# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型推理能力越来越强,但答案对了,思考过程就一定好吗?
就像是同一道数学题,两个学生都做对了。
一个步骤干净、推导紧凑、思路顺畅;另一个绕了大段无关推导,跳过关键步骤,最后却也凑出了正确答案。
只看结果,两份答卷都对。但若要选一份更值得学习的解题过程,显然是前者。
大模型推理也面临类似问题。
模型在给出最终回答前,往往会生成一段动辄数千甚至上万token的reasoning trace:里面有探索、反思、修正,也有重复打转、跳步,以及看似完整却经不起推敲的“伪证”。
可绝大多数评测和奖励信号,只看最终答案对不对,这就悄悄抹平了“思考过程的高下”。
什么样的思考过程算好?一段自由形式的推理链,如何被稳定评估?这种评估信号,又能否反过来帮助模型学会更好的推理方式?
针对这一问题,来自上海人工智能实验室、上海交通大学、香港中文大学的研究团队提出了TRM(Thinking Reward Model):
不再只看大模型“答没答对”,而是直接给它的推理过程打分,把“想得好”变成可度量、可训练、可优化的能力。

具体来说,团队提出了一套统一框架:用ME² principle刻画推理质量,用DAG-based pairwise evaluation还原推理结构,并在此之上训练Thinking Reward Model,把“推理质量”从主观感受变成可复用的奖励信号。
过去很多大模型评测,主要看最终答案是否正确。对于问答题、代码题来说,这种方式很直接:答对得分,答错不得分。
但对于推理模型而言,只看答案会漏掉一个关键问题:模型是怎么得到这个答案的?
同样答对一道题,一个模型可能沿主线步步推进,另一个则反复重启同一思路、做大量无效检查、甚至用错误步骤撑起正确结论。
这些低质量推理不仅推高生成成本,也让模型在题目条件变化时更容易出错。
在强化学习训练里,这一问题更明显。如果奖励只看最终答案,那么所有答对的推理链都会得到同样反馈。但答案之外,还需要进一步区分:哪条推理链更清楚、更紧凑、更值得模型学习。这正是TRM关注的问题。
