# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
具身智能数据的竞争,正在从“量大管饱”进入下一关。
过去一年,第一视角视频成了机器人训练的主流燃料。人戴上相机做饭、整理桌面、开抽屉,就能产出大量操作样本。
数据量的问题初步缓解,但一个更深的缺口浮出来了:
这些视频只记录了人做了什么,没有记录人为什么这样做,更没记录动作执行中大脑和身体如何实时修正。
FaceMind脸谱心智想填的,就是这个缺口。
这家由两位95后博士创立的公司,提出了一套全新的Ego-NeuroLoop数据范式。
它同时采集四类信号,把人类完成一个动作时“看哪里、准备做什么、肌肉怎么发力、反馈怎么修正”的完整闭环,压进同一条时间轴。
配套的硬件方案NeuroMatrix负责降低采集门槛,信号处理层NeuroBooster负责把噪声拉满的原始数据对齐成模型能“吃”的格式。

而这一整套思路的起点,来自神经科学里一条被反复验证的理论:贝叶斯大脑。
神经科学里有一条被反复验证的理论,叫“贝叶斯大脑”,常和预测处理、自由能原则放在一起讨论。
它的核心思想是,大脑不是被动接收信息的容器,它一直在主动预测。基于过去经验和当前上下文,大脑会对外部世界和身体状态生成概率化预期,再拿感官反馈去校准。
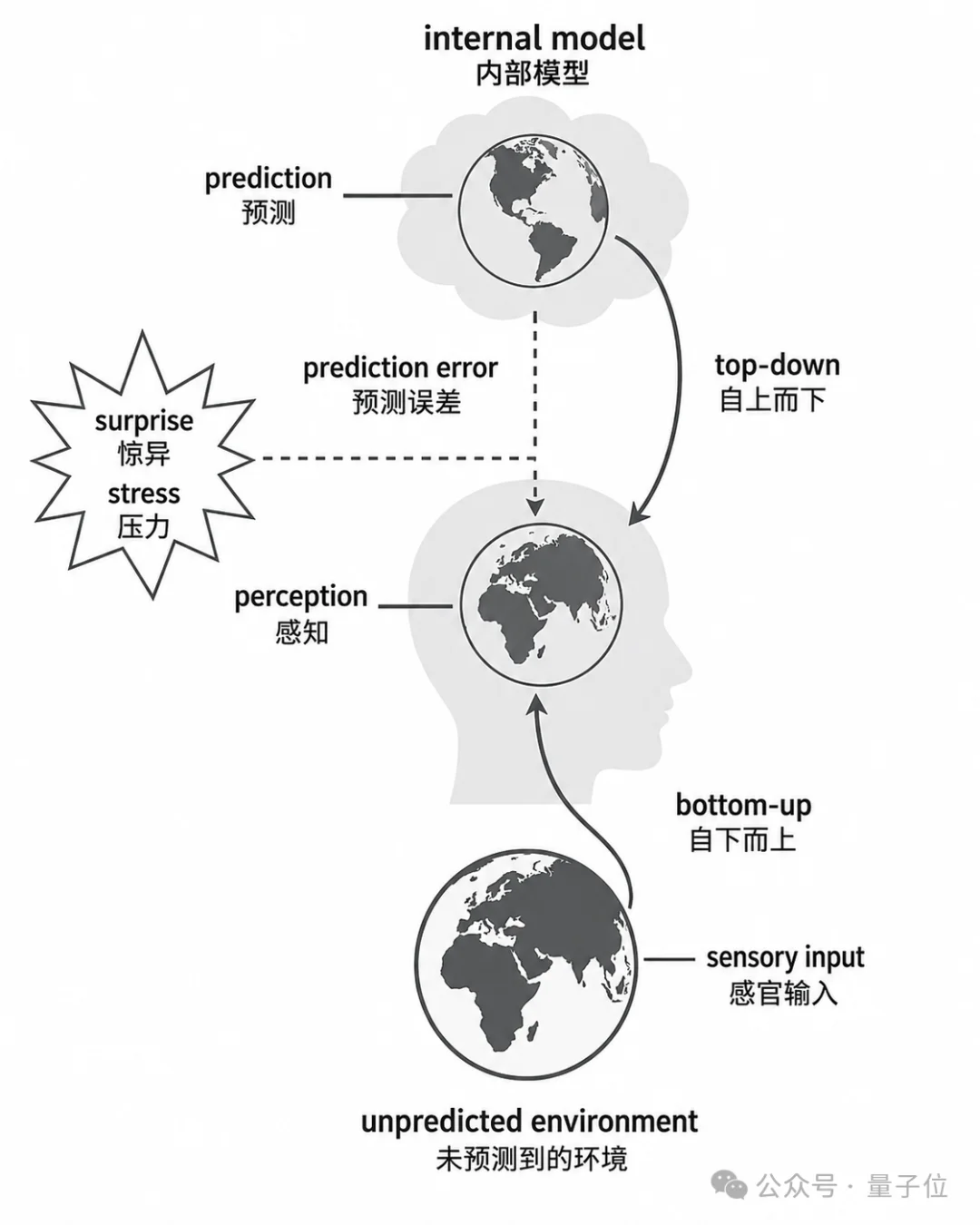
你下一秒会看到什么、手伸出去会碰到什么,目标还在不在刚才那个位置,大脑全在提前算。
真实感官输入回来后,预测和现实一对比,差值就成了预测误差。误差推着内部模型往前更新。
拿AI领域的概念类比,大脑本身就在跑一套世界模型。
AI里的世界模型研究环境如何随动作变化,大脑做的事很像,只不过人类这套系统天然和身体长在一起。视觉、视线、触觉、本体感觉、肌肉反馈、注意力、误差信号,全跑在同一条链路上。
具身智能想学的,恰恰是这个。
机器人要进入厨房、仓库、实验室、家庭这样的真实场景,光有视觉识别和动作模仿还不够。
真实世界会滑、会挡、会变、会突然打断任务。目标怎么选,动作什么时候启动,偏差出现后怎么修正,失败了怎么换策略,这些能力单靠一段视频学不到。
具身智能真正缺的,不是更像录像机的数据,是更像大脑运行日志的数据。
过去一年,ego-centric、human-centric数据成为具身智能的主流燃料。
机器人真机数据采集成本高、速度慢、设备贵,场景覆盖有限。
