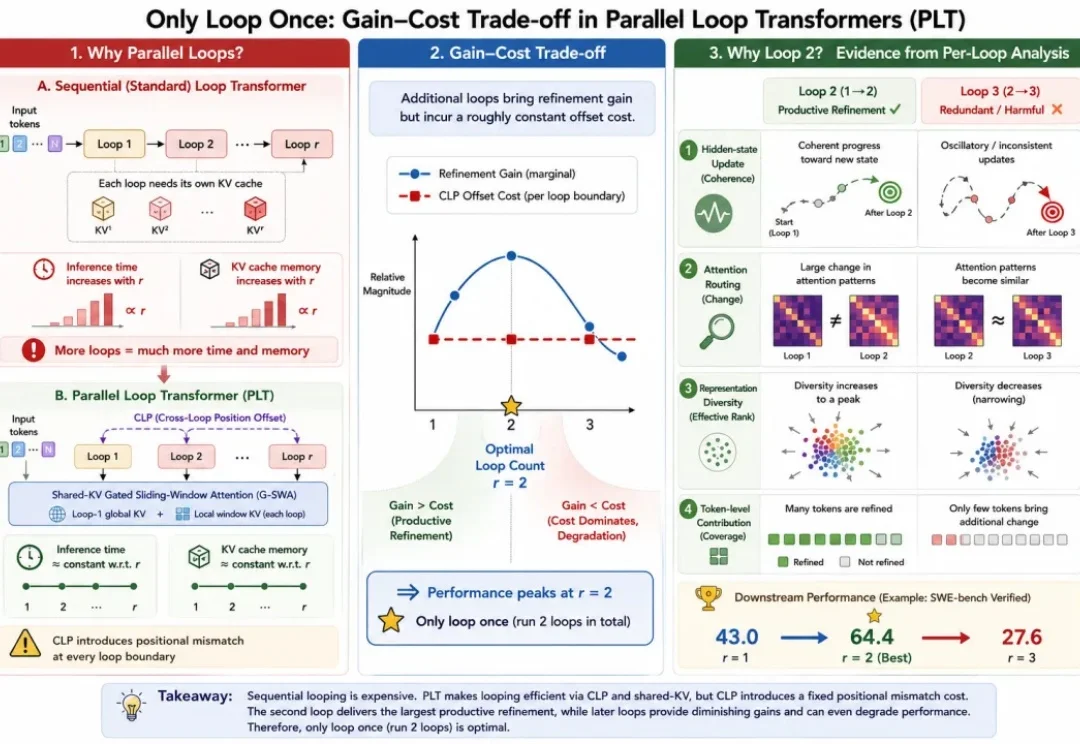
都在卷「让大模型多循环几遍」,这个7B模型LoopCoder v2说:多循环 1 次就够了
都在卷「让大模型多循环几遍」,这个7B模型LoopCoder v2说:多循环 1 次就够了当所有人都在比谁「想得更久、算得更多」——推理模型动辄输出成千上万个思考 token,循环式架构恨不得在内部反复迭代十遍八遍——一项新研究反手泼了盆冷水:
来自主题: AI技术研报
6353 点击 2026-07-01 10:26
 搜索
搜索
当所有人都在比谁「想得更久、算得更多」——推理模型动辄输出成千上万个思考 token,循环式架构恨不得在内部反复迭代十遍八遍——一项新研究反手泼了盆冷水:

AgentSociety²是清华大学团队推出的社会科学研究新工具,通过AI智能体模拟社会行为,帮助研究者构建实验环境,直接运行社会假设。它让AI同时扮演研究助手和实验参与者角色,使复杂社会问题能被构造、运行和分析,提升研究效率与可复现性。

