# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多模态大模型的训练数据,很多其实“看不看图都一样”。
现在有人把这件事量化了出来。
来自上海交大、马来亚大学、CMU、MBZUAI、KIT和KAUST的团队提出VisNec(Visual Necessity Score,视觉必要性分数),用一个分数衡量每条训练样本里“图像到底起了多大作用”,被ECCV 2026收录。

做法很直接:让模型分别在看图和不看图两种情况下预测答案,两次损失一减,就知道这张图有没有用。
靠这个分数筛数据,在LLaVA-665K上只用15%的样本训练,就追平了全量数据的表现(100.2%);换到Vision-Flan-186K上,不仅数据更少,效果还反超全量训练15.8%。
大规模多模态指令数据有个老问题,里面塞了不少“图其实可有可无”的样本。
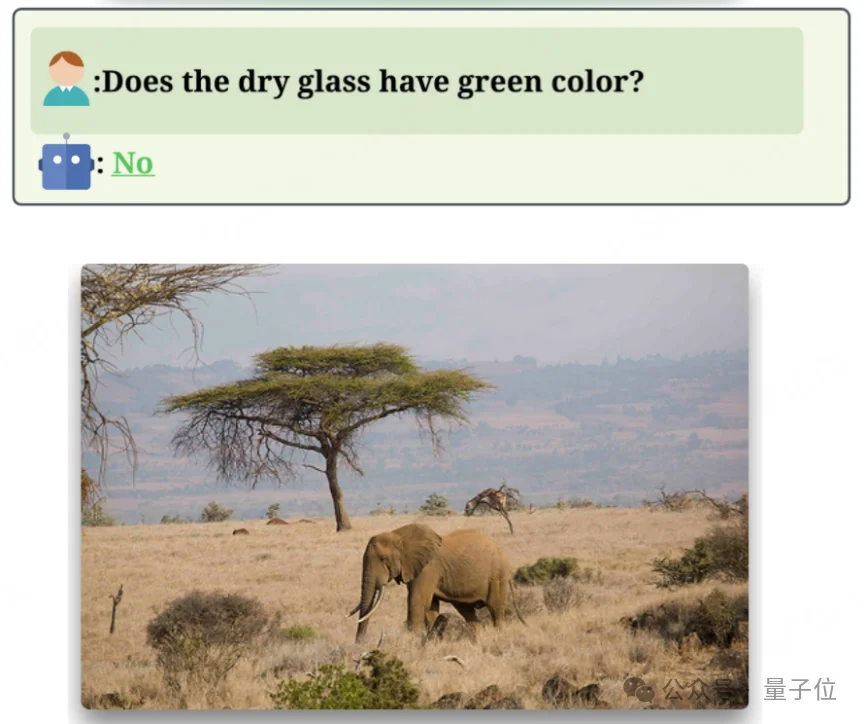
比如问“干燥的草是绿色吗”,模型根本不用看图,靠语言先验就能答“不是”。这类样本被团队称为视觉冗余(Redundant),训练时模型只会越来越依赖文字套路,而不是真去看图。
更麻烦的是另一类样本。标注出错或数据管线有噪声,会产生图文对不上的情况,团队称之为多模态错配(Misaligned)。这种样本不只是没用,还会反过来拖累训练,让模型在推理时更容易产生幻觉。
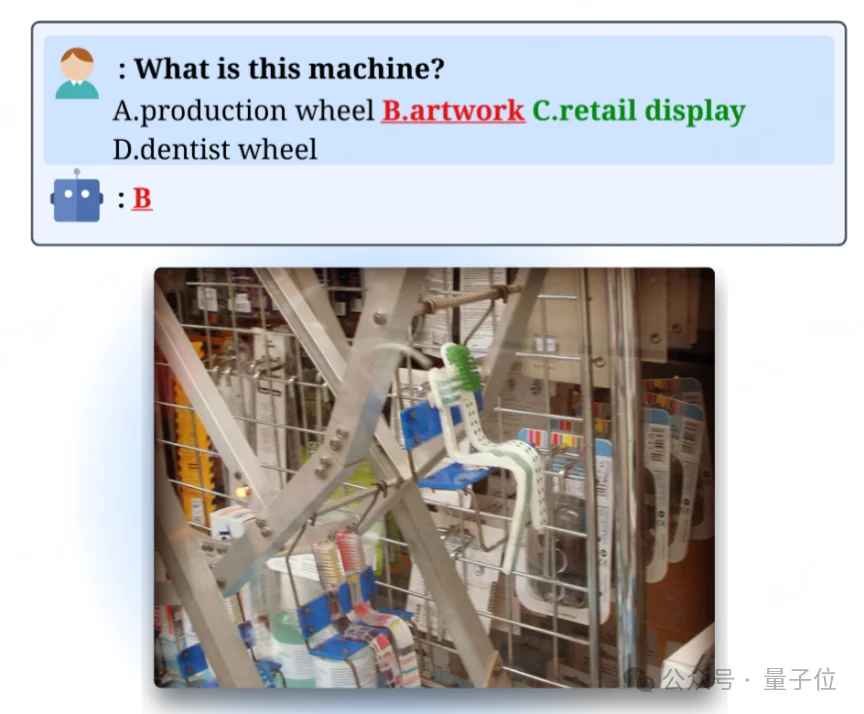
先看两个例子。一个样本里,图片中的人物明明在海边冲浪,选项里的正确视觉答案应是surfing,但训练标注却给成了fishing。另一个样本里,图片更像零售货架上的牙刷陈列,标注却把它当成artwork。