相比之下,人类第一视角数据的采集门槛低得多,一个人戴上相机做饭、整理桌面、开抽屉、拿工具,就能产出大量原始任务素材。
这类数据能记录环境里有什么,物体怎么变化,手和物体如何接触,任务最后有没有完成。对模型来说,这些都是真实世界操作的基础材料。
但第一视角视频有一个天然边界:它主要记录人做了什么。
现有human-centric数据更像一个行为结果库,记录的是动作轨迹和任务结果。
具身智能真正需要学的东西,是行为生成机制——目标如何被发现,注意力如何切换,意图如何形成,肌肉如何执行,反馈怎么改变动作。
如果大脑是一套预测式世界模型,训练数据就要尽可能记录这套模型的运行过程。不只是“人看到了什么、手做了什么”,还要覆盖“人如何预测、如何行动、如何反馈、如何更新”。
FaceMind脸谱心智想填的就是这个缺口。
这家公司由两位95后博士陆弘远、韦怡然创立,早期从端侧全模态模型切入,随后把研究重心转向更底层的世界模型方向。

但他们更关键的切入点,是把贝叶斯大脑理论转译成具身智能的数据问题。
神经科学认为,大脑通过内部模型预测世界,用反馈误差更新模型;AI里的世界模型,也想让智能体理解环境如何随动作变化。
具身智能要把两者接起来,就需要一类新数据,以此来记录人类大脑、身体和环境如何形成闭环。
Ego-NeuroLoop就是在这个背景下出现的。
它不是单纯多采一点视频,也不是把人类动作再标一遍标签。
它要采的是人类完成任务时的闭环过程:人看哪里,什么时候准备动作,肌肉如何启动,反馈怎样出现,动作又如何被修正。
贝叶斯大脑里的“预测、误差、更新”机制,正在借由Ego-NeuroLoop变成机器人可以学习的数据资产。
Ego-NeuroLoop把人类操作过程拆成四类同步信号:world camera、gaze、EEG和sEMG,分别对应外部环境、注意力、神经状态和肌肉执行。

其中,world camera记录环境。
桌面上有什么,目标物体在哪,手和物体怎么接触,任务走到了哪一步。这一层提供的是世界模型的外部输入。
gaze记录视线。
人做动作之前,眼睛往往先到。先看目标,再看可抓取区域,必要时扫一眼障碍物或下一步的放置位置。视线轨迹能帮模型从复杂环境里筛出当前真正相关的信息。
EEG补的则是动作发生之前那段“前奏”。
脑电读不出完整想法,但动作准备、注意状态、任务切换、误差感知这些信号它都能捕捉。
手还没动,神经系统已经进入准备状态,这个时间差只有EEG能记录。