卫星和航空影像里的目标,不仅大小相差悬殊,还可能朝向任意方向:一边是细长的桥梁、船舶,一边是密集的小车和大面积运动场。PKINet-v2是一种改进的遥感目标检测模型,能同时处理复杂形状和尺度变化的问题。
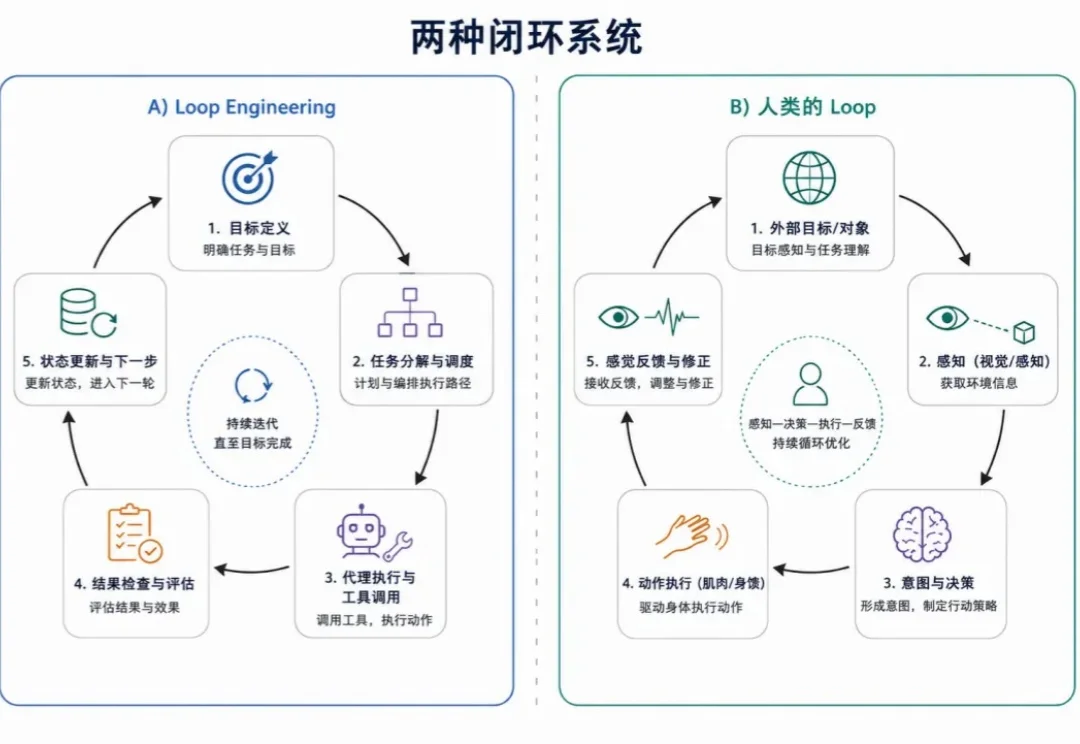
AI 圈最近又热了一个词:Loop Engineering。
最近网上冲浪,刷到两个特别有意思的 GitHub 项目,分享给大家。
长期以来,机制可解释性(mechanistic interpretability)领域有一个几乎从未被明说、却被视为理所当然的前提:模型对于同一种任务的能力或表现,背后对应着一条唯一的、或近乎唯一的内部「电路」(circuit)。该领域的研究者们之所以要做「电路发现」(circuit discovery),是为了要把这些「特定的」电路找出来。

