
脸谱心智陆弘远团队ACL 2026新作:别再给模型叠加「高级词」了!模型更爱听「大白话」
脸谱心智陆弘远团队ACL 2026新作:别再给模型叠加「高级词」了!模型更爱听「大白话」有这样一种 “模型玄学”:明明是同一个 Prompt,仅仅换一种说法,模型的回答可能就天差地别。
来自主题: AI技术研报
9583 点击 2026-04-17 08:39
 搜索
搜索
有这样一种 “模型玄学”:明明是同一个 Prompt,仅仅换一种说法,模型的回答可能就天差地别。
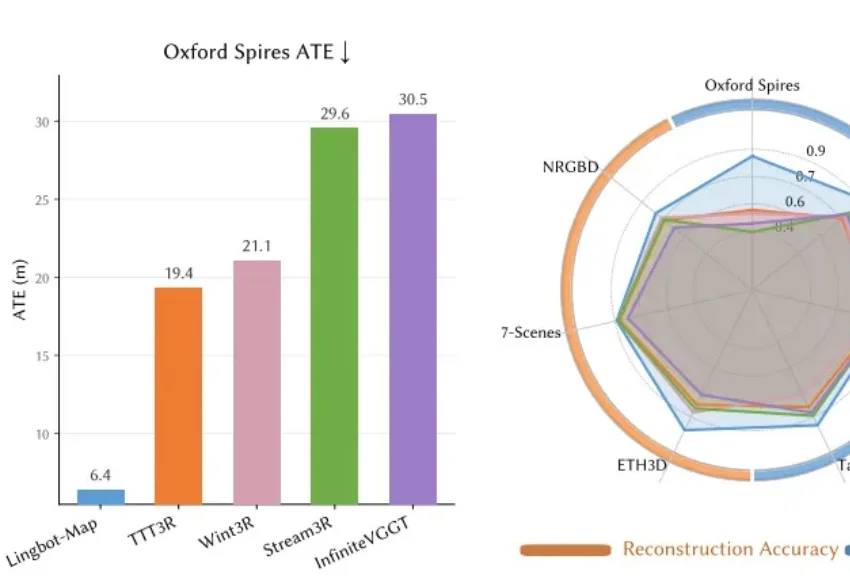
蚂蚁灵波,下了盘大棋。

我和周围朋友都特别爱玩《星露谷物语》。

质量和成本只能二选一?通过大脑+小脑分层、场内+场外双轮驱动,数据堂给出了具身智能数据难题的解。
