# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在迈向通用人工智能的道路上,我们一直在思考一个问题:现有的 Image Editing Agent,真的「懂」修图吗?
大多数基于 LLM/VLM 的智能体,本质上更像是一个「盲目的指挥官」。它们能流利地写出修图代码或调用 API,但在按下回车键之前,它们看不见画布上的变化,也无法像人类设计师那样,盯着屏幕皱眉说:「这张对比度拉太高了,得往回收到一点。」这种感知与决策的割裂,直接导致了「指令幻觉」,或者说模型在进行盲目的「脑补」。由于缺乏视觉反馈,模型往往凭空想象下一步操作,导致结果与用户的初衷南辕北辙。
此外,在传统强化学习中经常依赖于静态的奖励模型。随着模型的不断训练,它很容易学会如何「讨好」这个固定的打分器,导致 Reward Hacking——即分数很高,但审美并没有真正提升。
为了打破这一僵局,JarvisEvo 应运而生。它不仅仅是一个连接 Adobe Lightroom 的自动化工具使用者,更是一次大胆的探索:探索 Agent 如何通过「内省」,真正实现自我进化。


JarvisEvo 的核心哲学在于模仿人类专家的慢思考模式。一个资深修图师的工作流永远是闭环的:观察原图 -> 构思 -> 尝试调整 -> 观察结果 -> 评估/反思 -> 再调整。我们将这一直觉转化为三大技术支柱:
iMCoT:让思维链「长出眼睛」
传统的思维链 (CoT) 是纯文本的独角戏。JarvisEvo 引入了 iMCoT (Interleaved Multimodal Chain-of-Thought),将视觉反馈强行插入推理循环。

SEPO:左手画图,右手打分
