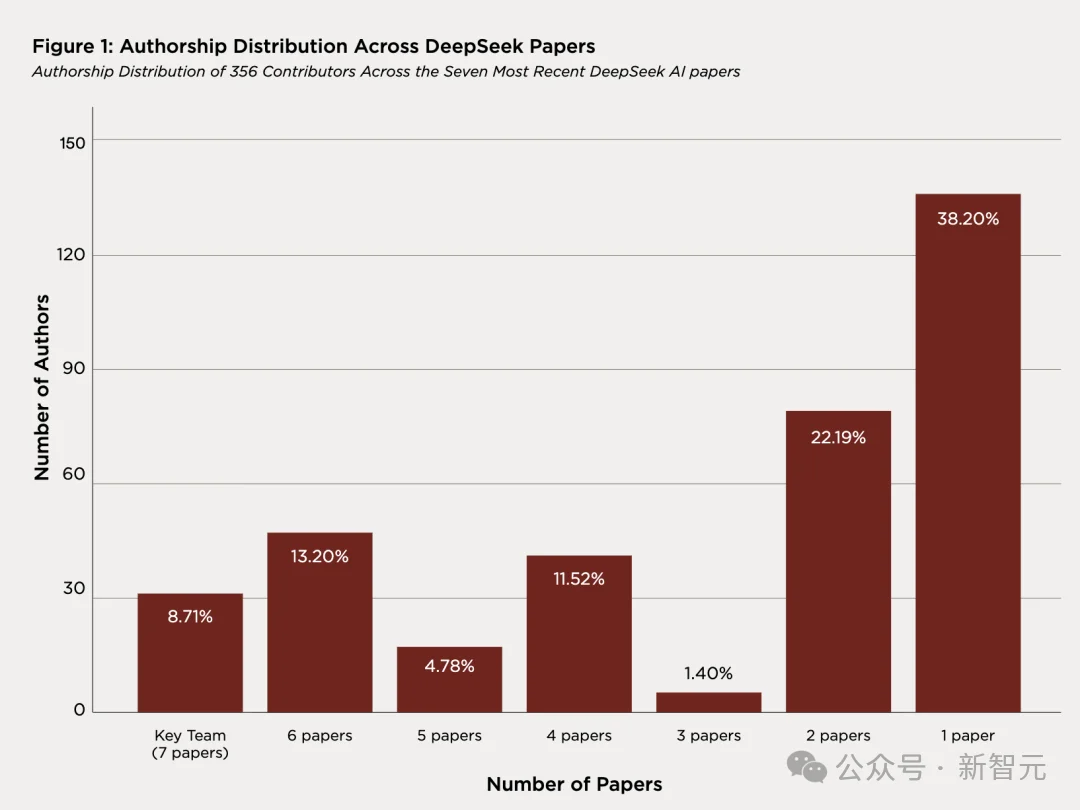
31 位研究者出现在全部七篇论文上,报告称之为「核心团队」(Key Team),占总人数的 8.7%。
47 人出现在六篇,这两个群体构成了一个「什么都参与」的稳定内核。
与之对应的是大量轮换式贡献者,136 人仅出现在一篇论文上(占 38.2%,2025 年时这个比例仅为 10.3%),79 人出现在两篇。
出现在三到五篇论文上的只有 63 人。
这种分布在 2025 和 2026 年保持了一致的形态。
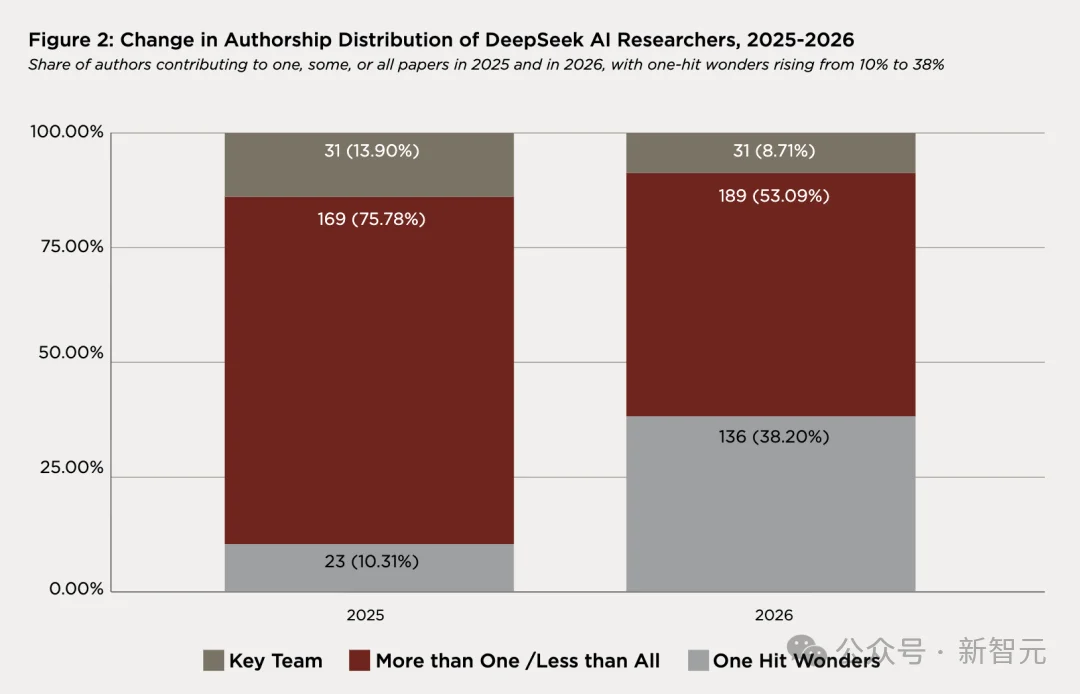
要么进入核心持续贡献,要么被借调进来解决特定问题后离开。
团队的增长完全来自轮换侧,核心始终是那 31 个人。
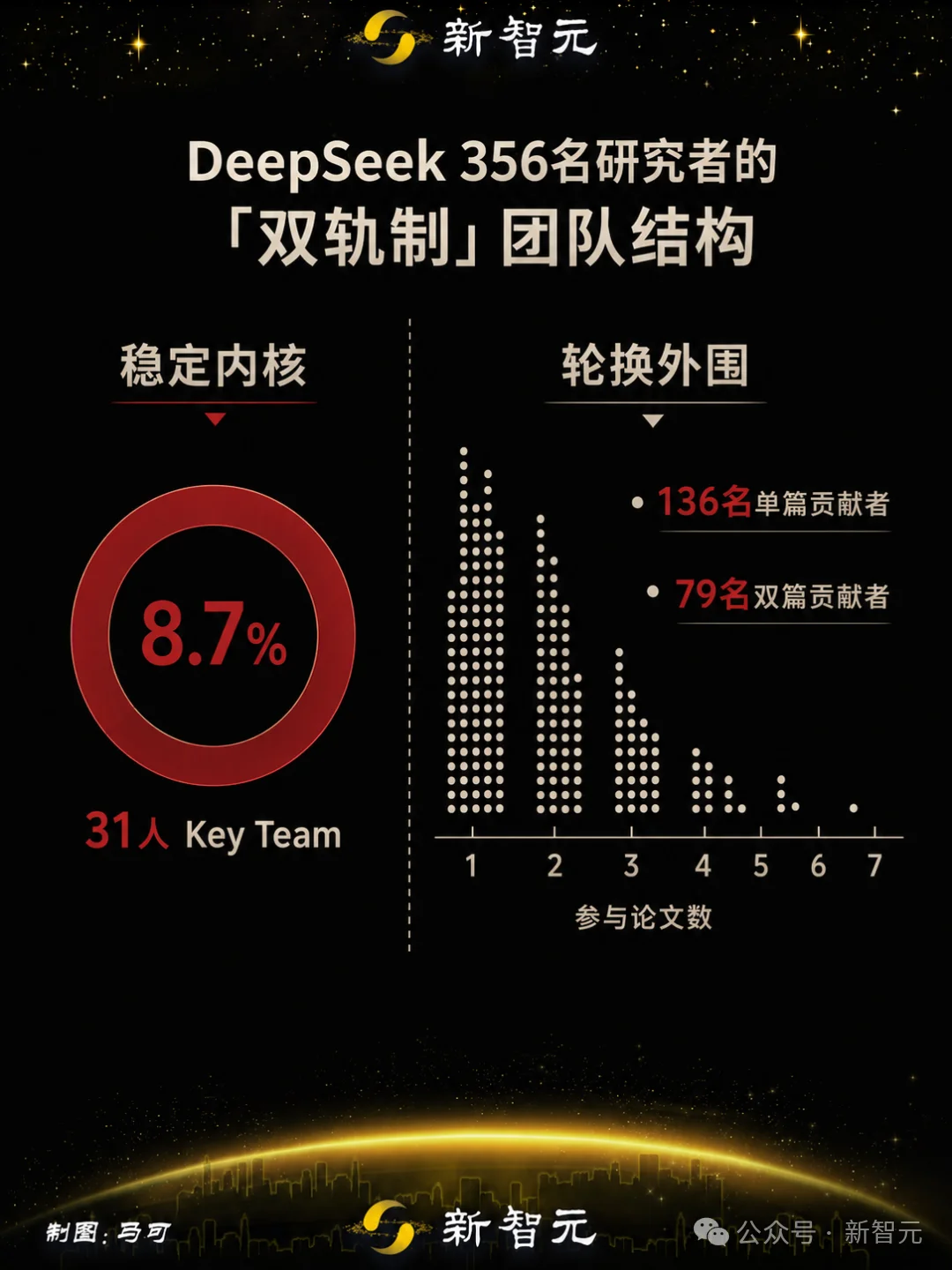
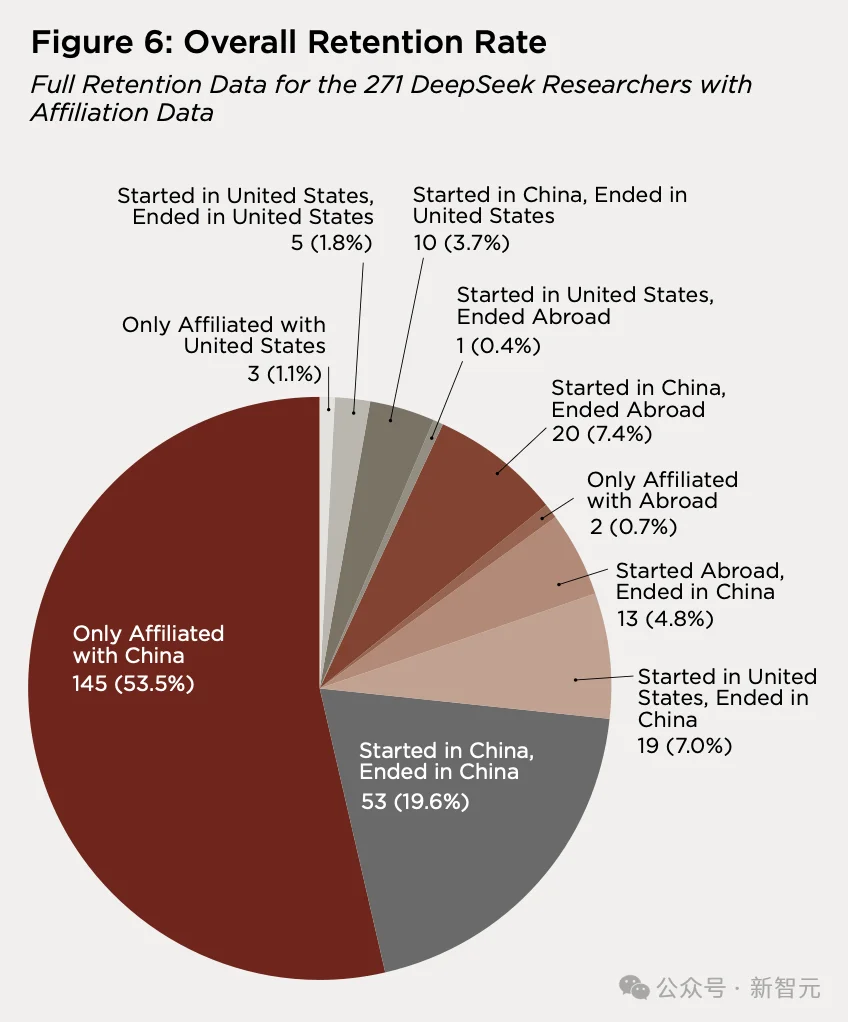
53.5%,从未离开中国
