# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
GPT-4的图形推理能力,竟然连人类的一半都不到?
美国圣塔菲研究所的一项研究显示,GPT-4做图形推理题的准确率仅有33%。
而具有多模态能力的GPT-4v表现更糟糕,只能做对25%的题目。
这项实验结果发表后,迅速在YC上引发了广泛热议。
赞同这项结果的网友表示,GPT确实不擅长抽象图形处理,“位置”“旋转”等概念理解起来更加困难。
但另一边,不少网友对这个结论也有所质疑,简单说就是:
不能说是错的,但说完全正确也无法让人信服。
至于具体的原因,我们继续往下看。
为了评估人类和GPT-4在这些图形题上的表现,研究者使用了自家机构于今年5月推出的ConceptARC数据集。
ConceptARC中一共包括16个子类的图形推理题,每类30道,一共480道题目。
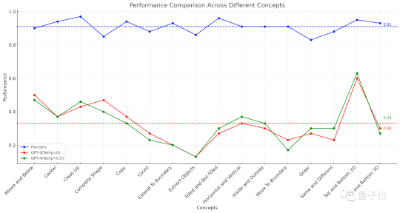
这16个子类涵盖了位置关系、形状、操作、比较等多个方面的内容。
具体而言,这些题目都是由一个个像素块组成的,人类和GPT需要根据给定的示例寻找出规律,分析出图像经过相同方式处理后的结果。
作者在论文中具体展示了这16个子类的例题,每类各一道。
结果451名人类受试者平均正确率,在各子项中均不低于83%,16项任务再做平均,则达到了91%。
而GPT-4(单样本)在“放水”到一道题可以试三次(有一次对就算对)的情况下,准确率最高不超过60%,平均值只有33%。
早些时候,这项实验涉及的ConceptARC Benchmark的作者也做过类似的实验,不过在GPT-4中进行的是零样本测试,结果16项任务的平均准确率只有19%。
而多模态的GPT-4v,准确率反而更低,在一个48道题组成的小规模ConceptARC数据集中,零样本和单样本测试的准确率分别只有25%和23%
而研究者在进一步分析了错误答案后,发现人类的有些错误看上去很可能是“粗心导致”,而GPT则是完全没有理解题目中的规律。
针对这些数据,网友们普遍没什么疑问,但让这个实验备受质疑的,是招募到的受试人群和给GPT的输入方式。
一开始,研究者在亚马逊的一个众包平台上招募受试者。
研究者从数据集中抽取了一些简单题目作为入门测试,受试者需要答对随机3道题目中的至少两道才能进入正式测试。
结果研究人员发现,入门测试的结果显示,有人只是想拿钱,但根本不按要求做题。
迫不得已,研究者将参加测试的门槛上调到了在平台上完成过不少于2000个任务,且通过率要达到99%。
不过,虽然作者用通过率筛人,但是在具体能力上,除了需要受试者会英语,对图形等其他专业能力“没有特殊要求”。
而为了数据的多样化,研究者在实验后期又将招募工作转到了另一个众包平台,最终 一共有415名受试者参与了实验。
尽管如此,还是有人质疑实验中的样本“不够随机”。
还有网友指出,研究者用来招募受试者的亚马逊众包平台上,有大模型在冒充人类。
再来看GPT这边的操作,多模态版本比较简单,直接传图然后用这样的提示词就可以了:
零样本测试中,则只要去掉相应的EXAMPLE部分。
但对于不带多模态的纯文本版GPT-4(0613),则需要把图像转化为格点,用数字来代替颜色。
针对这种操作,就有人表示不认同了:
把图像转换成数字矩阵后,概念完全变了,就算是人类,看着用数字表示的“图形”,可能也无法理解
无独有偶,斯坦福的华人博士生Joy Hsu也用几何数据集测试了GPT-4v对图形的理解能力。
这个数据集发表于去年,目的是测试大模型对欧氏几何的理解,GPT-4v开放后,Hsu又用这套数据集给它测试了一遍。
结果发现,GPT-4v对图形的理解方式,似乎“和人类完全不同”。
数据上,GPT-4v对这些几何问题的回答也明显不如人类。
论文地址:
[1]https://arxiv.org/abs/2305.07141
[2]https://arxiv.org/abs/2311.09247
参考链接:
[1]https://news.ycombinator.com/item?id=38331669
[2]https://twitter.com/joycjhsu/status/1724180191470297458
文章来自微信公众号 ” 量子位 “,作者 克雷西


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0