# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI Agent 正在重塑软件开发。写代码、修 bug,它的能力肉眼可见地往上涨。但软件开发,从来不止 "写代码" 这一件事。装环境、配依赖、部署服务、编排容器、管理云资源、处理安全策略,这些 "让软件活起来" 的脏活累活,才是真实开发的大头。而它们,几乎都发生在同一个地方:终端。
终端是工程师干这一切的主战场。几十年下来,它沉淀了人类最密集、最真实的工程操作轨迹。每一次部署,每一次排障,每一次环境搭建,都是一段被真实意图驱动的操作序列。可这批真实人类的终端操作轨迹,恰恰是 Agent 测评里被忽视最久的一座金矿。
为了把这批轨迹真正用起来,来自伦敦大学学院(UCL)、南京大学、腾讯的研究团队推出了 TerminalWorld,首个完全基于真实人类终端轨迹、自动构建且能持续更新的终端 Agent 评测基准。
它从八万余条开发者自愿上传的真实录像出发,自动逆向工程出可执行、可验证的评测任务,最终构建出 1,530 个真实终端任务,覆盖 18 个真实工作流类别、1,280 个独特命令工具。在此之上对前沿大模型与主流 Agent 框架的评测显示,真实终端工作流对当前系统依然极具挑战,且专家基准上的高分难以迁移到真实场景。

TerminalWorld 网站主页
TerminalWorld 的出发点,来自一个朴素的直觉:机器人领域很早就想透了,想让机器学会一项任务,最好的参照系就是人类自己怎么做,于是他们不惜代价去捕捉、学习人类的真实操作轨迹。
那软件工程呢?开发者在终端里敲下的每一条命令,怎么搭起一个 Kubernetes 集群、怎么配通一条 CI/CD 流水线、怎么揪出一个容器部署的报错,同样是人类工程经验最密集的结晶。可在测评这件事上,这批数据几乎从没被正经用过。
为什么会这样?因为现有的终端 Agent 基准(如 Terminal-Bench),几乎都在做同一件事:让领域专家坐下来,手工出题。而这条路有两个被集体忽视的盲区。
盲区一,题目不够真实。专家出题为了拉开难度,难免偏爱刁钻的、对抗性的谜题,可这类题和工程师每天真正面对的工作流之间,隔着一道隐形的墙。榜单上的高分,未必换得来真实世界里的 "会干活"。