回到人才来源这个核心问题。
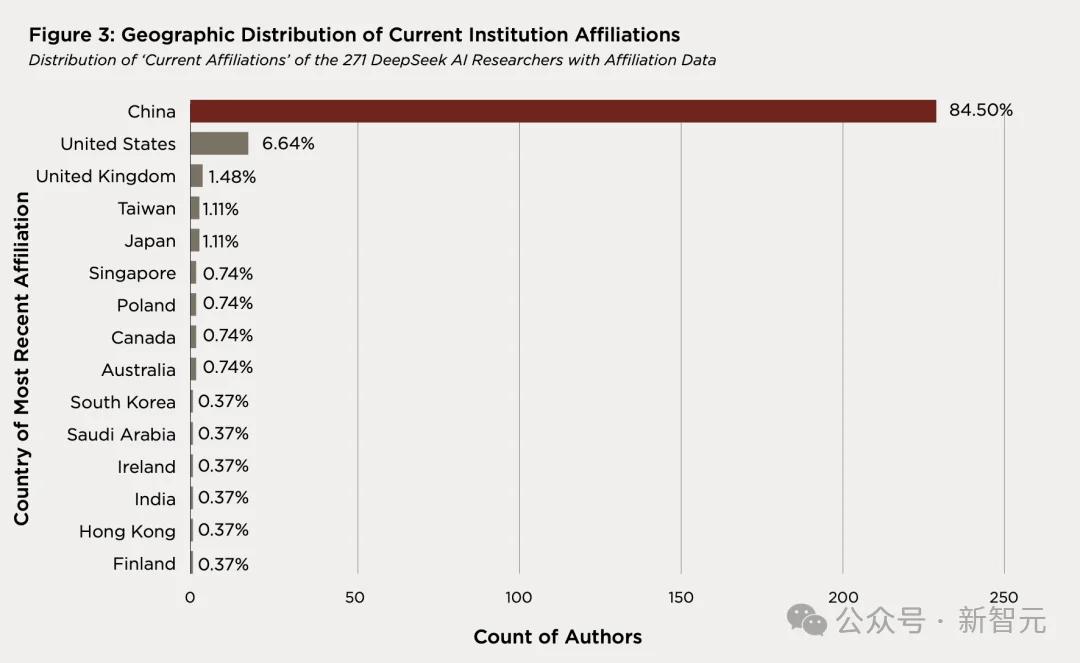
271 位有机构归属记录的研究者中,145 人(53.5%)在其整个有记录的职业生涯里,从未与任何中国以外的机构产生过关联。
没有在海外求学,没有在海外发表论文,没有在海外任职。
这个比例与 2025 年的 55.2%基本持平,说明它是一个稳定的结构性特征。
放到核心团队的维度看,冲击力更大。
31 位核心研究者中,有 10 人从未离开中国。
一个在推理基准测试上对标 OpenAI o1 的前沿模型(DeepSeek-R1),三分之一最核心的贡献者,完全由中国本土教育和研究体系培养。
支撑这个本土管道(pipeline)的机构网络也在快速扩张。

中国科学院及其 170 个下属机构组成的网络,关联研究者数量从去年的 53 人翻倍至 104 人,覆盖了整个作者池的 37%;
清华大学从 16 人增长到 46 人,接近 200% 的涨幅;