过去的数据筛选方法大多把样本当成一个整体打分,看梯度影响、看可迁移性、看聚类覆盖,却没有单独去看视觉这一路到底贡献了多少。结果就是筛出来的子集里,要么还是偏爱文字简单的样本,要么仍然留着有害的错配数据。
VisNec想换个角度:一条多模态样本值不值,要看视觉输入是不是真的为解决问题出了力。
VisNec的灵感来自V-usable information理论,这套理论衡量的是某个变量能在多大程度上降低预测的不确定性。
团队把它搬到了多模态场景,给每条样本算一个分数。
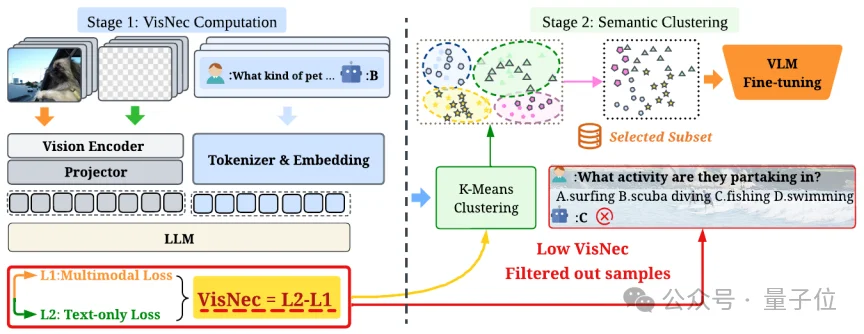
简单说,同一条样本跑两遍。一遍是正常的多模态前向,模型既看文字也看图,得到多模态损失;另一遍叫盲前向(Blind Forward Pass),把图像位置换成填充token、并把对应的注意力屏蔽掉,让模型只靠文字答题,得到纯文本损失。
VisNec分数就是两者之差:纯文本损失减去多模态损失。
这个差值把样本分成三类。

加了图之后预测误差明显下降,说明这条样本真的需要跨模态推理。论文里一个高分样本(3.47)是按坐标框描述图像区域,没有图根本答不了。
看不看图都答得差不多,说明样本主要靠语言先验。比如“牛角是大是小”“这是什么地方”,靠常识就能答,图没提供额外信息。
加了图反而让损失变大,意味着图文矛盾。论文里一个负分样本(-1.21)问“是不是在户外”,答案标成“Yes”,可图里明明是室内场景;接着问“开心的女人在画面哪边”,答案是“左边”,但图里压根没有女人。这种样本模型干脆别看图还更准,VisNec直接把它们扔掉。
光按分数排序还不够。
不同任务对图的依赖天然不一样,几何推理需要的视觉信息就比OCR多。如果直接全局取高分,数据集会被某几类任务带偏。