sEMG把动作落到肌肉层面。
手臂、手腕、手指什么时候激活,发力怎么变化,动作修正发生在哪个阶段。相比只看手部轨迹,sEMG多给出的是执行力度和控制细节。
四类信号放到同一条时间轴上,一个动作就从一段轨迹变成一条完整链路——
目标被发现,注意力聚焦,神经系统进入准备,肌肉开始激活,手接触物体,反馈回流,力度和轨迹被重新调整。
模型从这类数据里学到的,不只是“人怎么做”,还有“人凭什么做对的”。
数据定义好了,得先采得到。
FaceMind给出的硬件方案叫NeuroMatrix,负责同步采集视觉、视线、EEG、sEMG四类信号。
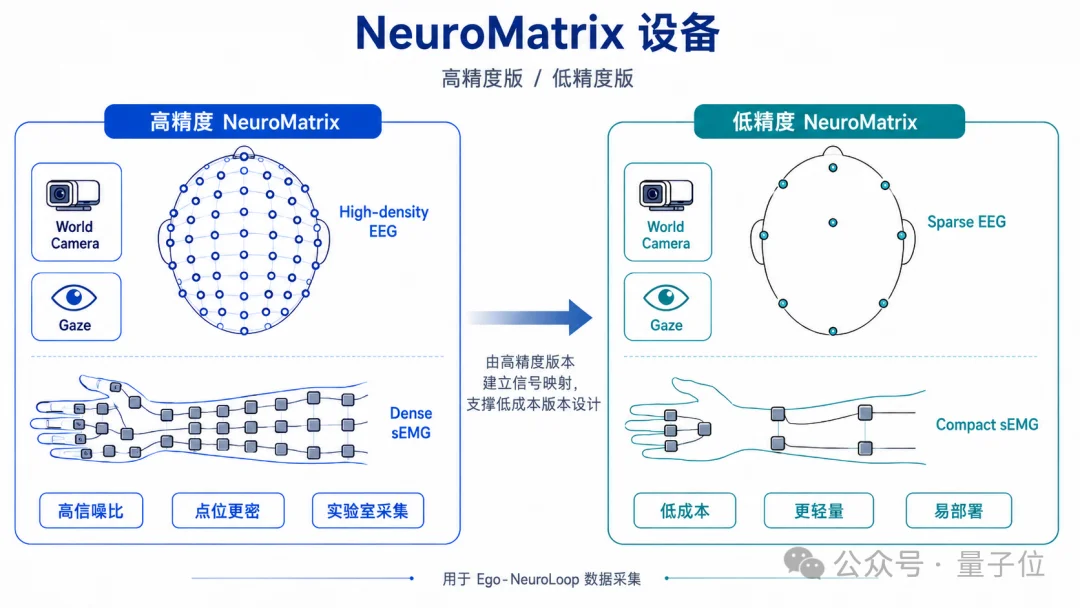
这里最大的现实问题,是成本和部署难度。
高精度脑电、肌电和视线追踪设备往往更适合实验室环境,通道多、成本高、佩戴复杂,很难直接铺到真实世界的大规模任务里。
NeuroMatrix的思路,是先用高精度版本建立信号地图。
高精度阶段拿到的是完整的脑电、肌电、视线和视觉数据。
系统在这一步分析动作意图和脑区信号的对应关系,搞清楚哪些头皮电极通道、哪些肌肉区域、哪些视觉目标之间存在稳定关联。
地图画完之后,硬件设计围绕关键位置收缩,减少电极数量,压缩传感器点位,把设备往更轻、更便宜、更容易戴上就走的方向做。
这一步决定数据生产能铺多远。
具身智能需要长期、稳定、贴近真实场景的数据供应,少量实验室级样本撑不起通用机器人训练。
采集门槛不降下来,人类闭环操作数据就没法进入更高频、更大规模的生产阶段。
采到的数据还不能直接用,因为这些信号都不干净。
EEG容易受到电极接触、头动、眨眼和环境干扰影响;sEMG会受到佩戴偏移、肌肉串扰和动作幅度影响;gaze可能漂移或短时丢失;视觉数据也躲不开遮挡、模糊和视角变化。
更麻烦的是,多模态数据之间的时间同步问题,原始信号很难直接变成训练样本。
FaceMind给出的第二层,是NeuroBooster。
它是一个面向神经和身体信号的多模态基座模型,能把粗糙、异步、信噪比低的原始数据,整理成一条模型能消费的闭环时间轴。
一个类比可能更好理解,VLM对齐的是图像和文本,NeuroBooster对齐的是视觉、视线、EEG、sEMG。
这套系统的关键在于模态互补。
经过时间对齐、信号配对、增强重建和结构化输出后,模型拿到的不再是一堆孤立传感器记录,而是一条更完整的操作链路:看到了什么,注意哪里,准备做什么,如何发力,反馈如何出现,下一步怎样调整。