浙江大学从 8 到 25,北京大学从 21 到 29。
一些去年在 DeepSeek 还处于边缘的学校迅速崛起,东南大学从 1 人到 15 人,北航从 3 到 14,兰州大学从 0 到 10。
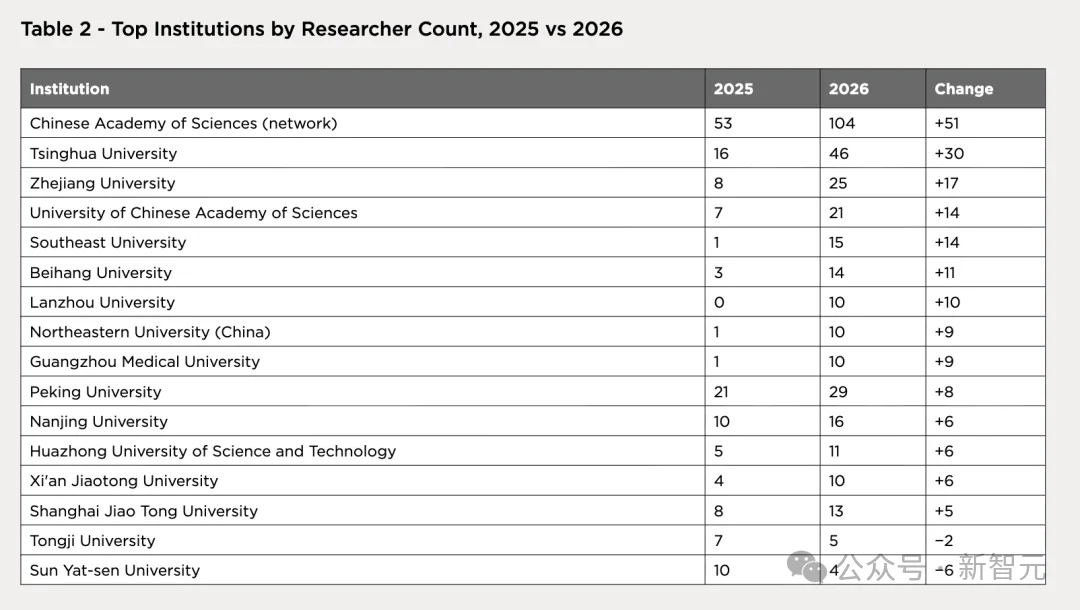
DeepSeek 的人才供给来自一个广泛的中国高校网络,远非少数精英院校的专利。
119 年,美国留不住的 AI 人才
报告对「美国经历」做了重大修正。
2025 年数据中,49 位有美国关联的研究者里,63.3%仅有一年美国经历。
新的扩展数据集,这个比例被进一步压低到了 35%。
近半数(48.8%,39 人)在美国待了 2 到 4 年,16.3%(13 人)超过五年。
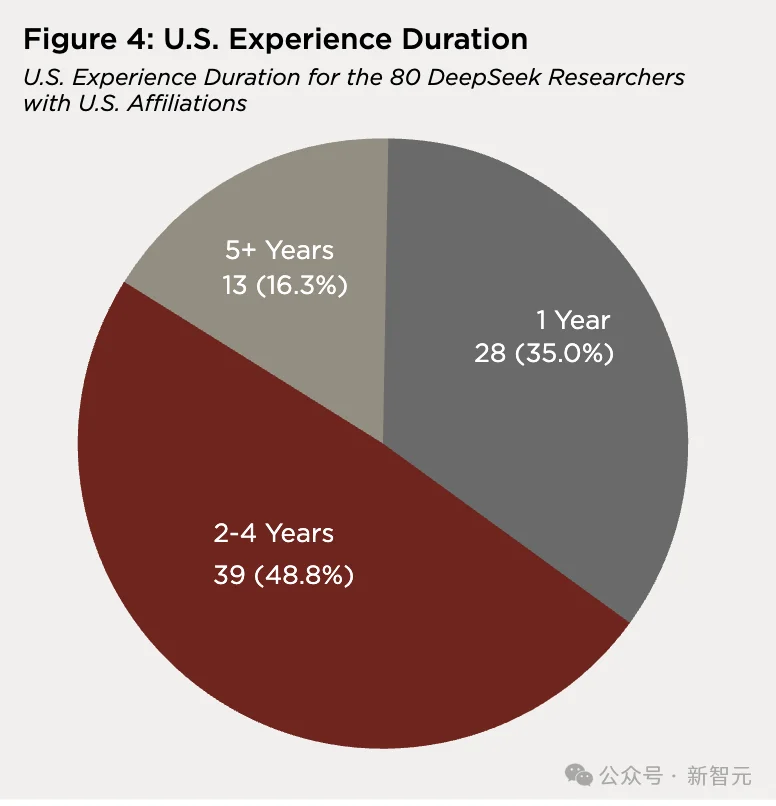
这批研究者在美国的经历更深、更长、更具塑造性。
80 位有任何美国机构经历的研究者中,最常见的流动模式是「中国→美国→中国」,占 38.8%。