近期,DeepSeek发布DSpark让大模型推理效率再次成为行业焦点。
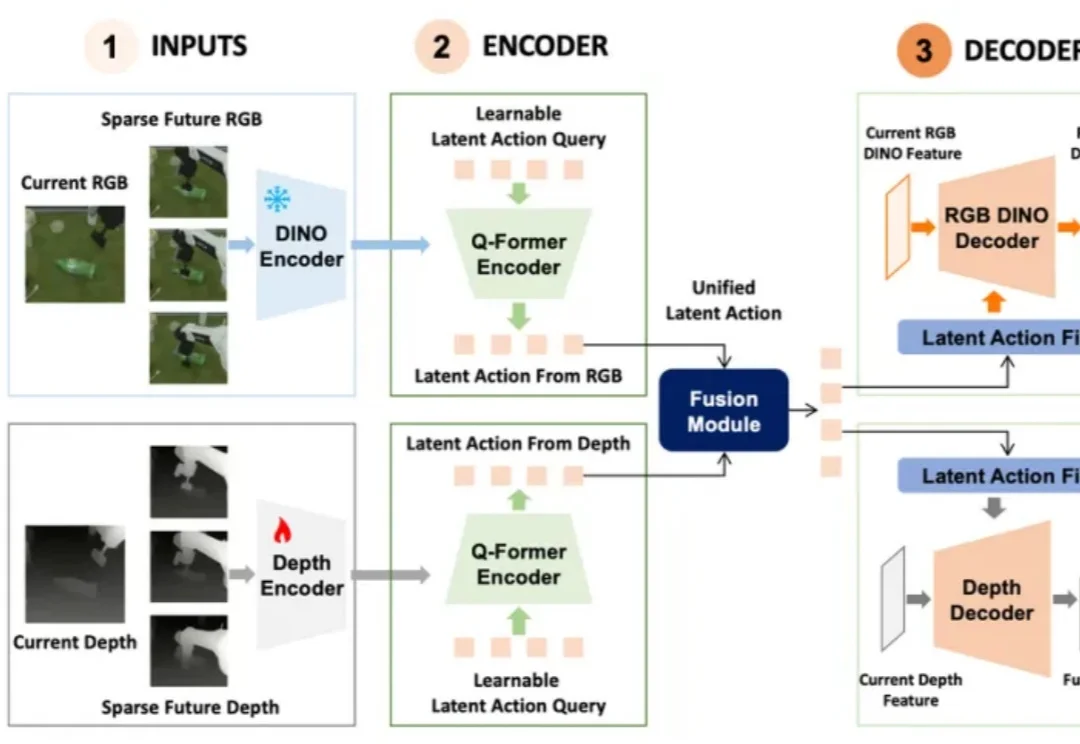
当前,物理 AI 正面临着关于泛化能力的普遍质疑。当模型缺乏对真实物理规律的深度认知、难以跨越复杂多变的开放场景时,如何让机器人真正理解物理世界并精准规划决策,已成为具身智能破局的关键。
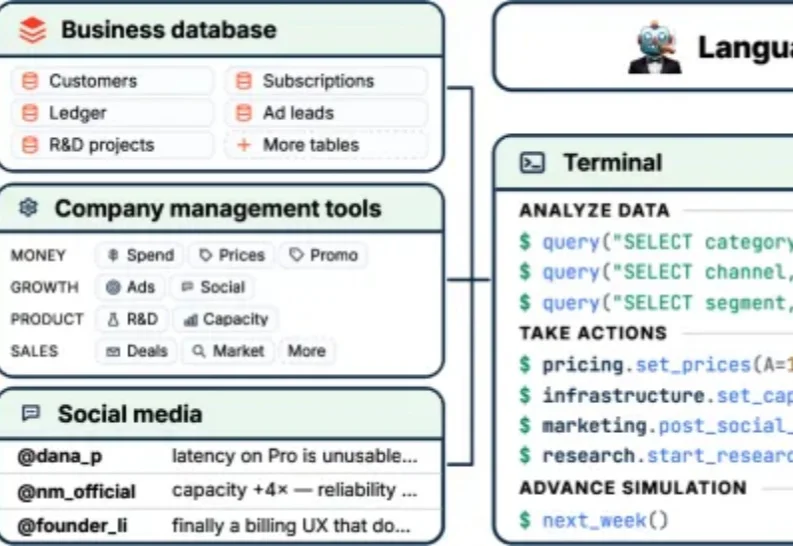
AI当「老板」,快给10家公司干破产了……