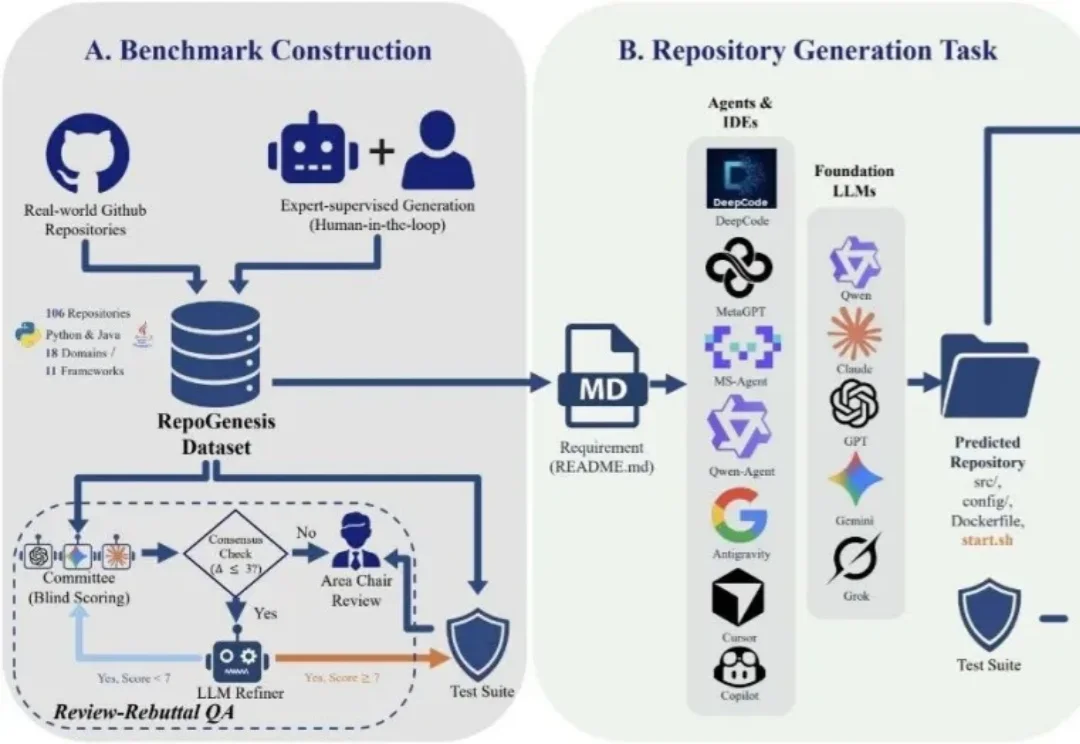
大模型写代码这件事,越来越像「既能写片段,又离真实工程差一截」。

当强化学习后训练的大规模 rollout 已经被证明能够提升图像生成模型的偏好对齐能力,推理负担就成了制约训练速度的核心瓶颈。来自 NVIDIA、港大和 MIT 的团队提出的 Sol-RL,通过「FP4 先探索、BF16 再训练」的后训练框架,将达到等效 reward 水平的收敛速度最高提升到 4.64x,在训练速度与对齐效果之间给出了一条更具工程可行性的解法。
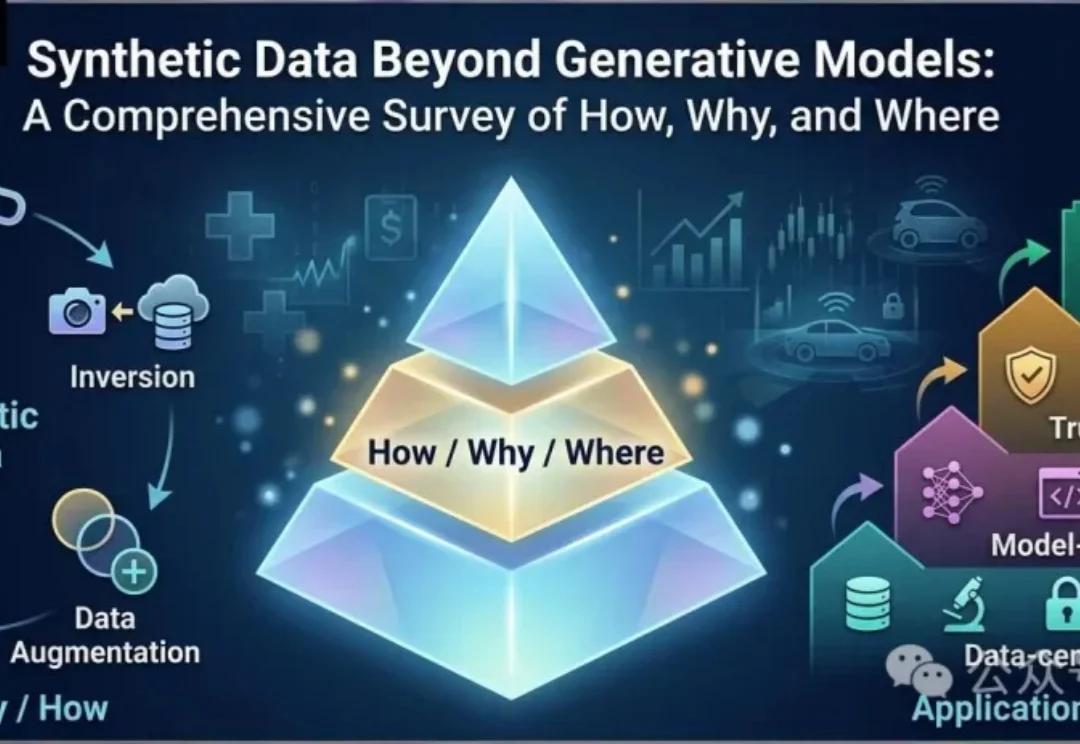
最新研究提出合成数据的全新分类框架,突破「生成模型=合成数据」的传统认知,涵盖反演、仿真与数据增强等方法,并按应用层次划分为数据中心AI、模型中心AI、可信AI和具身AI。