具身智能数据的竞争,过去一直围绕规模、场景、动作展开。
谁数据量大,谁覆盖任务多,谁的动作样本丰富,谁就更有机会训练出强策略模型。
下一轮竞争的核心指标不一样了:闭环质量。
同样是拿杯子这个动作,一段普通视频给模型提供的是轨迹,手从哪里来,到哪里去,杯子最后有没有被拿起来。
而脸谱心智Ego-NeuroLoop提供的是更细的过程,目标如何被发现,注意力怎样转移,动作准备何时出现,肌肉什么时候发力,接触之后反馈怎样改变了后续动作。
两种数据喂出来的模型,能力边界差在哪?
只学轨迹,模型容易停在表层模仿,擅长复现,给它见过的场景它能照着做一遍,但物体一滑、光线一变、任务被打断,它没有内部状态去判断偏差出现在哪个环节。
学过闭环过程的模型则多了一层东西:它见过人类在同样的偏差面前怎么调整发力、怎么重新分配注意力、怎么切换策略,它有机会把这些修正逻辑迁移到自己的决策里。
从这个角度看,Ego-NeuroLoop的意义在于把训练数据从“行为库”推向“闭环库”。
它记录人类做了什么,也记录大脑、身体和环境怎么协同把事情做成。
机器人缺的世界模型,可能藏在人类大脑里。
更准确地说,藏在大脑、身体和环境的连续交互里。
贝叶斯大脑理论给出了一个框架:大脑通过内部模型预测世界,拿感官输入校准预测,用误差推动模型更新。
具身智能要走向真实操作,需要的是同一套能力。机器人不能只看见世界,还得预测世界;不能只执行动作,还得根据反馈更新下一步动作。
FaceMind的做法,是沿着这个框架从数据端一路铺到模型端。
Ego-NeuroLoop定义了新的数据范式,NeuroMatrix把多模态信号采集的门槛降下来,NeuroBooster把低成本信号对齐增强成模型能用的格式。
模型侧也有对应动作,FaceMind此前发布的Looped World Models(循环世界模型),用参数共享的transformer block对环境状态做迭代式更新,让世界模型在内部完成多轮修正。
数据侧采闭环,模型侧跑闭环,两头接上了。
这条路线真正在赌的一件事是,机器人要更像人一样完成任务,瓶颈不只在模型架构,也在训练数据到底记录了人类操作的哪一层。
轨迹、结果、成功率,这些是表层。
预测、反馈、修正,这些或许才是控制策略真正生长的土壤。
文章来自于"量子位",作者 "允中"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