2026 年 6 月,大模型行业正在经历一场前所未有的「开源海啸」:英伟达放出了 550B 参数的混合架构模型,谷歌送出多模态的 Gemma 新版本,智谱用最宽松的协议全量开源了自家旗舰模型。
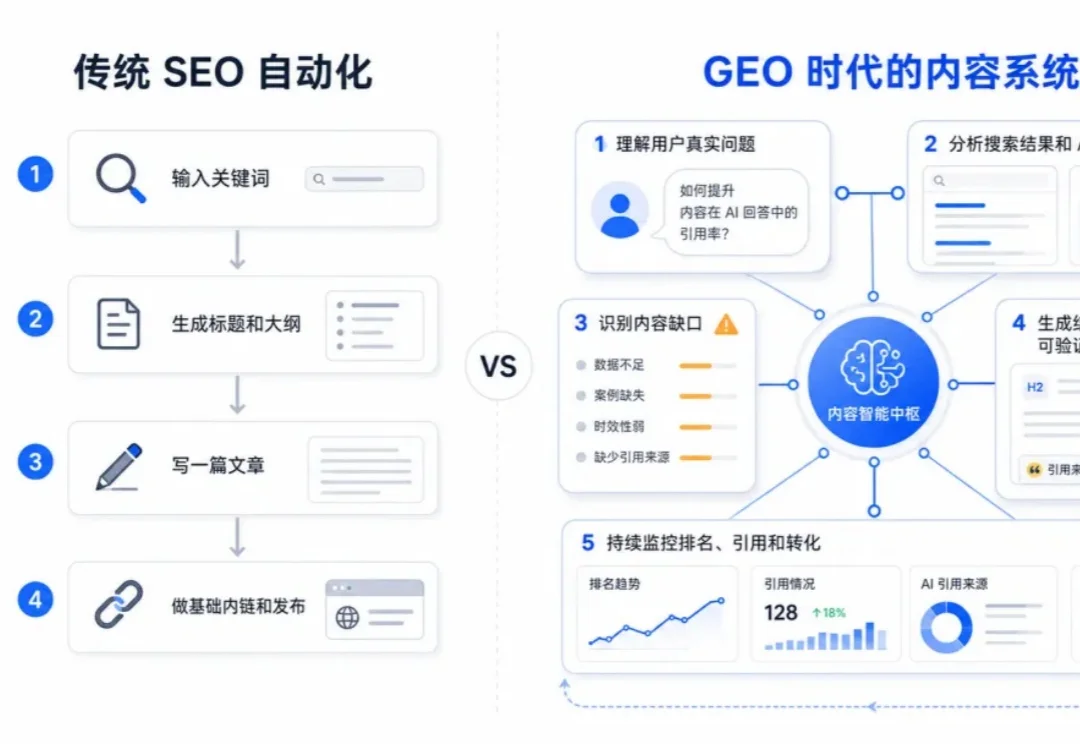
最近,有很多朋友来请教我们一个问题,GEO到底要怎么做,才能让生成的内容质量更高。

如今,大模型越来越擅长回答问题了,但当 AI 不再只停留在聊天窗口,而是走向智能眼镜、可穿戴设备乃至家庭机器人时,问题会随之改变。用户未必有时间把需求完整说出来,也未必希望助手随时插话。更理想的助手,应该能在现场真正理解人,在用户需要的时候出现,在不合适的时候保持安静。

随着全球智能体加速落地,算力需求呈指数级爆发,以 GPU 为核心的 AI 基础设施正变得愈发关键。据摩根士丹利报告预测,2028 年全球 AI 基础设施累计总投资将达 2.9 万亿美元。