为什么你的“AI优先”战略可能大错特错?一文读懂。

如何工业化生产AI漫剧。
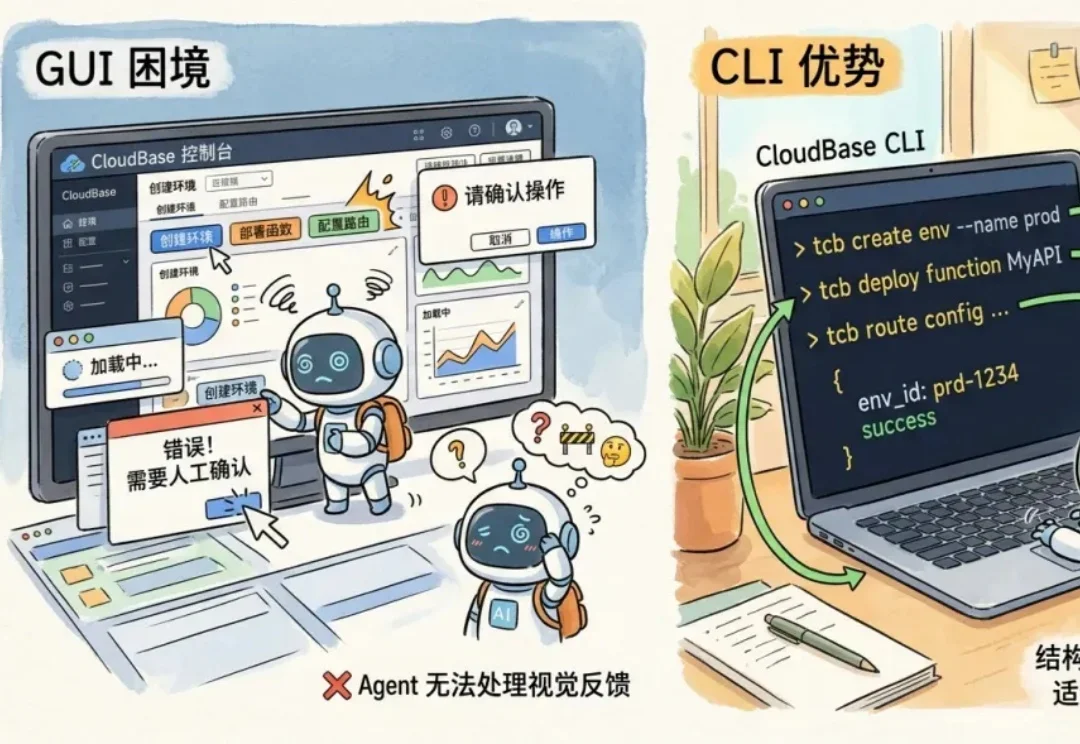
我们很荣幸地宣布 CloudBase CLI V3 正式上线,这是一个面向 AI Agent 重新设计的 CloudBase 命令行工具。

一个在 AI 社区广泛流传的架构思路,正在让大量团队走弯路。

全球最强编程模型,中国造。
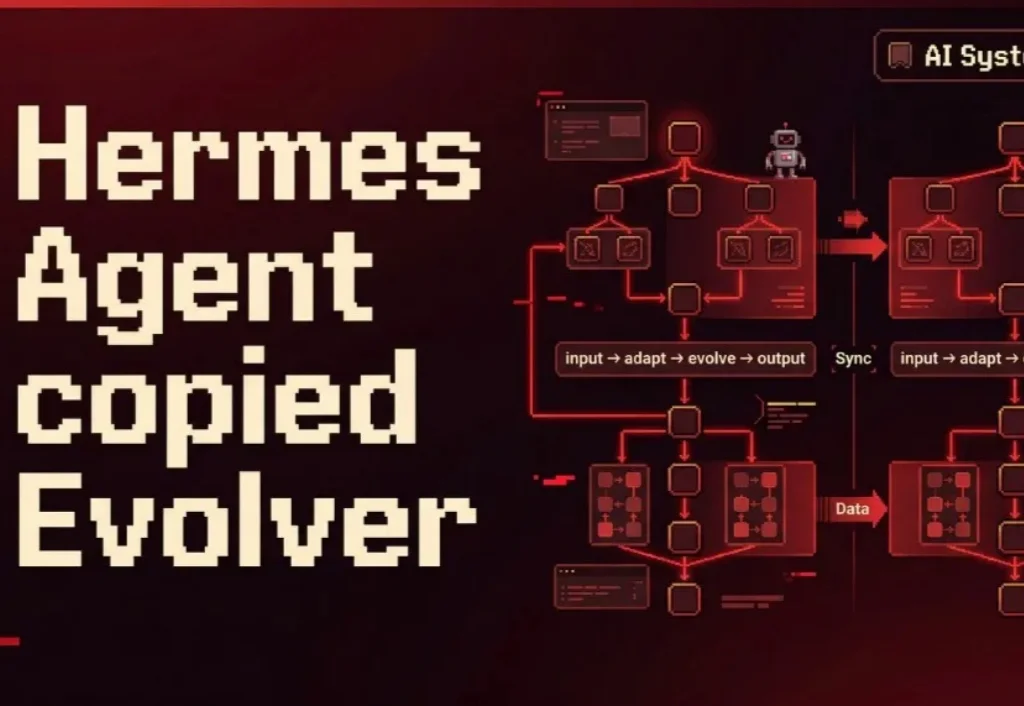
Hermes Agent最近在AI圈彻底火了。
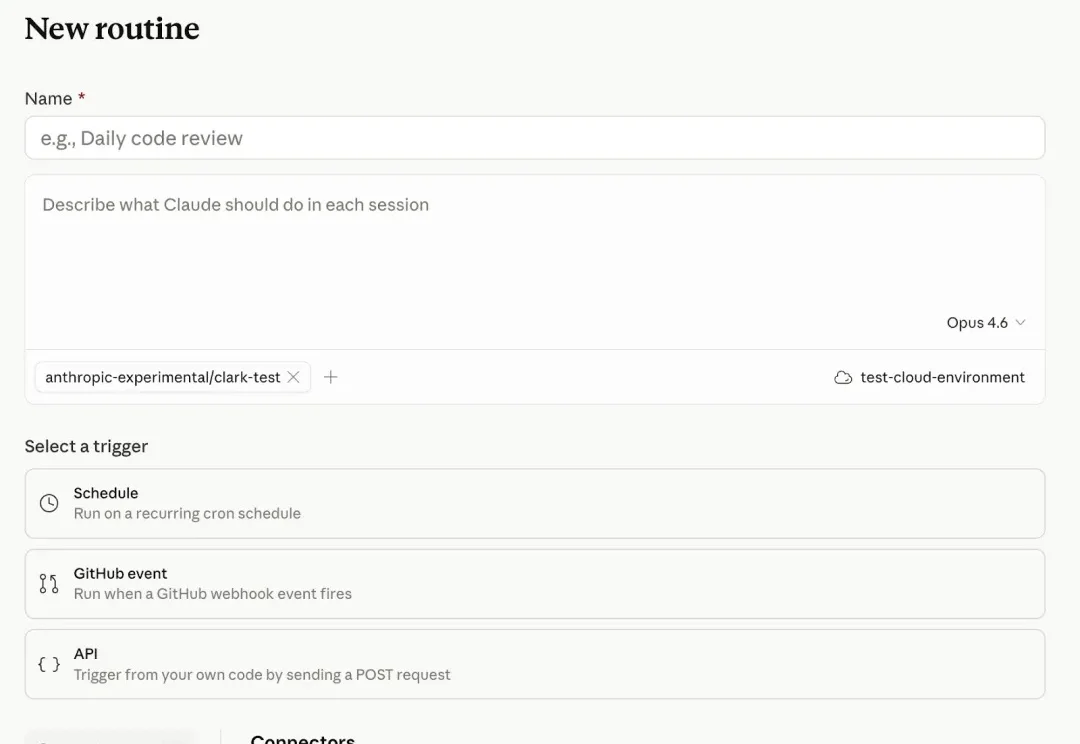