为此团队加了一步语义聚类。先把每条指令里的问题部分抽出来,映射到语义空间做K-Means聚类(默认20类),把几何推理、OCR、创意生成这些不同能力分开。
然后在每个簇内部操作:先把分数小于等于0的样本(错配和冗余)剔除,剩下的按VisNec分数排序,按预算比例取top-r%。这样选出来的子集既保证了“图确实有用”,又覆盖了多样的任务类型。
实验在LLaVA-665K和Vision-Flan-186K两个数据集上做,统一用15%的采样比例。
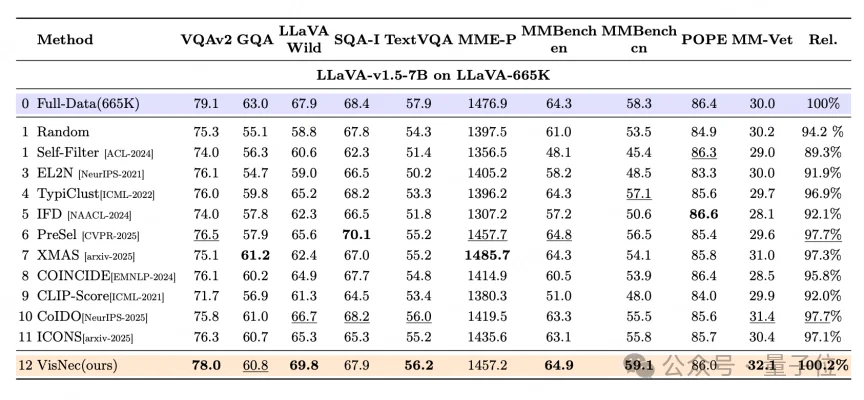
在LLaVA-665K上微调LLaVA-v1.5-7B,VisNec拿到100.2%的相对表现,超过随机基线5.8%,比第二名高2.3%,在一众SOTA方法(XMAS、PreSel、CoIDO、COINCIDE、ICONS等)中领先。其中在LLaVA-Wild、MMBench中英文、MM-Vet这几项开放式推理和抗幻觉评测上,它甚至超过了用全量数据训练的模型。
换到任务更杂的Vision-Flan-186K(含191个任务),VisNec拿到115.8%,比随机基线高18.4%,比全量训练反超15.8%。
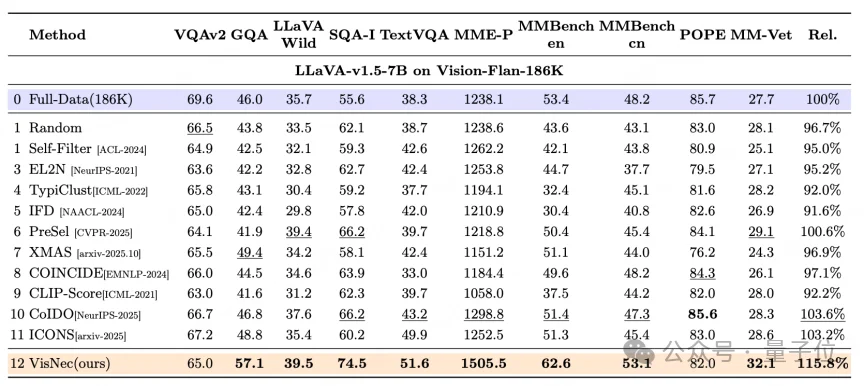
这个反超说明,Vision-Flan-186K里有相当一部分样本不只是冗余,而是有害的,把图文矛盾的样本筛掉之后,模型反而学得更好。在多模态指令微调里,数据质量比数据数量更要紧。
为了验证VisNec抓的是数据本身的价值、而不是某个模型的偏好,团队把打分直接换到Qwen2.5-VL系列上跑。
在3B、7B、32B三个规模上,用VisNec选出的15%数据,分别达到各自全量表现的103.8%、104.0%和102.4%。