你从桌上端起一杯水,大脑用了不到一秒,同时完成三件事: 估算杯子的重量,预判水面晃动的幅度,顺便绕开了旁边那个玻璃杯。

你以为自己在用GPT-5.5,但OpenAI可能已经在后台,悄悄把你的底层模型换成了更先进的GPT-5.6 Sol。

在世界模型这条路上,行业一直卡在一个几乎无解的矛盾里:想要更真实的长程模拟,就必须给模型更深的计算;可一旦把模型做得更深,部署成本、参数规模和误差累积又会迅速抬头。结果就是,大家都知道世界模型要 “想得更久”,却很难让它在现实系统里 “算得起、跑得稳”。
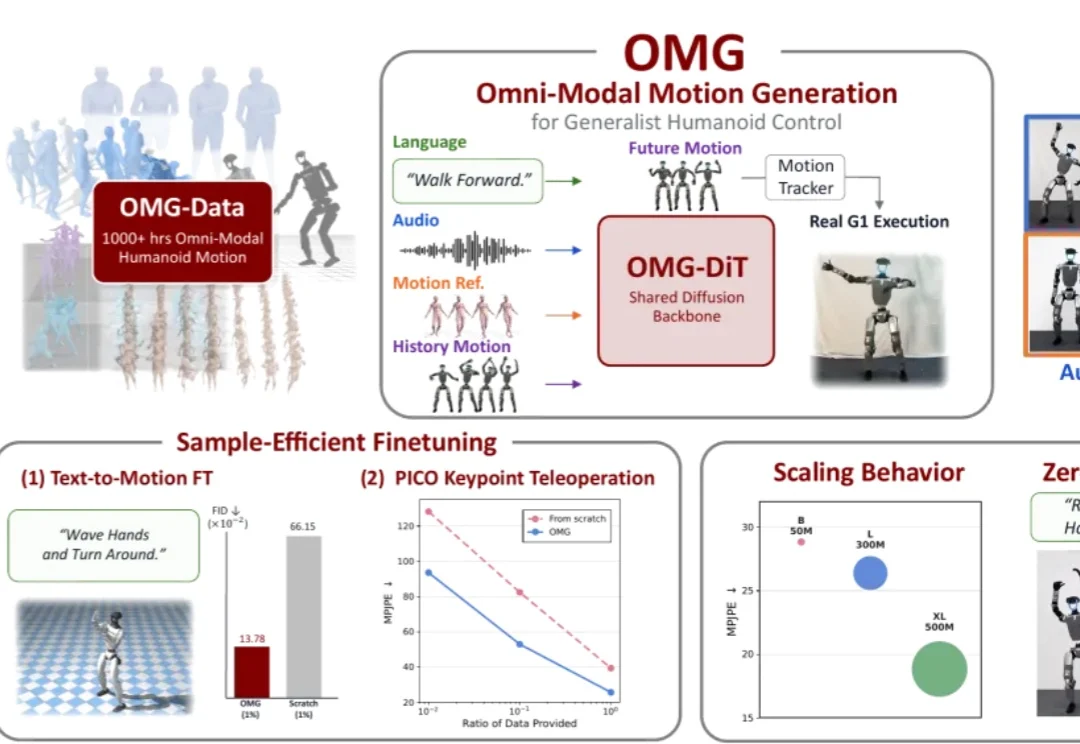
现阶段大多数人形机器人的运动控制还局限于 “有参考才能动” 的被动跟踪模式。

2026年6月17日,Nature 刊登了一项里程碑式的研究,来自海德堡大学医院的研究团队开发了一个名为MIRA(Medical Intelligence for Reasoning and Action) 的自主医疗AI智能体。
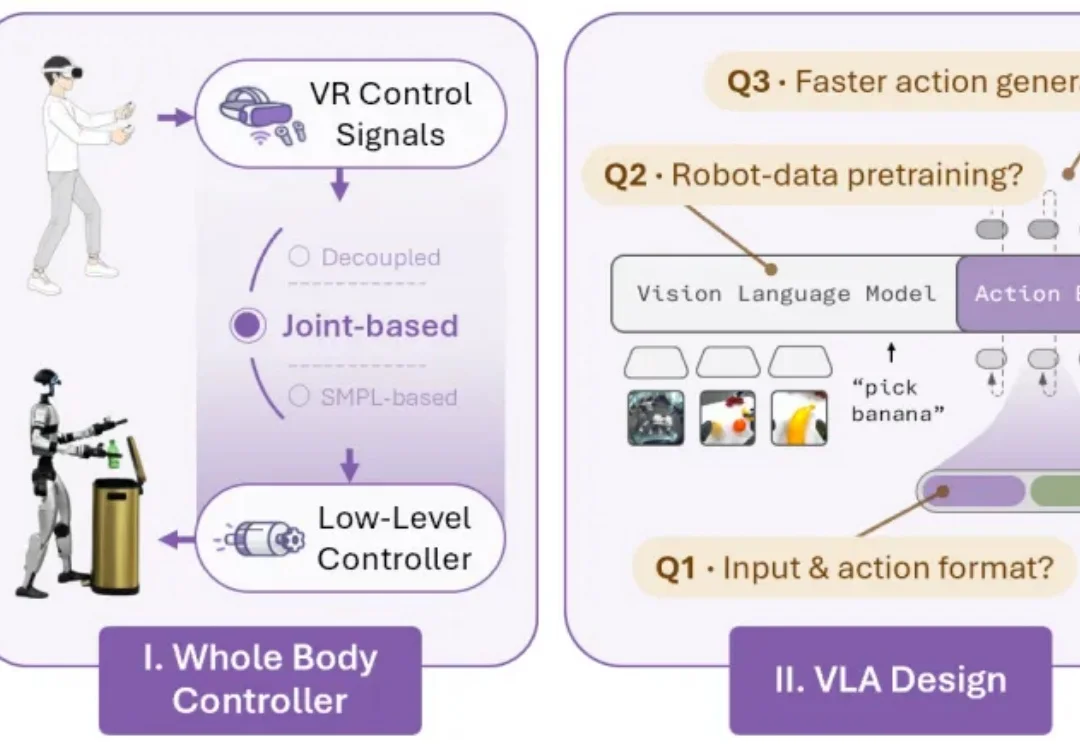
人类在日常生活中协调全身来完成移动操作任务:打开垃圾桶时会踩下踏板,从低处拿东西时需要下蹲,推车时需要同步协调手臂抓握和腿部移动。对试图复刻人类能力的人形机器人来说,身体不应只是「手臂 + 移动平台」,而应是一个能协调手、腰、腿、脚共同完成任务的运动整体。