Claude Code 今天上了一个新能力:Routines,面向 Pro、Max、Team 和 Enterprise 用户开放
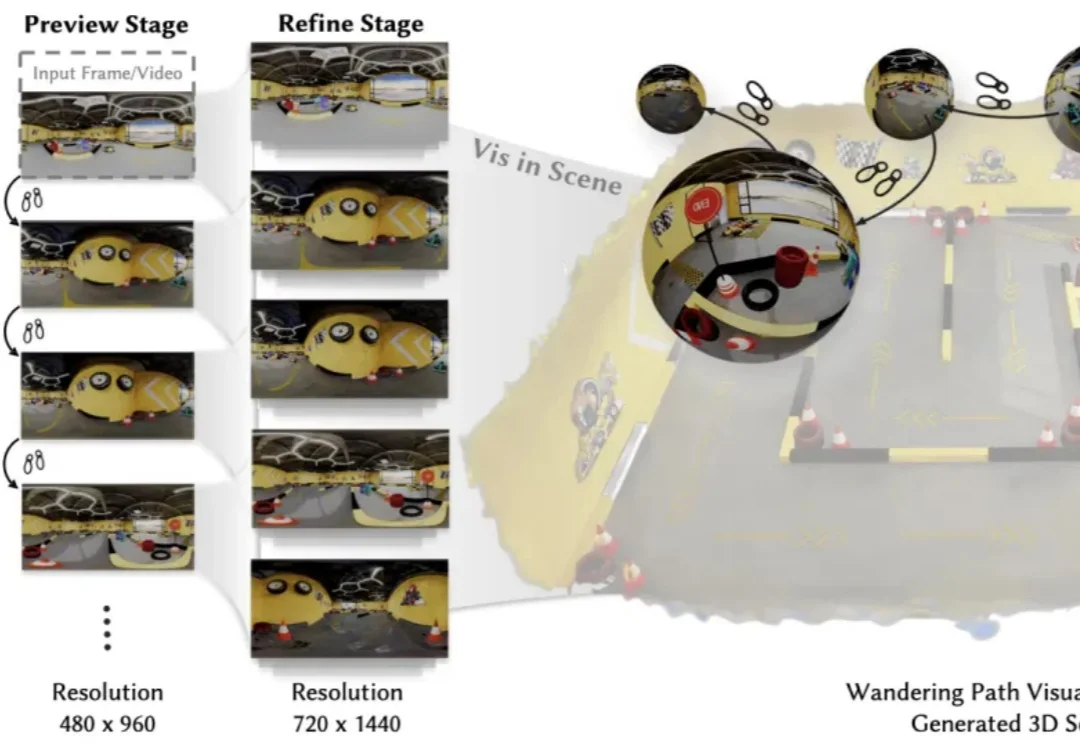
在生成式视频快速发展的今天,模型已经能够生成高质量的短视频片段,但一个更具挑战性的问题正逐渐成为研究焦点:
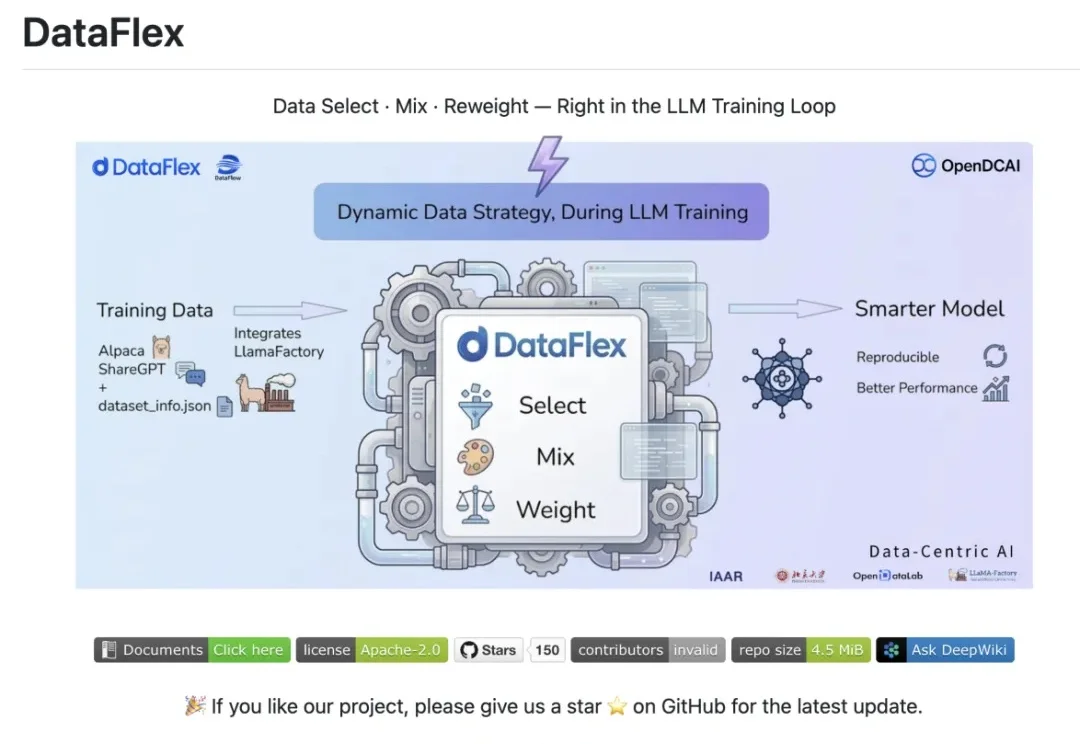
当大模型训练进入深水区,竞争的关键已经不再只是「模型参数怎么调」,而逐渐转向一个更核心、也更难系统解决的问题:模型在训练过程中究竟看到了什么数据、以什么比例看到、哪些样本应该被更频繁地学习。
眼瞅着四月马上过半,OpenClaw 刮起的这股「养虾风」依然没有停歇。

