# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最新研究提出合成数据的全新分类框架,突破「生成模型=合成数据」的传统认知,涵盖反演、仿真与数据增强等方法,并按应用层次划分为数据中心AI、模型中心AI、可信AI和具身AI。
随着基础模型规模不断扩大,真实数据在成本、隐私、质量和可控性上的限制,正逐渐成为 AI 继续发展的关键瓶颈。
尤其是在医疗等高价值场景中,真实数据本身难以获取,「依赖数据自然产生」的范式正在失效。
在这样的背景下,合成数据正在从「真实数据的补充」,转变为“主动构造高质量训练与评估数据的核心机制”。
基于对300+篇代表性文献的系统梳理,南洋理工大学、清华大学、四川大学、中山大学的研究人员提出了一个统一的How / Why / Where框架,重新定义了合成数据的方法边界,并从应用层面给出了更完整的发展路径。
论文链接:https://www.techrxiv.org/users/1016218/articles/1378802-synthetic-data-beyond-generative-models-a-comprehensive-survey-of-how-why-and-where
论文资源库:https://github.com/Egg-Hu/Awesome-Synthetic-Data-Generation
首先,合成数据方法该如何分类?
很多工作默认认为「合成数据 = 生成模型」,该综述重新定义了「数据合成」的方法边界,跳出「合成数据 = 生成模型」的单一视角。也就是说,合成数据并不等同于“用生成模型造数据”,反演、仿真、增强等方式也都应被纳入合成数据的范畴。
下表给出了整体分类框架:

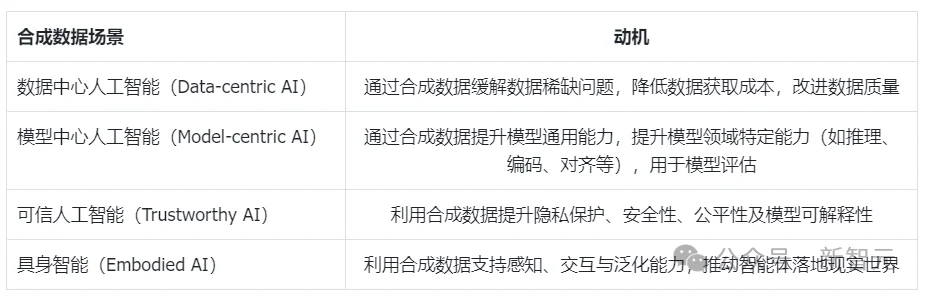
第二,合成数据应用在哪些核心场景?
不同于以往按具体任务或领域划分的方式,本文从更高层次出发,将合成数据的应用组织为一条逐步演进的能力路径。
在这一框架下,最基础的是数据中心人工智能(Data-centric AI),其核心目标是解决真实数据稀缺、获取成本高以及隐私受限等问题,通过合成数据扩展训练集并提升数据质量,为模型训练提供稳定的数据基础。
在此之上,随着数据可获得性的提升,研究重点逐渐转向模型中心人工智能(Model-centric AI),此时合成数据不仅用于补充数据,还被用于能力注入,例如提升模型的推理、编码与对齐能力,并构建可控的评测基准。
进一步地,随着模型能力的增强,对系统可靠性的需求不断提高,催生了可信人工智能(Trustworthy AI),在这一阶段,合成数据被广泛用于隐私保护、安全防护、公平性提升以及模型可解释性分析。
最后,合成数据的应用从数字空间走向现实世界,对应的是具身智能(Embodied AI),其目标是支持感知、交互与泛化能力,使智能体能够在复杂物理环境中进行决策与行动。下表给出了整体结构(具体细节可参考原论文):
进一步地,文章将上述四类应用场景细化到了 30+ 个具体机器学习任务层级,从而构建起从宏观分类到具体问题的系统化映射。
如下图所示,每一类场景都被进一步拆解为多个典型问题:例如,在数据中心人工智能中,涵盖了零/少样本学习、联邦学习、无数据学习、数据蒸馏等任务;在模型中心人工智能中,则进一步细化为模型通用能力提升,以及推理、编码、指令对齐等特定能力的增强,同时也包括基于合成数据的模型评测任务;
在可信人工智能中,主要聚焦于隐私保护、模型攻击、安全防护、长尾学习与可解释性等任务;而在具身智能中,则进一步延伸到感知、交互以及跨场景泛化等面向真实环境的任务。

最后,合成数据面临哪些挑战与机遇?
尽管在方法体系与应用落地方面已经取得了显著进展,但合成数据仍处于快速发展阶段,仍然存在一系列关键挑战有待解决。
下图给出了该综述的总体整理框架,具体细节可参考原文。

这篇综述最值得关注的地方,不只是整理了现有方法,更重要的是它改变了我们理解合成数据的方式: 合成数据不再只是生成模型的一个应用方向,而正在成为连接数据、模型、评测与真实世界交互的新型基础设施。
如果说过去AI的竞争核心是「谁拥有更多真实数据」,那么未来很可能会变成「谁能更高效、更安全、更可控地生成高价值数据」。
参考资料:
https://www.techrxiv.org/users/1016218/articles/1378802-synthetic-data-beyond-generative-models-a-comprehensive-survey-of-how-why-and-where
文章来自于"新智元",作者 "LRST"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