第二大群体是「起点在美国,终点在中国」,占 23.8%。
只有 12.5%(10 人)走了「中国→美国→留在美国」的路径。
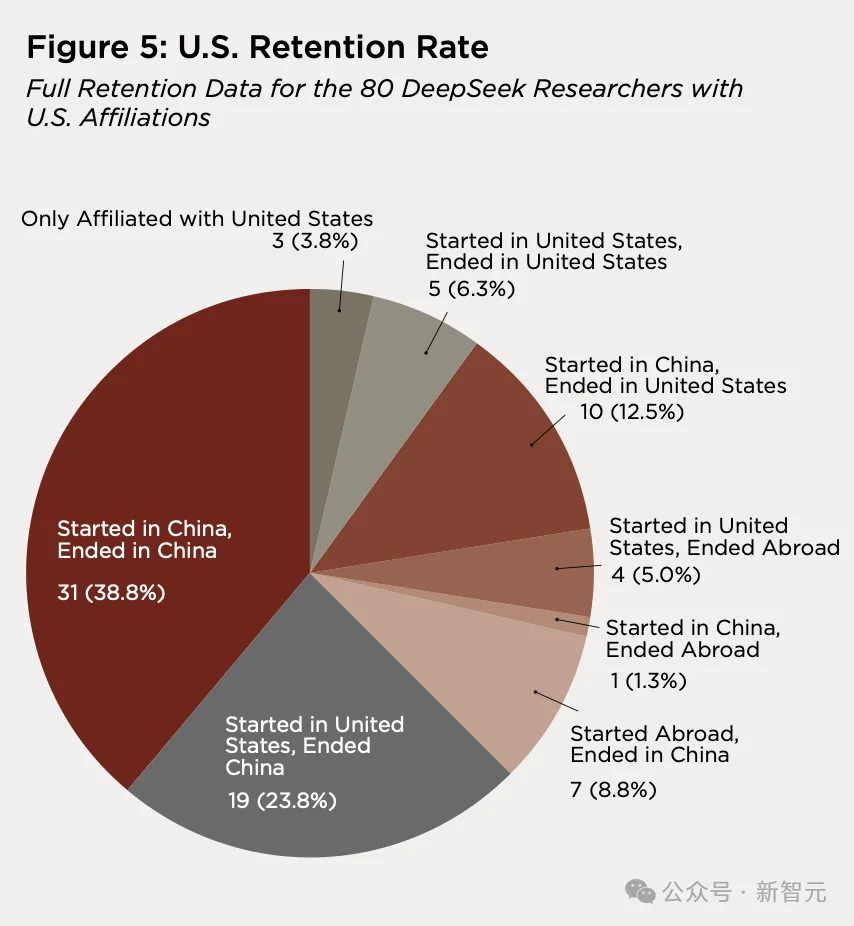
在整个有国际流动经历的群体中,70.3% 最终回到了中国。
13 位长期驻美研究者的职业轨迹尤其值得细看。
他们的路径很少是「去美国→待很久→回中国」的线性叙事。
九位在美国、英国、文莱、日本、瑞典等多个国家之间做了多次国际转换。
美国对他们而言是全球化职业生涯中的一个节点。
团队的迅速成熟
梁文锋在 2025 年初爆火时接受 36 氪采访称,核心技术岗大多由工作一两年的研究者填充,DeepSeek 招人看的是「热情和好奇心」。
到了如今,数据说明,DeepSeek 团队已迅速成长为相当成熟的研究团队。
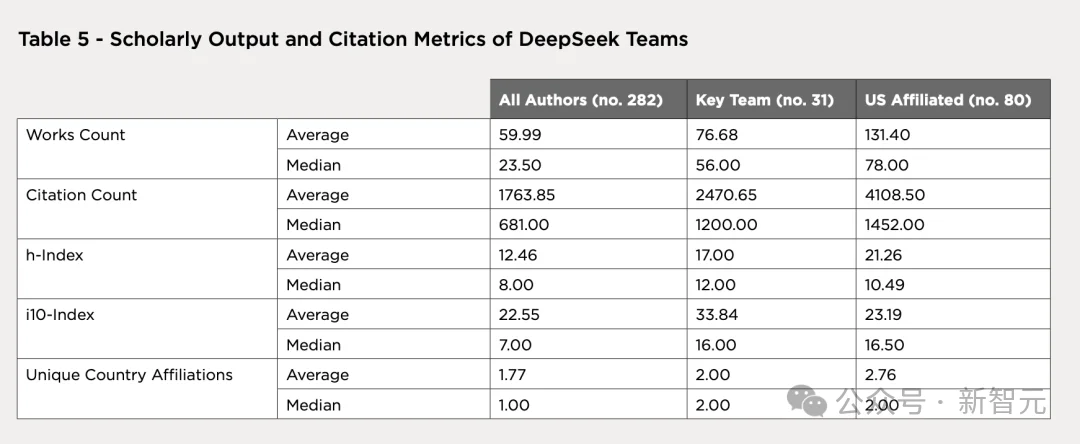
全体作者的中位引用量从 249 翻倍至 681,整条分布曲线上移。