年度最危险论文发了!英伟达打破20年封印,让AI亲手造出更狠的「考官」淘汰自己。无休止的自我进化一旦开启,2028年ASI降临真不是玩笑。
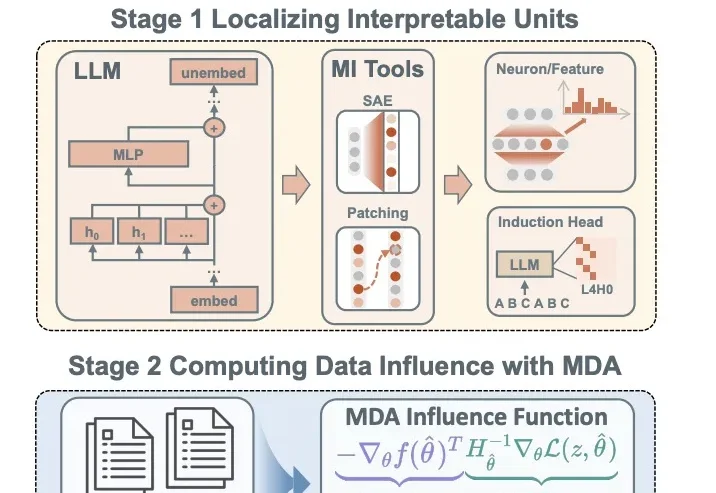
近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。
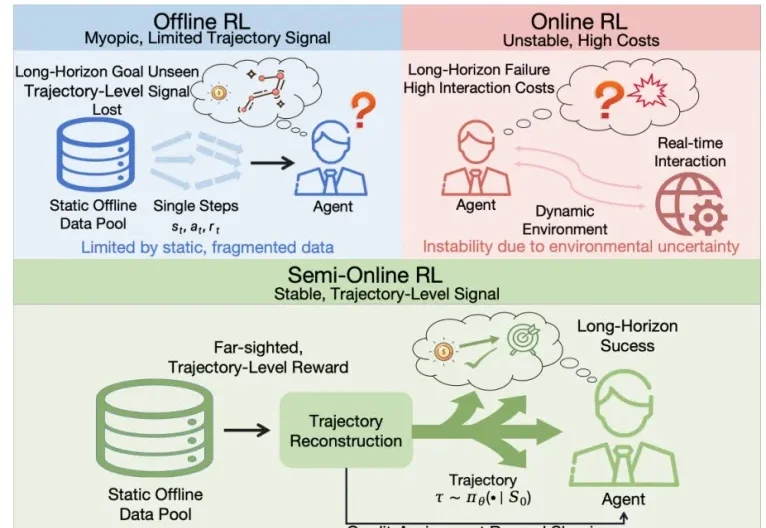
想训练能自动操作手机的GUI(图形用户界面)智能体,总会遇到两难困境:

这篇来自 Interlatent(一家聚焦具身智能后训练与部署的早期创业公司) 的文章,试图从第一性原理出发,把现代 AI 机器人技术重新讲清楚:一个机器人到底如何理解世界,如何生成动作,又为什么会在数据、延迟和泛化上遇到如此多的困难。
Fireworks AI的联合创始人兼CTO、PyTorch核心维护者Dmytro Dzhulgakov将整篇论文梳理成了10个概念,从最底层的GPU访存特性讲到最上层的在线自适应调度。DeepSeek这套方案真正的精髓在于系统工程和模型协同设计。

就在外界惊呼“AI快要接管纯数学研究”之际,一场限制条件极其严格、并由30位数学家以匿名方式进行评审的数学测试,却揭开了AI数学能力的另一面:AI不仅会幻觉、会跳步骤,甚至还把数学家论文里的关键论证几乎原样照搬,却忘了注明引用。
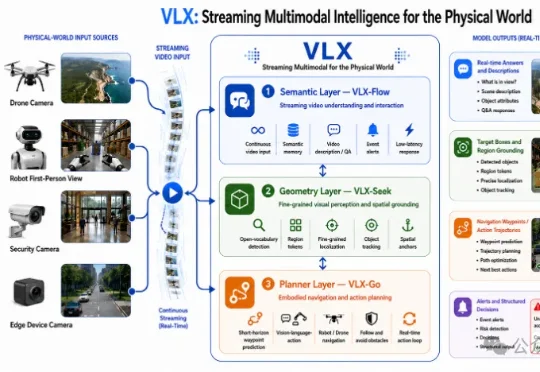
刚刚,Om AI发布全球首个面向物理世界的端侧流式多模态模型系列——VLX。VLX主打真实世界的端侧与具身场景,总共三款模型,三天连发:这三款模型连起来,不仅构成了多模态模型持续感知、精准定位、行动决策的能力闭环。
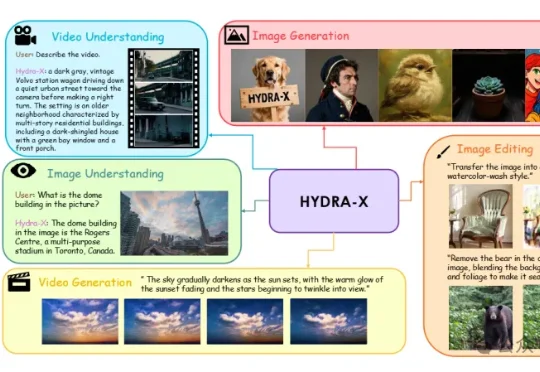
南大王利民团队&腾讯混元的HYDRA系列(HYDRA,HYDRA-X)工作挑战了这个惯例,用一个基于ViT的统一视觉Tokenizer,帮助原生多模态模型更好地“看懂”和“创作”。训练一个基于ViT的Unified Tokenizer,使其同时具有理解和生成的能力,进而同时作为理解和生成的Autoencoder,来支持原生多模态模型(Unified Multimodal Models)的训练。

刚刚,DeepSeek V4 进行了一次更新。新推出了投机解码(Speculative Decoding)框架 DSpark,并同步开源了支撑该版本的全栈推测性解码框架 DeepSpec。DeepSeek-V4-Pro-DSpark 并非全新架构模型,而是在 DeepSeek-V4-Pro 基础上引入了推测性解码模块。此次更新的重点在于工程落地,而非模型能力本身的迭代。

Jay 发自 凹非寺 量子位 | 公众号 QbitAI AI能否真正产生价值?组织因素的权重是个人的两倍。 也就是说,你AI用得不好,三分之二的锅得公司背。 这个反直觉洞察,出自微软一年一度的《Wor

来自至知创新研究院(IQuest Research)、中国人民大学高瓴人工智能学院、KAUST等机构的研究团队提出了FORT,一个面向Deep Search Agent的shortcut-resistant training-data synthesis framework。