盲区二,基准会过时。工具在变,命令在变,工作流也在变,可手工基准从出题那天起就被钉死了,成了一张静态快照。当模型早已用上最新的工具,旧基准却还在拿过时的题考它,自然测不出它真正的能力。
可答案其实一直静静躺在那儿:海量的人类真实终端行为轨迹。与其让专家绞尽脑汁,不如让真实世界自己来出题。
asciinema 网站平台
asciinema(https://asciinema.org/)是一个开发者自愿分享终端会话录像的公开平台。研究团队从中收集了 80,870 条真实终端操作录像。每一条,都是某个真实的开发者,在某个真实的时刻,干完了一件真实的事。没有出题人,没有人为设计的难度,只有最原始的人类操作。
和录屏视频不同,asciinema 的终端画面不是录下来的像素,而是由一份底层的结构化文本实时渲染出来的:会话被记成带时间戳的文件,逐条保存用户的输入和终端的输出,再据此还原出屏幕画面,也能直接导出干净的文本转录本。这意味着,一条录像里既写着 "人做了什么",也完整保留着 "系统怎么回应"。对机器来说,这是近乎理想的原材料,命令和结果本就以文本承载,全程不需要任何视觉模型去解析画面。
也正因如此,这批录像构成了一个独特的语料库:由真实开发者亲自贡献和验证、随时间不断演化,记录的全是经过实践检验的真实工作流。TerminalWorld 要做的,说穿了就是一次大规模逆向工程,从一段人类操作录像,反推出一道能自动评分的题目。
但说起来轻巧,做起来没这么简单,原始录像和一道能打分的题目之间,还隔着好几道难关。
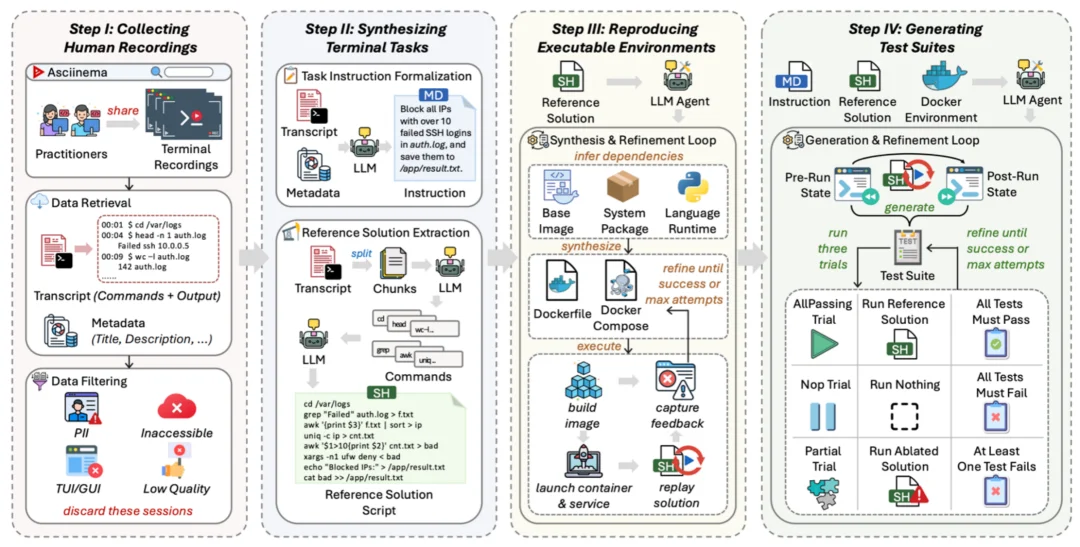
TerminalWorld 数据引擎总览
真实录像是为 "给人看" 而生的,不是为 "机器评测" 而生的。横在原始录像和一道合格评测题之间的,主要是三道难关:首先,原始录像很脏,得先从噪声里认出 "人到底想干什么";其次,录像只记了命令,没记下命令依赖的系统环境,得把它重新搭出来;最后,录像自己不带判分标准,得想办法判断一道题做没做对。TerminalWorld 用一条四阶段流水线,把这些难关逐一拆解。
第一步,收集与过滤。从 8 万余条原始录像出发,依次做隐私安全过滤(剔除敏感信息或危险命令)、纯 CLI 筛选(排除 vim 这类图形界面交互)、可复现性与时长筛选,最后用大模型给录像质量打分。一路筛下来,留下 9,492 条高质量录像。