Anthropic正式推出了Claude Code的自动化任务功能Routines,目前处于研究预览阶段。只要配置好一次提示词、代码仓库和连接器,Claude就能在云端全自动干活了。这些任务全部运行在Anthropic的云端基础设施上,意味着完全不需要你一直开着电脑,哪怕你下班关机,它也能按时帮你处理代码积压、审查代码,甚至随时响应云端事件。
上周,我们发布了 MMX-CLI,让 Agent 可以直接通过命令行调用 MiniMax 的全模态能力。命令行是 Agent 在终端中完成工作的常见形态,但用户的工作并不只发生在命令行内,电脑上还有大量任务藏在命令行无法触达的本地软件、内部系统和图形界面中。
拍一圈照片,就能生成一个可交互的 3D 世界,已经不是什么新鲜话题了。但问题是如何把一个大世界塞进普通人的手机浏览器里。
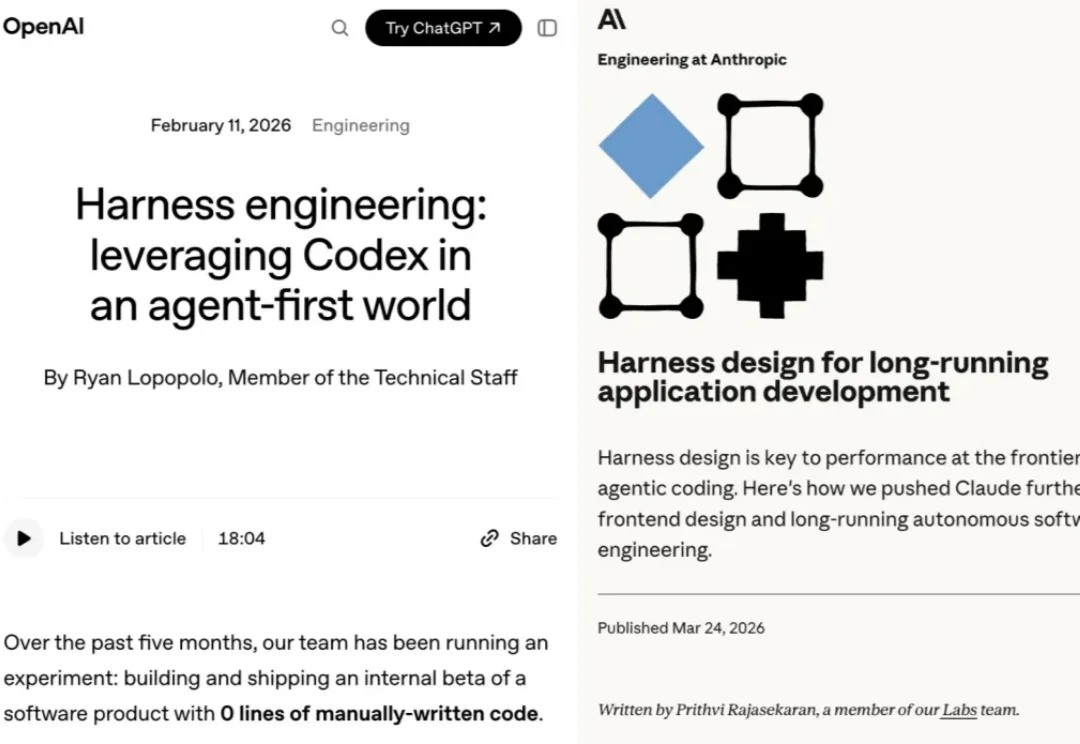