TRM整体框架如下:(a) 提出ME² principle, (b) 用DAG抽象复杂推理结构, (c) 训练Thinking Reward Model,并将其用于Test-Time Scaling和RL。
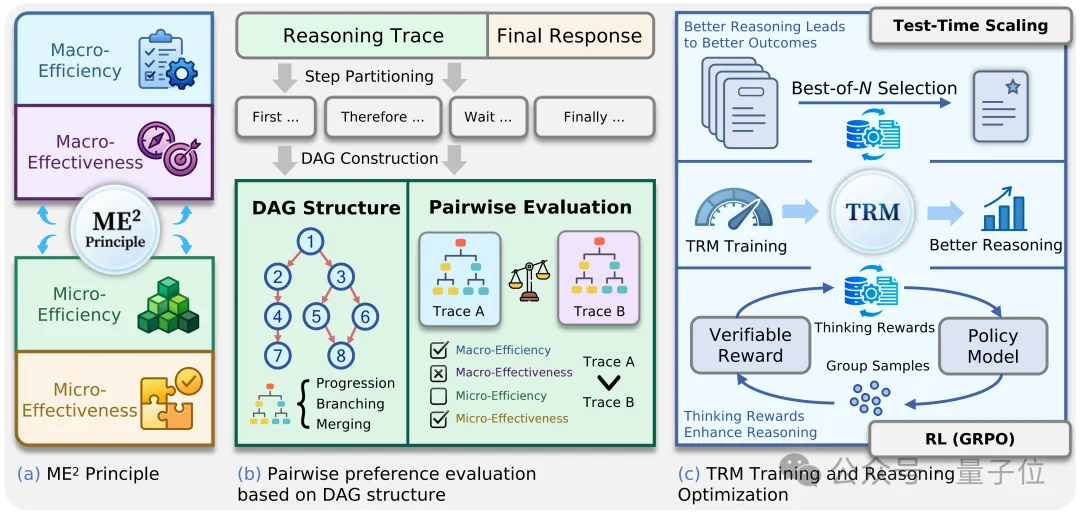
要评估推理质量,首先要说清楚“好”到底指什么。
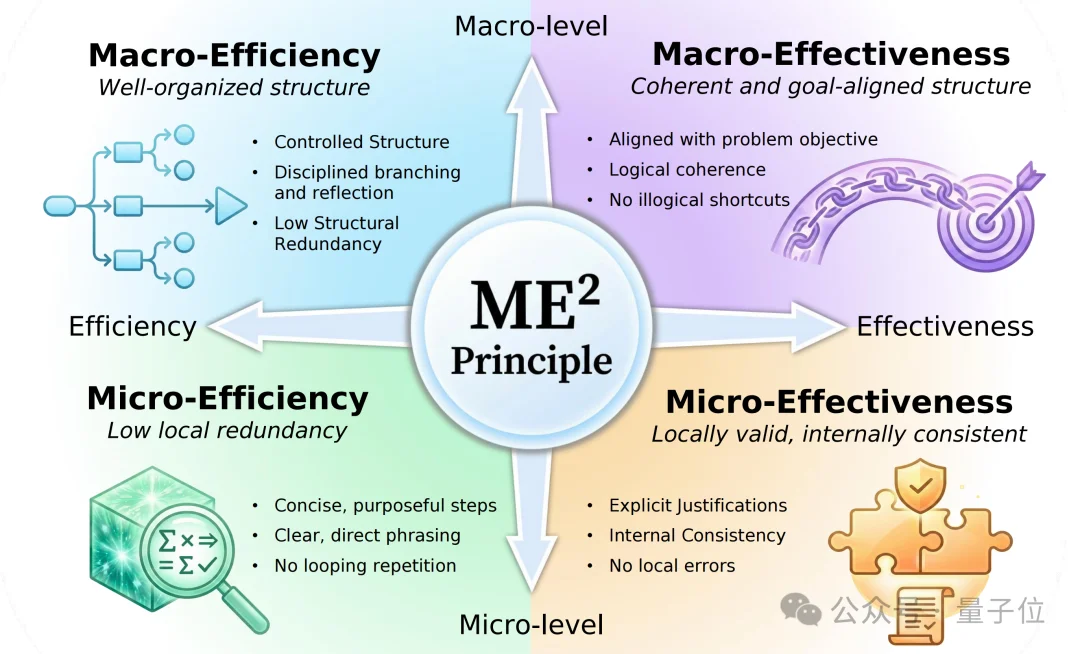
论文沿两条正交轴拆解推理质量:粒度上分macro(整体结构)和micro(单步内容);目标上分efficiency(高效)和effectiveness(有效)。两两组合得到四个维度:
-Macro-Efficiency:整体结构是否高效。好的推理链会沿着必要分支推进,避免在同一条思路上反复重启,也不会做过多无效检查。
-Macro-Effectiveness:整体结构是否有效。推理主线应始终围绕问题目标展开,分支之间关系清楚,关键论证能够前后接上。
-Micro-Efficiency:单步表达是否简洁。每一步最好都有明确作用,比如计算、验证、排除或归纳,少写不影响结论的重复内容。
-Micro-Effectiveness:单步内容是否正确。局部计算、符号使用和前后结论需要自洽,不能用错误步骤支撑正确答案。
这四个维度把“哪条推理更好”分解成可标注、可比较、可训练的信号,构成后续整套评估和优化流程的基石。
模型推理链通常是一长串自然语言文本,表面上按顺序展开,但真实推理不一定直线前进。它可能先推进一条主线,中途展开几个分支,排除一些可能性,再把有效分支合并回来。
更麻烦的是,长文本里有大量局部细节,容易淹没真正重要的结构信号。如果不把推理结构显式拆出来,评估模型就很难稳定区分它们。
因此,论文把自由形式的推理链抽象为有向无环图(DAG)。具体来说,先把原始文本切成一系列原子步骤,把每个步骤作为一个节点,再按照语义依赖关系连边。这样一来,推理链中的progression(线性推进)、branching(分支探索)和merging(分支合并)就能清楚呈现出来。
为此,论文把任意推理链抽象为有向无环图(DAG),并将这一过程拆成三步:
1.Step Partitioning:先按段落做粗切分,再统计大量轨迹中高频起始词作为更稳定的分隔符,得到一致、有语义意义的步骤边界。2.Reasoning Structuring:按时间顺序遍历每个推理步骤,用大模型分配其语义父节点,逐步构建边;再把完全线性的相邻节点合并为超节点,得到紧凑的DAG,清晰呈现progression(线性推进)、branching(分支探索)和merging(分支合并)这样的复杂结构。3.Pairwise Evaluation:根据ME² principle构造语义抽象,再让评估模型基于这些抽象给出两条推理链的相对偏好。Macro和Micro两种粒度分别对应不同的抽象方式,覆盖ME² principle四个维度。
这样,评估模型就不必只盯着一整段长文本,而是可以沿着推理结构看:主线是否清楚,分支是否必要,局部步骤是否简洁、正确。这样得到的判断,也比直接看原文更稳定。

基于上述评估框架,研究团队构建了TRM-Preference数据集。对于每个问题,研究者先用多个开源推理模型生成候选推理链,再通过规则验证器筛掉答案错误的轨迹,只保留最终答案正确的样本。
这样一来,后续比较的重点就从“答案对不对”,转向“答案都对时,哪条推理链更好”。
随后,论文用DeepSeek-V3.2在ME²四个维度上对DAG进行成对评估。为减少位置偏差,评估会在正反两种呈现顺序下重复进行,只保留判断稳定且非平局的偏好标签。最终得到103K训练偏好对+1.5K验证偏好对,构成TRM-Preference数据集。
TRM以Llama-3.1-8B-Instruct为初始化,把语言建模头换成标量value head。在TRM-Preference上训练完成后,TRM会为每条推理链输出一个标量分数:分数越高,越符合ME²对高质量推理的定义。
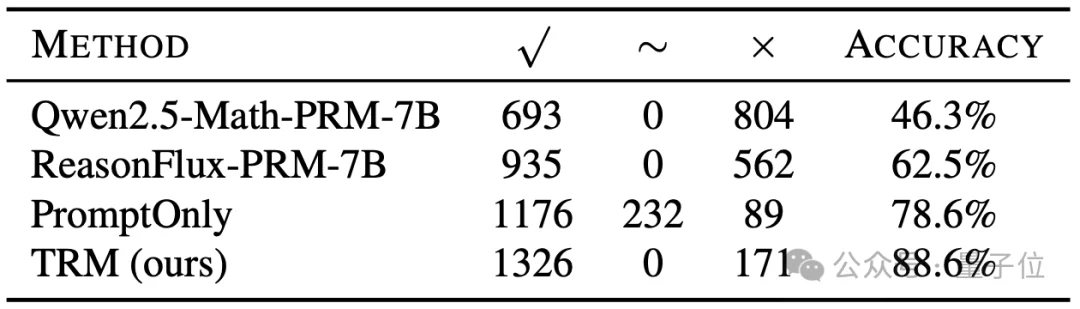
在验证集上,TRM取得88.6%的准确率,明显优于两个代表性PRM基线。
TRM评估的是推理链质量,但这种信号也能反过来提高最终答案的准确率。