第二步,合成终端任务。借助 asciinema 提供的每段录像的文本转录本,大模型无需视觉解析,直接从录像里提炼出两样东西:一份只说目标、不说步骤的任务指令,和一份干净可跑的参考解答。
第三步,复现可执行环境。研究团队让一个大模型 Agent 逆向推断依赖、构建 Docker 镜像、起容器、回放参考解答,再拿运行时的报错当反馈反复修,直到脚本完整跑通。这一关为 5,035 个任务复现出了环境。
第四步,生成测试。Agent 给执行前后的文件系统各拍一张快照,据此生成跟真实终态对齐的测试,再用三道关卡反复校准:
只有同时通过三道关卡的任务才会被收录。这一步最终淬炼出 1,530 个 经自动验证的任务,作为完整的 TerminalWorld 基准。
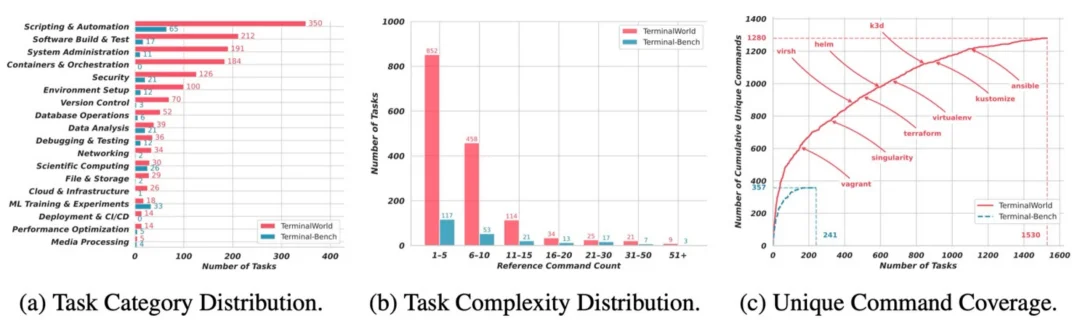
TerminalWorld 与 Terminal-Bench 的统计对比
TerminalWorld 包含 1,530 个真实世界终端任务,考的不是抽象的编程能力,而是开发者真实工作的横截面:系统管理、容器编排、云基础设施、安全、CI/CD,整整 18 个真实场景。其中容器编排、云基础设施、CI/CD 这些天天打交道的活儿,恰恰是过往专家基准里严重缺席的部分。
更能体现 "真实" 的是它的难度跨度:既有几条命令就能搞定的日常小操作,也有超过 50 步的复杂工作流。这种参差,本就是真实开发的常态,而非专家为拉开区分度刻意设计的难度阶梯。它还覆盖 1,280 个不同的命令工具,其中高达 91% 在 Terminal-Bench 里压根没出现过,从环境管理(vagrant、virtualenv)到基础设施编排(terraform、ansible)再到容器调度(k3d、kustomize),真实还原了开发者工具箱的丰富程度。
在这 1,530 个任务之上,研究团队又精挑细选、逐条人工复核出 200 个,组成质量最高的 Verified 子集,专门用来给前沿模型和 Agent 当 "硬核考场"。
最关键的一点是:整套数据引擎全自动,而真实录像还在源源不断地涌进来。这意味着 TerminalWorld 不是一张拍完就过期的快照,而是一个会生长的 "活性基准"(Living Benchmark),跟着开发者的真实实践一起更新。真实、可扩展,是它从设计之初就刻进去的底色,这是任何手工基准都做不到的事。