026 年初,OpenAI 和 Anthropic 几乎同时发布了关于 Harness 的技术实践文章,LangChain 工程师 Viv 给出了一个简洁的公式来概括这个理念:Agent = Model + Harness。模型提供智能,Harness 让这个智能能真正投入生产。

LangChain 联合创始人 Harrison Chase 上周发文,说透了 AI Agent 领域一个还没有多少人讲清楚的问题:外壳和记忆是同一件事,你没法分开。

近年来研究者们一直在试图通过仿真环境批量产出具身训练数据。
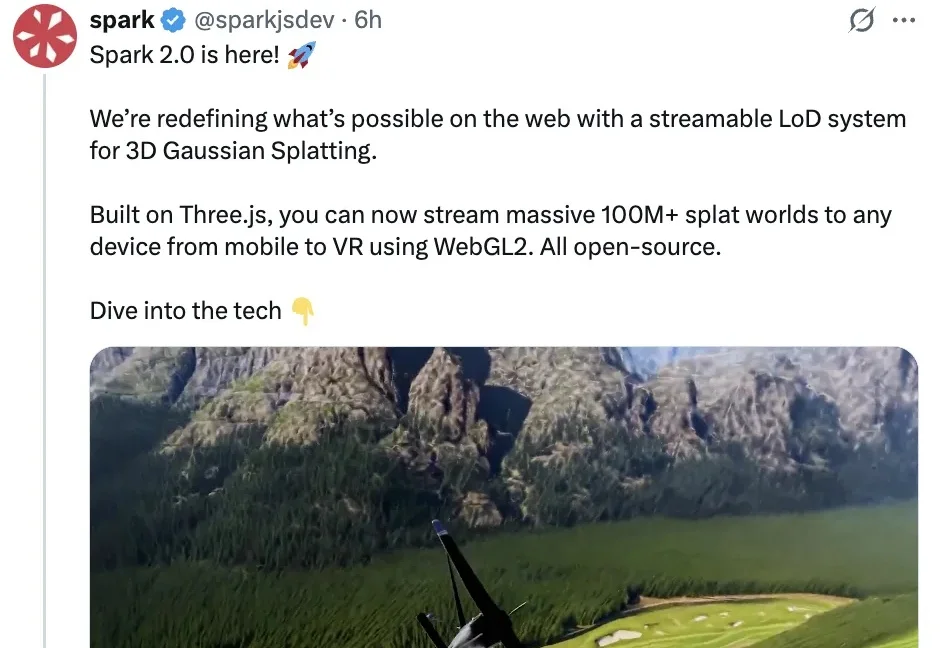
距离新模型Marble 1.1&1.1-Plus发布不到一个周,李飞飞空间智能独角兽World Labs再度传来新消息—— 开源3D高斯溅射渲染引擎Spark 2.0。