核心团队的平均引用量从 1554 跃升至 2470,增长 59%,中位数从约 700 升至 1200。
这个跳升部分归因于 DeepSeek 自己的论文,R1、V3、V2 在 2025 年内被学术界大量引用,核心团队成员是所有这些论文的作者。
与美国头部实验室的对比更能说明问题。
OpenAI 的 894 名作者平均引用量 2481.5,看上去跟 DeepSeek 相当。
但 OpenAI 的中位数只有 100.5,均值是中位数的 25 倍。
这种极端的头重脚轻说明少数超级明星拉高了整体均值。
OpenAI 的中位 h 指数只有 2。
Anthropic 和谷歌的中位引用量分别只有均值的 15%和 20%。
DeepSeek 的中位引用量是均值的 35%。
学术影响力在团队内部的分布更加均匀,整支队伍的平均水平更高,对少数明星的依赖更低。
两个问题,一场辩论
报告最终将美国面临的困境拆解为两个独立的挑战。
第一是留存。
80 位经美国体系训练的研究者是 DeepSeek 全部作者中学术成就最高的群体,平均引用 4108 次,中位 h 指数 16.5。
他们带着在美国研究体系中积累的方法、人脉和学术资本回到了中国。
美国的移民制度在加速这个过程,一位中国研究者今天申请职业移民绿卡,排期接近五年,而且在变长。
2025 年 9 月新增的每份 H-1B 申请 10 万美元费用和高薪优先抽签制度,把博士后和刚毕业的博士推到了队伍最后面。
报告在措辞上也为美国挽尊了,称不应假设中国研究者离开美国是因为想回去,很多人可能是因为签证制度让留下来太难、太贵、太不确定。
实际原因很可能是复杂得多的。
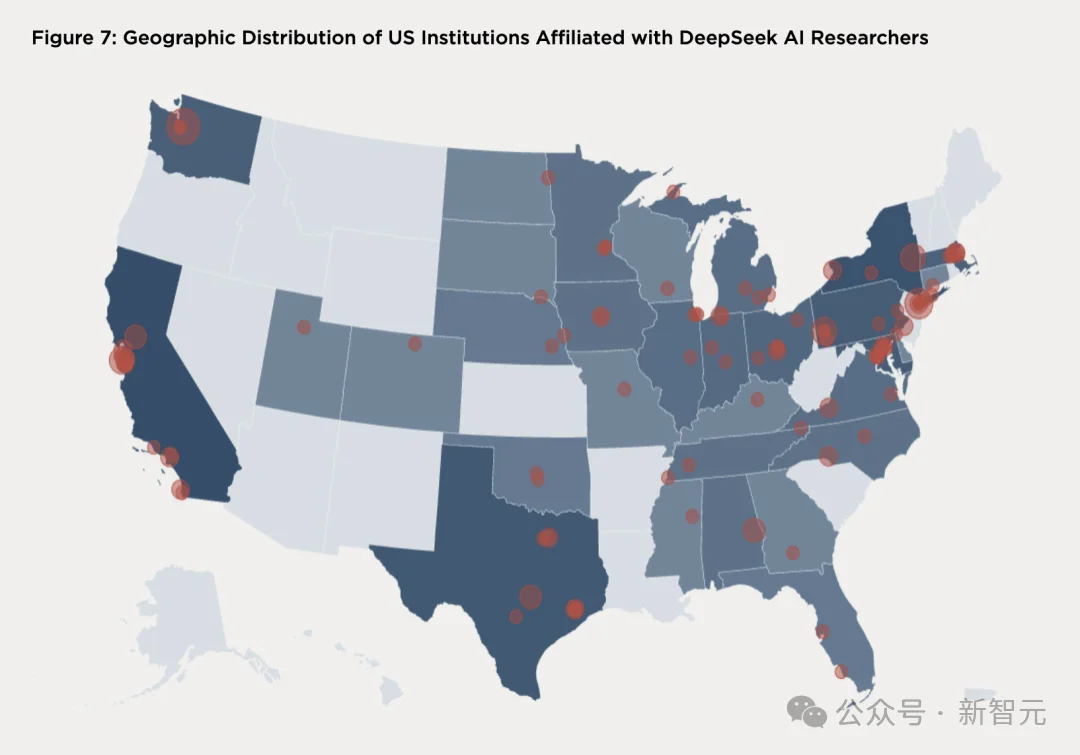
DeepSeek 研究者关联的美国机构地理分布图
第二个挑战更棘手:53.5%的研究者从未离开中国,任何关于签证和准入的政策讨论都触及不到他们。
10 位核心团队成员在没有任何美国或国际研究经历的情况下,参与构建了一个前沿推理模型。