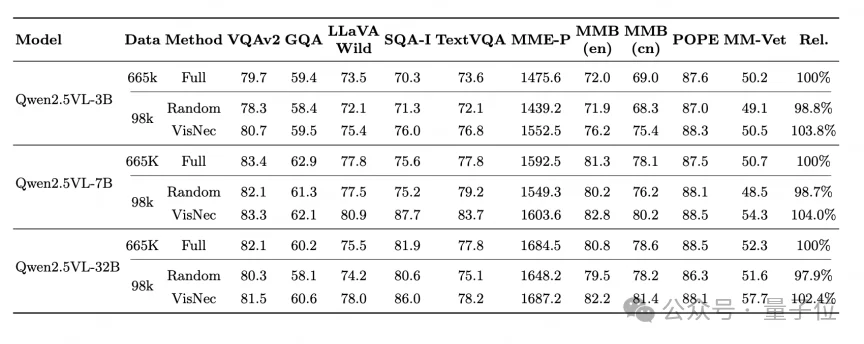
也就是说,从3B到32B、跨越不同架构,这套筛选都站得住,说明它捕捉的是数据内在的视觉必要性。
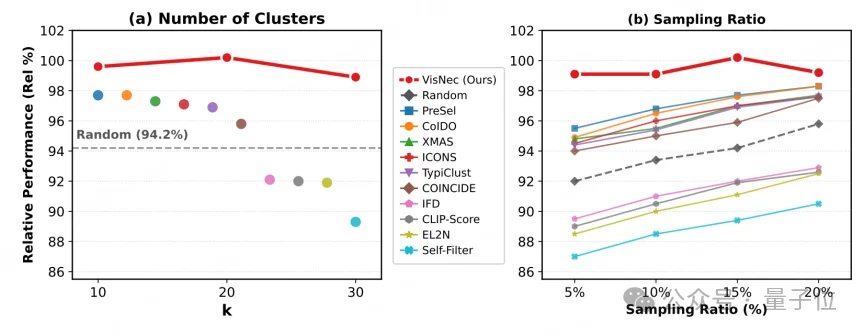
消融实验也显示,聚类数k在10到30之间波动时,相对表现只在1.3%的窄幅内变化,方法比较稳。进一步在5%到20%的不同保留比例下测试,VisNec也始终优于其他数据选择方法:即使预算压到5%,它依然能选出更高价值的样本。
现有多模态数据选择方法大多面临各自的局限。
梯度影响方法(如ICONS)通常需要对样本做反向传播,计算成本高;外部API打分方法(如PreSel、CoIDO)依赖闭源模型,额外费用和数据隐私都是问题;文本质量指标(如IFD)则更像从NLP范式迁移过来,容易偏爱文字上“看起来好”的样本,却未必能识别视觉到底有没有贡献。
VisNec的核心差异在于:它不是给整条样本打一个笼统质量分,而是直接比较“看图”和“不看图”的预测差异。这样既能选出真正需要视觉证据的样本,也能主动惩罚图文错配样本。
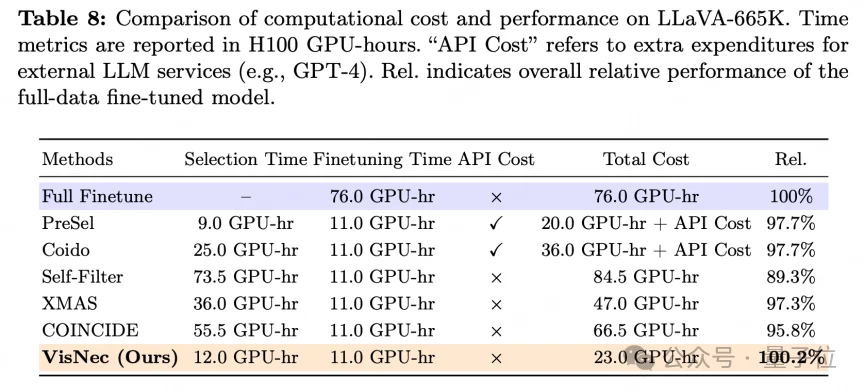
计算上,VisNec只需在现有模型上做两次前向推理,不需要额外训练,也不依赖外部工具,对比全量数据约76小时完成微调,VisNec仅需约23小时,整体耗时降低约69.7%,对应约3.3倍的加速。
已公开项目页:
https://dmk041218.github.io/VisNec/
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