测试时,可以把TRM用在Best-of-N selection中:让模型针对同一个问题生成多条候选推理链,再由TRM选出质量最高的一条。实验显示,随着N增大,TRM选出的结果能够带来更高的最终准确率。

在训练阶段,TRM也能为强化学习提供更细粒度的奖励信号。
传统RLVR通常只看答案对错,而在加入TRM后,模型可以在答对的基础上继续学习更清晰、更高效的推理方式。

“门控”的关键在于:只有答案正确时,TRM才参与reward shaping,错误轨迹的reward始终为0,避免模型从错误轨迹里学到坏习惯。
实验结果显示,这种思路在多个模型和任务上都带来了性能提升。
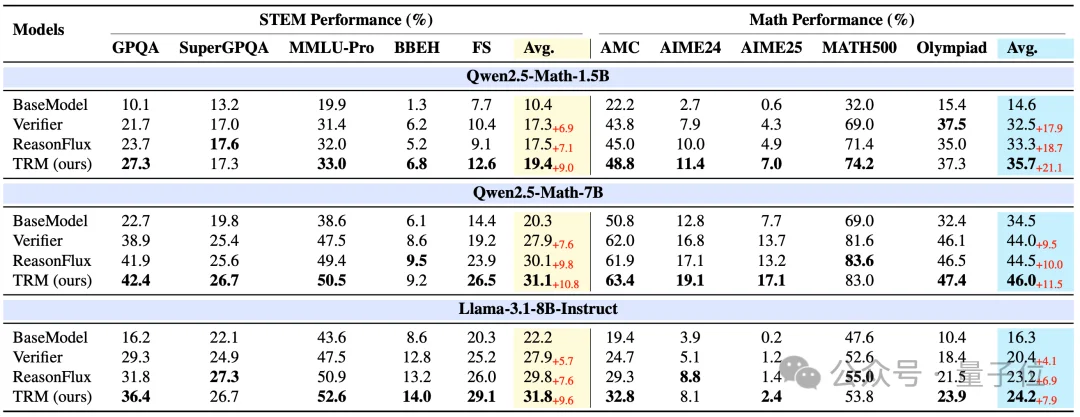
RL训练结果如下。TRM作为辅助奖励,在多个模型和STEM/Math任务上带来更稳定的性能提升。
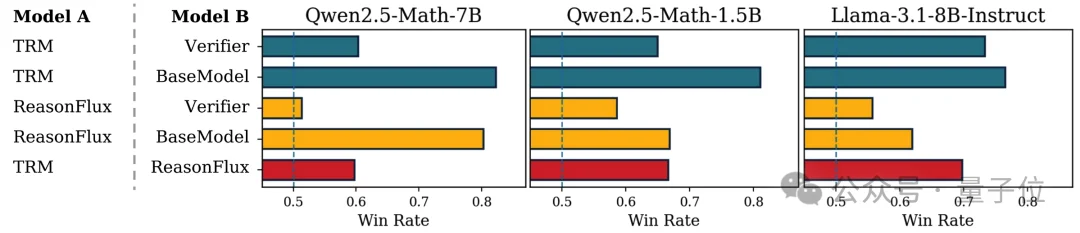
不过,性能提升并不等于推理过程一定变好。为进一步验证这一点,论文用DeepSeek-V3.2按照ME² principle,对不同训练策略生成的推理链进行成对比较。
结果显示,在三个基座模型上,TRM训练后的策略相较于多种基线策略,都取得了更高胜率。
这说明TRM让模型生成的推理过程更接近清晰、高效、可靠的推理。
随着大模型走向复杂数学、科学推理、智能体规划和长期任务执行,推理过程的重要性会继续上升。
未来的模型既要答对,也要更会组织思路、减少无效分支、抓住关键步骤。
TRM的意义就在于,它让想得好从一种主观感受,变成可以度量、可以训练、可以优化的能力。
论文标题:Characterizing, Evaluating, and Optimizing Complex Reasoning
链接:https://arxiv.org/abs/2602.08498
代码:https://github.com/Simplified-Reasoning/TRM
文章来自于"量子位",作者 "TRM团队"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