太疯狂了!Anthropic刚刚发布Claude Code新版,上线神秘功能Routine:支持定时、API、GitHub三路触发,直接变身「云端员工」。更刺激的是,Opus 4.7即将本周闪电发布,直接跨界硬刚Adobe、Figma。

随着新一代主动执行型 Agent(如 OpenClaw、Hermes Agent 等)的爆发,AI 正经历从「被动工具」向「具备自我演化(Self-Evolving)能力的智能体」的范式跃迁。然而,受限于上下文窗口极限与记忆缺失,现有 Agent 难以在复杂任务中实现经验的复用与自我进化。
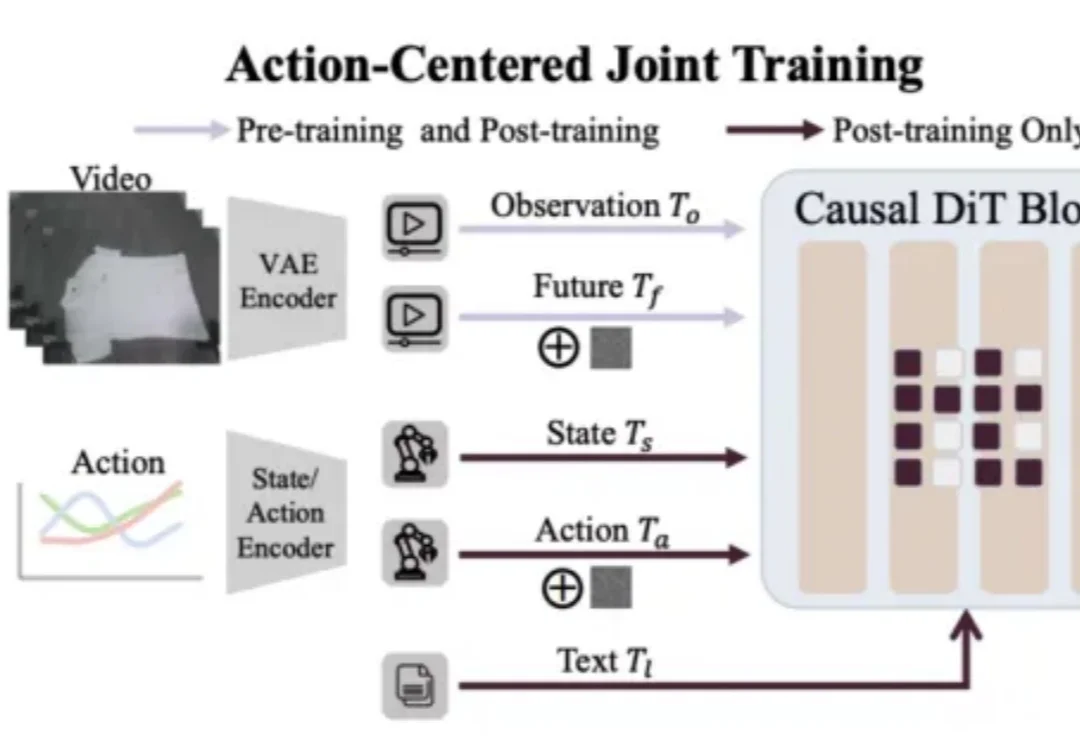