这条本土供应链的存在,让「通过限制人才流动来维持技术优势」的策略失去了一半靶子。
已经随研究者转移的知识无法通过事后收紧出口管制来追回。
限制未来的准入只解决了一个问题,另一个美国需要迎接的挑战,就是中国本土管道的独立产出能力。
报告指向的方向是美国自身的 K-12 和理工科高等教育改革,但也同时承认这是一个更长周期的工程。
两个问题需要完全不同的政策工具。目前美国内部的辩论大多只围绕第一个展开。
通向 AGI 的人才底盘
行业主流叙事在讨论 AGI 竞赛时,焦点通常集中在算力和数据上。
这份报告提供了另一个维度的坐标系。
DeepSeek 从第一篇 LLM 论文到 V4,只用了两年零三个月。
模型参数从 67B 膨胀到 1.6T,支持的上下文长度从基础水平扩展到 100 万 Token,研发团队从 215 人扩张到 356 人。
V3.2 的高算力变体已经在 2025 年国际数学奥林匹克(IMO)和国际信息学奥林匹克(OI)上拿到了金牌级表现。
V4 系列在百万 Token 上下文场景下的推理效率,单 Token 推理计算量只有 V3.2 的 27%,KV cache 只有 10%。
如果 AGI 竞赛的关键变量包含「谁能最快组建和维持一支前沿研究团队」,中国已经拿出了证据,它拥有一条可以独立运转的人才供应链。
这条供应链在过去一年里把清华的贡献者人数从 16 推到 46,把中科院网络的覆盖面翻了一倍,同时把团队规模扩大了 57%,核心班底一人未丢。
能独立产出前沿模型贡献者的人才体系,需要数十年的积累。
这份报告得出的结论是:中国的积累已经完成,正在进入产出加速期。
参考资料:
https://hoover-s3-website.s3.us-west-2.amazonaws.com/s3fs-public/research/docs/WhitePaper_Hoover_HAI_DeepSeek_FINAL%203.pdf
文章来自于微信公众号 “新智元”,作者 “新智元”