研究团队在 Verified 子集上测评了 8 个前沿大模型和 6 种主流 Agent 框架,得到几个值得玩味的发现。
发现一:最强模型,也只是勉强及格。所有模型的通过率都卡在 49.0% 到 62.5% 之间,平均只有 54.8%,即便表现最好的 Claude Opus 4.7,也在超过三分之一的任务上栽了跟头。真实世界的终端工作流,对今天最顶尖的模型来说,依然是块难啃的骨头。值得一提的是,开源模型打得相当漂亮:Kimi K2.6、GLM 5.1 逼近甚至反超部分闭源模型,平均成本却只有 17 美元,不到闭源模型(约 71 美元)的零头,性价比高出 4 到 8 倍。
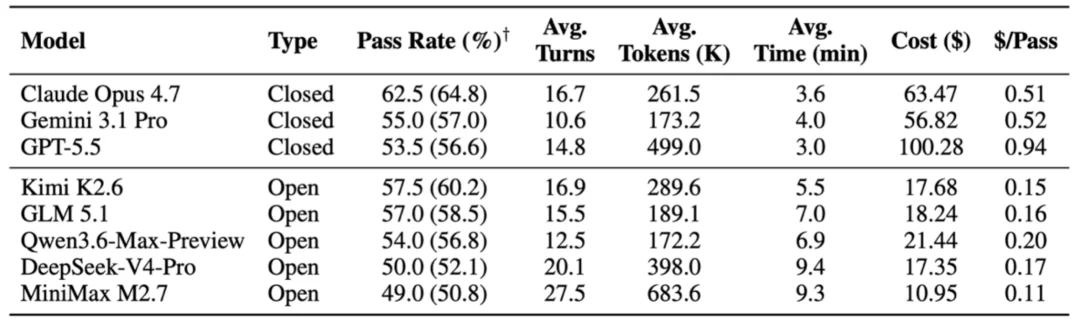
各前沿大模型在 TerminalWorld-Verified 上的通过率与成本
发现二:烧更多算力,反而错得更狠。任务成功率和消耗的轮数(相关系数 - 0.49)、token 量(-0.62)都是负相关,花得越多,往往做得越差。失败的尝试尤其烧钱:平均吃掉 3.3 倍 token、1.4 倍时间,数量只占 43%,却烧掉 63% 的总成本。真实环境动作空间开放、处处是细节陷阱,一旦缺了靠谱的规划和 "该收手了" 的判断,Agent 就只会在错误的方向上越钻越深,钱花光了,答案还没找到。
发现三:能力严重偏科,没有全能选手。模型在环境配置(平均 87.5%)、软件构建与测试(78.1%)上相当能打,可一碰到性能优化(28.1%)、脚本自动化(39.1%)、调试与测试(39.3%),就集体拉胯。而且没有哪个模型全能:Claude Opus 4.7 在云基础设施(83.3%)遥遥领先,却在脚本自动化上被 Kimi K2.6 反超(37.5% vs 46.9%)。这种参差,恰恰是 TerminalWorld 宽覆盖照出来的盲区,当前模型的工具能力,还远没到 "什么活都接得住" 的程度。
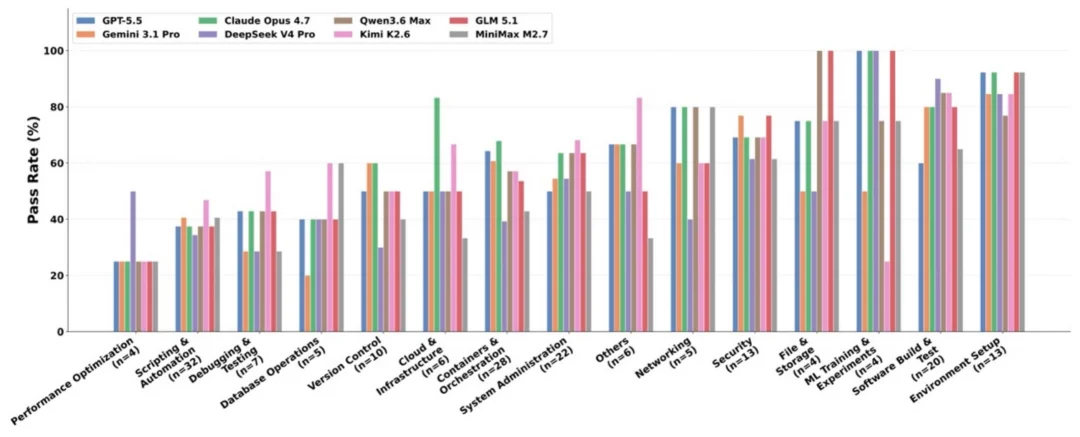
各模型在不同任务类别上的通过率,没有任何一个模型在所有类别上领先
发现四:换个考场,专家榜单的高分就崩了。把每个模型在 Terminal-Bench 和 TerminalWorld 上的分数摆到一起,发现两者的相关性低到只有 0.20。在 Terminal-Bench 上模型能拿 57% 到 82.7%,到 TerminalWorld 却全员跌进 49% 到 62.5%,排名也被狠狠重排。这说明,专家基准上的高分会高估模型在真实世界里的真本事,两类基准考的,根本不是同一种能力。