这是 JarvisEvo 最「性感」的设计。既然外部奖励模型容易被 Hack,那为什么不让 Agent 自己训练自己的审美?我们提出了 SEPO (Synergistic Editor-Evaluator Policy Optimization),让模型在训练中分饰两角:
这就形成了一种类似 GAN 但更复杂的协同进化:编辑者为了拿高分,必须提升修图质量;评估者为了不被人类专家「打脸」,必须提升鉴赏能力。为了防止模型「作弊」(即模型发现只要生成「100 分」的文本就能降低 Loss),我们设计了 SLM (Selective Loss Masking) 机制。这相当于老师在改卷时,遮住了学生自己写的「我给自己打满分」那一行,迫使学生只能靠前面的解题过程(推理和工具使用)来真正赢得高分。
On-Policy Reflection:从错误中提炼智慧
JarvisEvo 的第三个杀手锏是它的反思机制。
在 Stage 2 的训练中,我们构建了一个自动化流水线:当模型偶然修出了一张好图(高分轨迹),而之前某次尝试失败了(低分轨迹),系统会立刻捕捉这组对比。
通过引入「导师模型」(如 Gemini/GPT-4),我们让系统分析:「刚才那次为什么失败?是因为白平衡参数太激进了吗?」
这种生成的反思数据 (Reflection Data) 被用于第三阶段的微调。最终,JarvisEvo 习得的不仅是「如何修图」,更是「当修坏了时如何自救」。
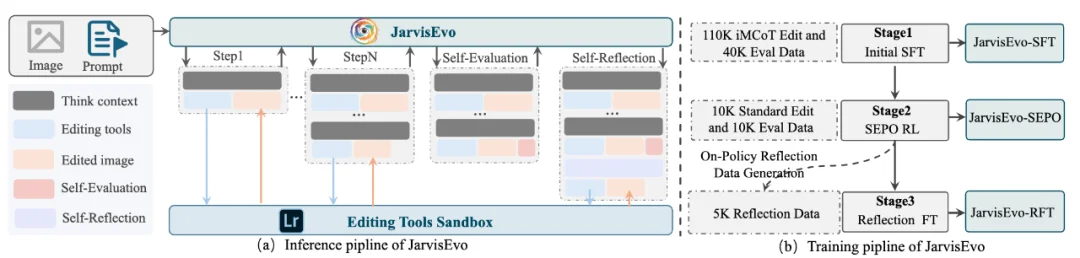
硬核工程:ArtEdit 数据集与训练流水线
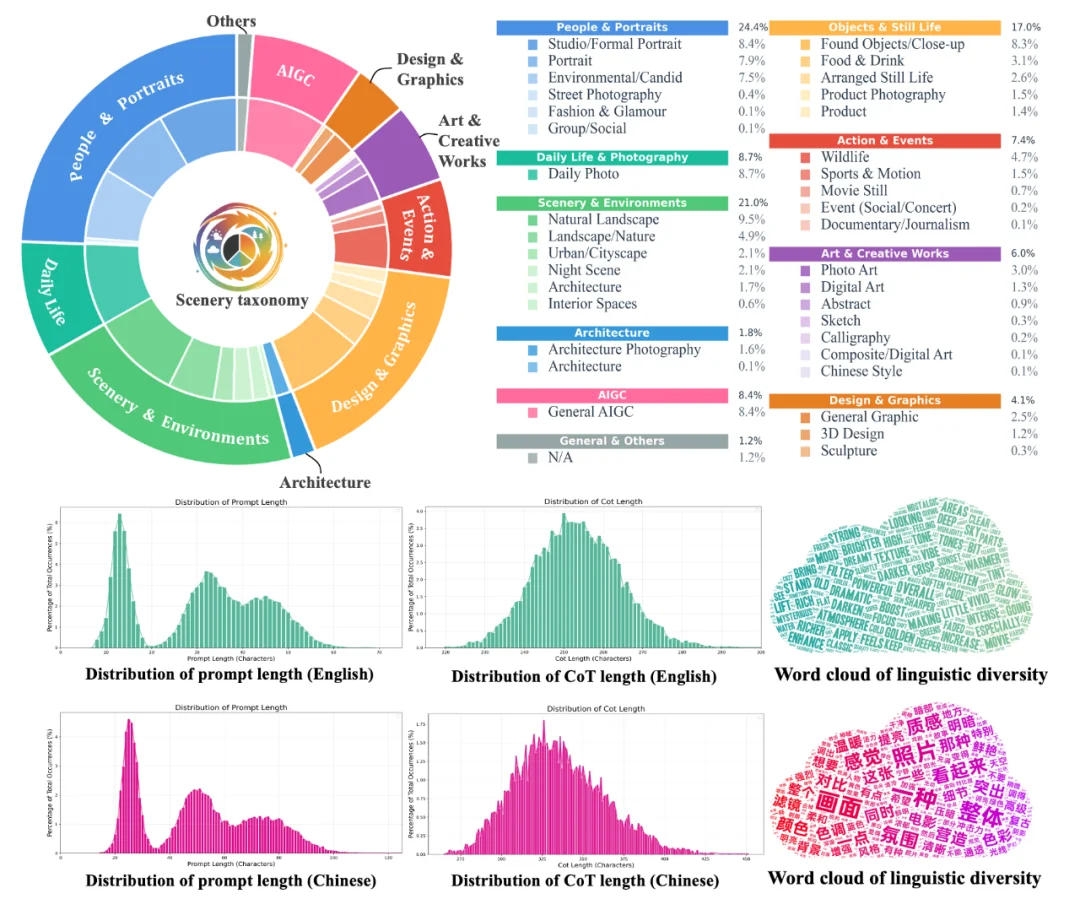
为了支撑这套逻辑,我们没有使用通用的微调数据,而是从零构建了 ArtEdit:
我们的训练并非一蹴而就,而是采用了类似人类学习的三阶段课程 (Curriculum Learning):
ArtEdit-Bench 评测结果

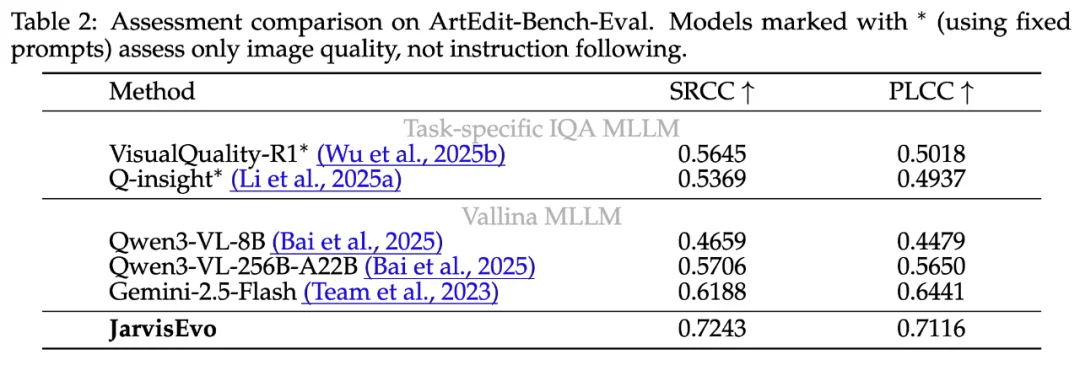
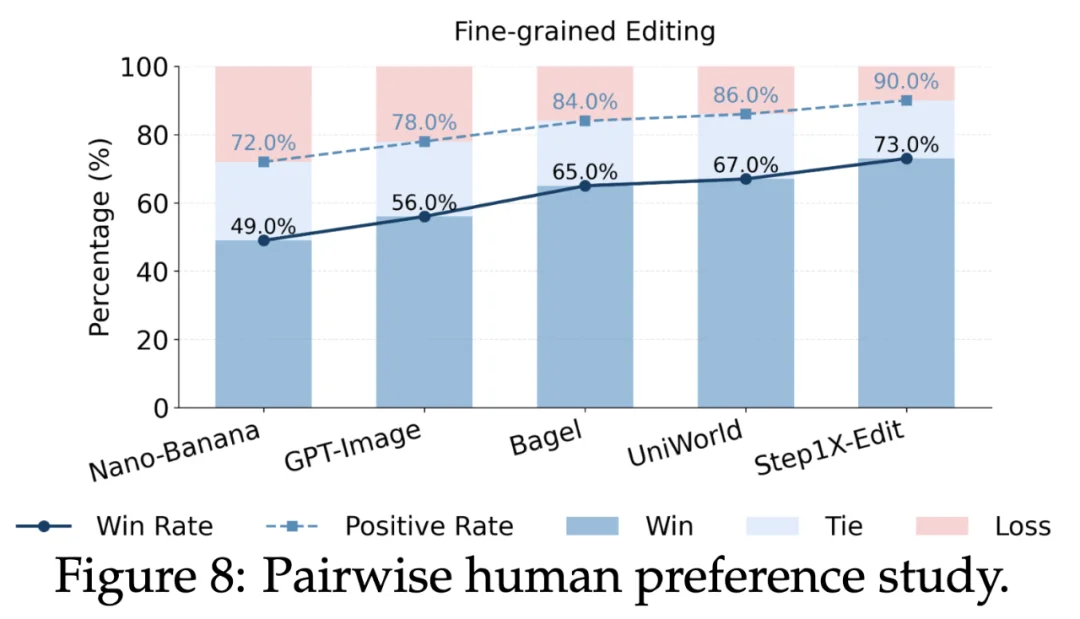
在严苛的 ArtEdit-Bench 评测中,JarvisEvo 展现了统治力:
视觉效果
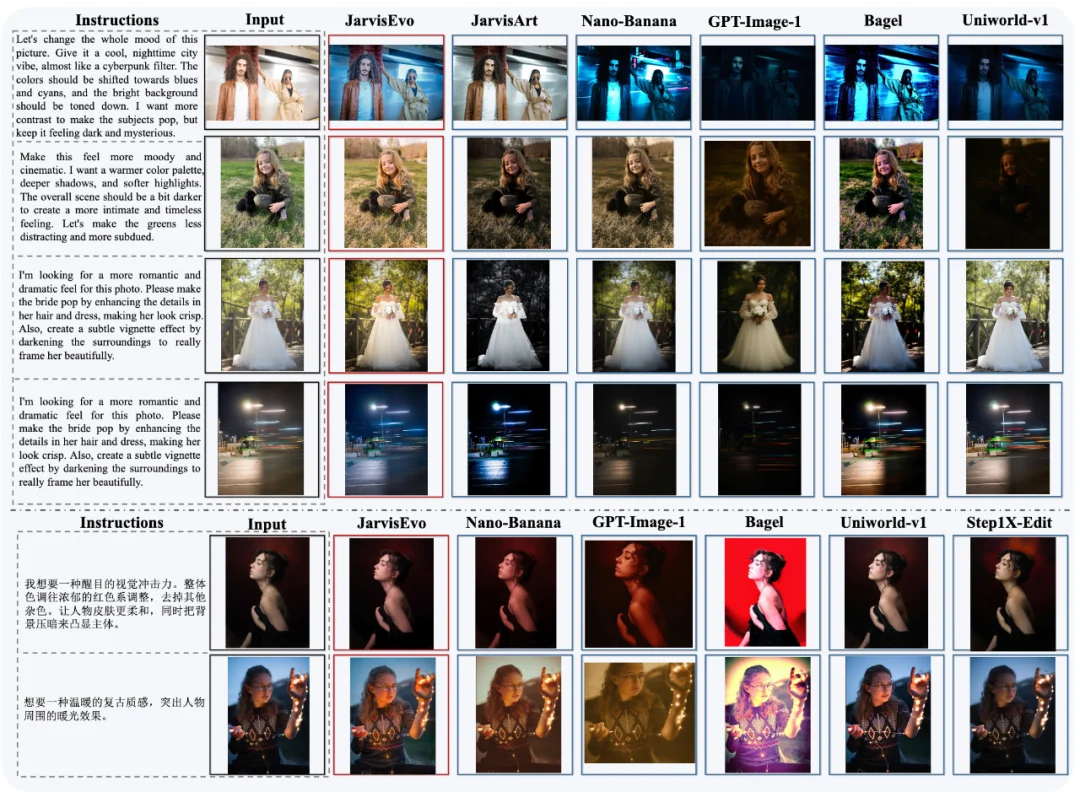
在视觉效果上,JarvisEvo 专为细粒度专业调色而生。得益于其深度的意图理解、多模态推理以及独特的自我反思闭环,JarvisEvo 在处理复杂修图需求时,展现出了超越当前所有商业及开源 AIGC 模型的显著优势。
JarvisEvo vs. OpenAI X Adobe PhotoShop

出于好奇跑了一下 OpenAI 的新功能,虽然能调 PS,但感觉更像是 Workflow 的搭建,缺乏垂直数据的 Training。在我们的 Benchmark 上,论指令遵循和修图审美,目前的 JarvisEvo 表现明显还是要更好很多。
JarvisEvo 的意义远超图像编辑本身。 它验证了一种「Actor-Critic 协同进化」的通用范式。这种让模型在内部建立「自我批评家」,并通过多模态反馈不断修正行动路径的方法,完全可以复用到复杂代码生成、数学推理、机器人控制等需要长程规划的领域。
我们正在见证 Agent 从「听话的执行者」向「会反思的创作者」的惊险一跃。而 JarvisEvo,刚刚迈出了这一步。
文章来自于“机器之心”,作者 “机器之心”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