最近,具身智能圈被 Generalist CEO 的一篇长文《Going Beyond World Models & VLAs》刷屏。文章抛出了一个看似振聋发聩的观点:目标远比工具标签更重要。与其陷入 “我们到底是在做 VLA(视觉 - 语言 - 动作模型)还是世界模型(World Model)” 的教条之争,不如回归本源:让机器高效、准确地作用于物理世界。
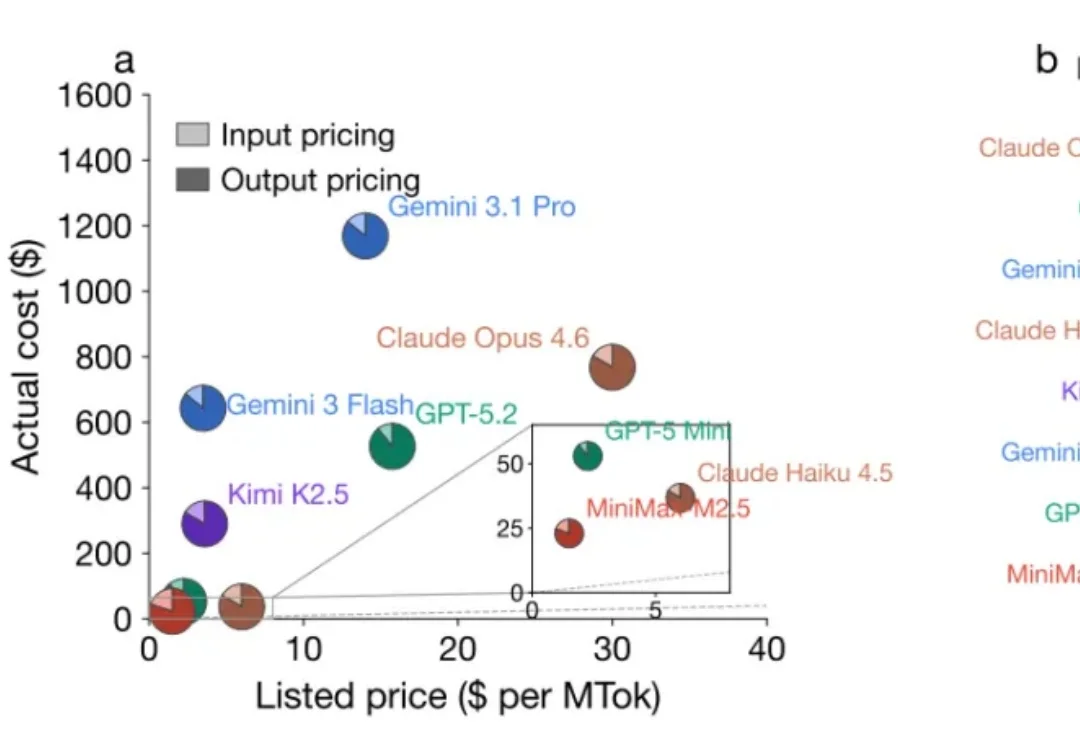
在选择使用大模型 (LLM) 时,除了模型性能强弱,价格也是一个重要指标。人们通常会用大模型的 API 定价更贵或更便宜,来比较模型的价格高低。但事实上,定价低的模型真的比定价高的模型使用起来更便宜吗?

最近,GitHub上Hermes Agent火了,仅仅几周的时间,从0涨到了7万多Star。

代码大模型会写代码,这件事已经不新鲜了。