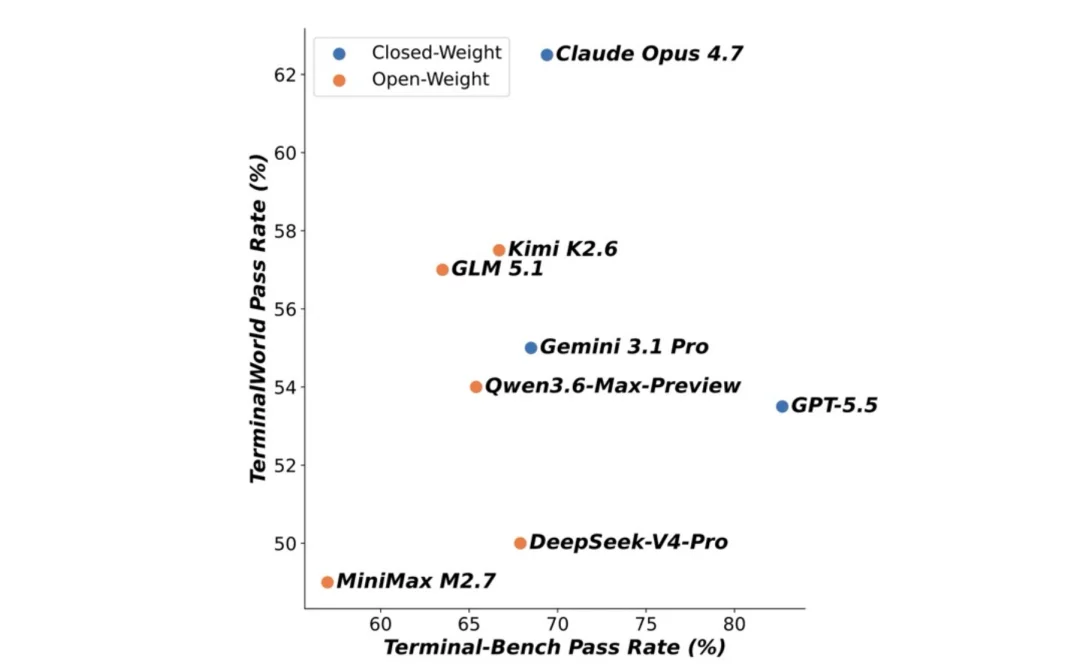
Terminal-Bench 得分 vs. TerminalWorld-Verified 得分,相关性低至 0.20
发现五:同一道题,Agent 偏不走人类的路。每道题虽源自真实人类录像,但 Agent 解题的命令路径和人类的重叠度中位数只有 21.4%。比如一个从 pcap 提取 HTTP 基础认证凭据的任务,人类用 ettercap 重放解析,Agent 却用 tshark 配 Python 直接解析;一个磁盘镜像修改任务,人类手动用 mknod 创建设备节点,Agent 则直接上 fdisk、mkfs.ext4、mount。两例里双方命令集甚至完全不重叠,但只看结果的验证器照样都判对。换句话说,面对同一个目标,Agent 经常另辟蹊径,照样把活干成。
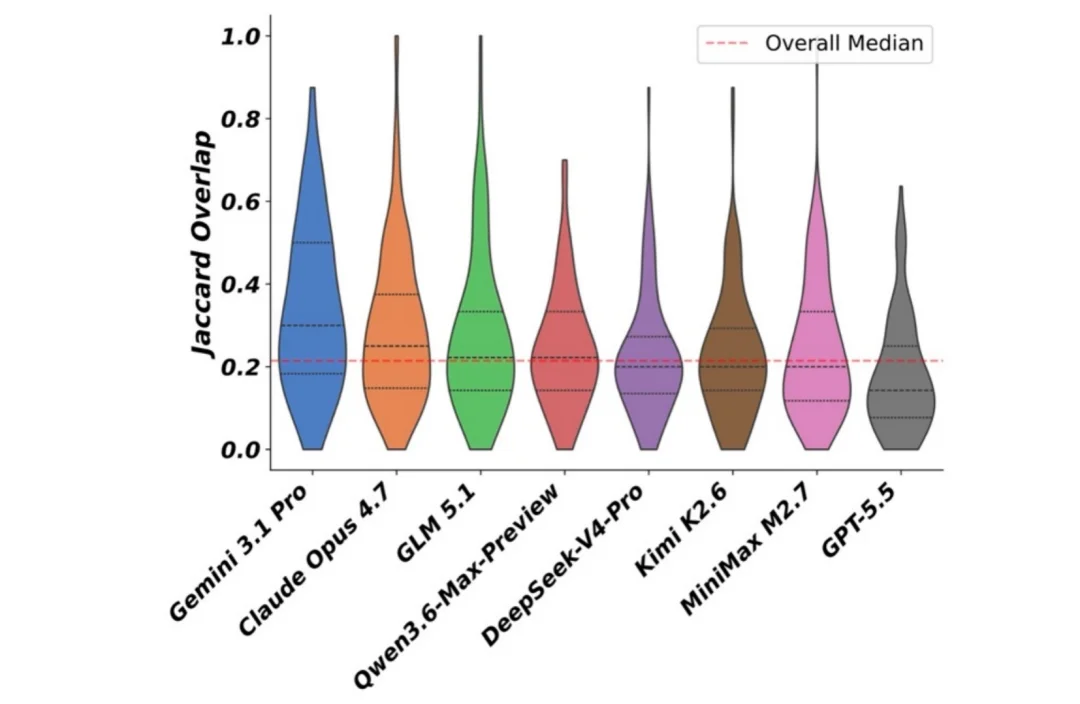
Agent 与人类命令集的重叠度分布,中位数仅 21.4%
TerminalWorld 想讲的,其实是一件朴素的事:测评 AI 最好的原材料,不在专家的题库里,而在人类真实干过的活里。专家再聪明,也想象不尽真实世界的全部模样,榜单上的高分,量不出一个 Agent 在真实终端里到底靠不靠谱。
终端,是软件开发里最朴素、也最关键的一环。一个 Agent 能不能在真实的终端工作流里站稳脚跟,才是它能不能真正走进开发者日常的试金石。说到底,最好的考题,人类早就写好了,就写在他们的终端里。
TerminalWorld 现已全面开源,也欢迎社区持续贡献新的录像与评测结果,一起把终端 Agent 的测评推向更真实、更可扩展的明天。
参考资料:
Zhaoyang Chu et al., TerminalWorld: Benchmarking Agents on Real-World Terminal Tasks, arXiv:2605.22535, 2026.
文章来自于"机器之心",作者 "储朝阳"。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
