
AI安全得查祖宗三代?Anthropic登Nature揭秘大模型潜意识传染
AI安全得查祖宗三代?Anthropic登Nature揭秘大模型潜意识传染AI模型只看了一串纯数字序列,就能继承另一个模型的危险偏好,即使删掉敏感词没有用,合成数据时代最隐蔽的安全裂缝,被撕开了。
来自主题: AI技术研报
8725 点击 2026-04-17 08:40
 搜索
搜索
AI模型只看了一串纯数字序列,就能继承另一个模型的危险偏好,即使删掉敏感词没有用,合成数据时代最隐蔽的安全裂缝,被撕开了。
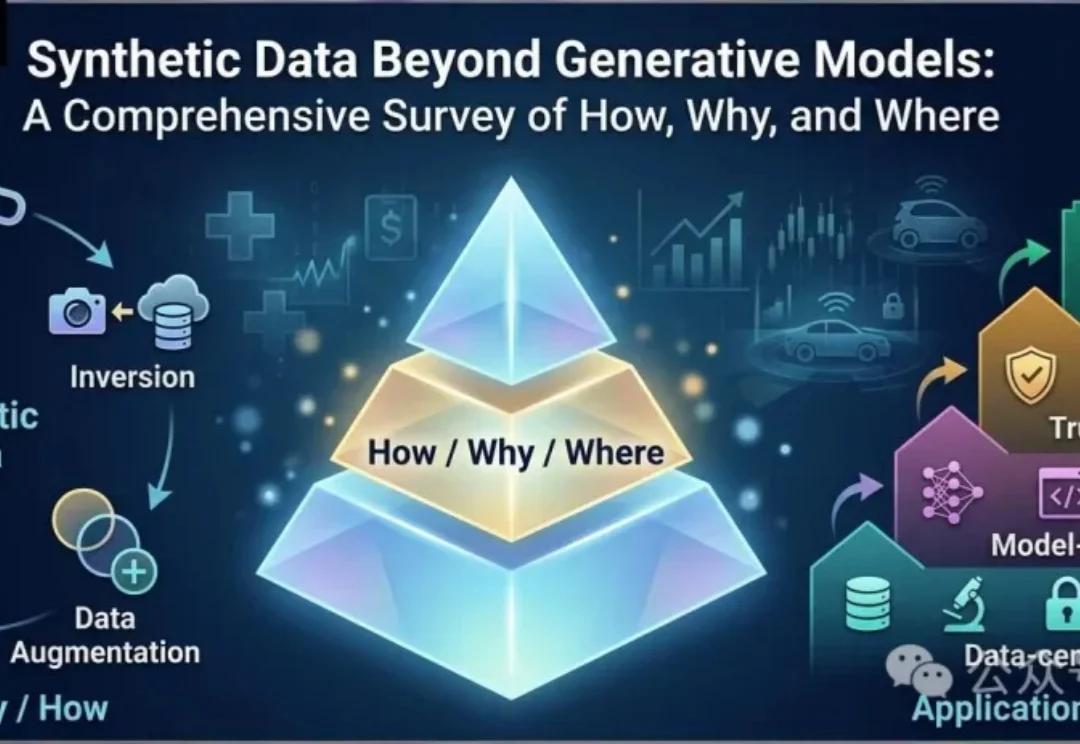
最新研究提出合成数据的全新分类框架,突破「生成模型=合成数据」的传统认知,涵盖反演、仿真与数据增强等方法,并按应用层次划分为数据中心AI、模型中心AI、可信AI和具身AI。

从大模型智能的“语言世界”迈向具身智能的“物理世界”,仿真正在成为连接落地的底层基础设施。
具身智能赛道又迎来新的融资消息。

ZP独家获悉,聚焦大模型合成数据领域的 AI 创业公司“数创弧光(DataArc)”已于近期连续完成种子轮及种子+轮融资,累计融资额达数千万元人民币,投后估值数亿元。两轮融资分别由英诺天使基金与东方富海领投,君科丹木、数字未来、启迪之星等一线财务投资机构,以及深智城、头部云厂商等产业资本共同参与。

数据集蒸馏是一种用少量合成数据替代全量数据训练模型的技术,能让模型高效又节能。WMDD和GUARD两项研究分别解决了如何保留原始数据特性并提升模型对抗扰动能力的问题,使模型在少量数据上训练时既准确又可靠。
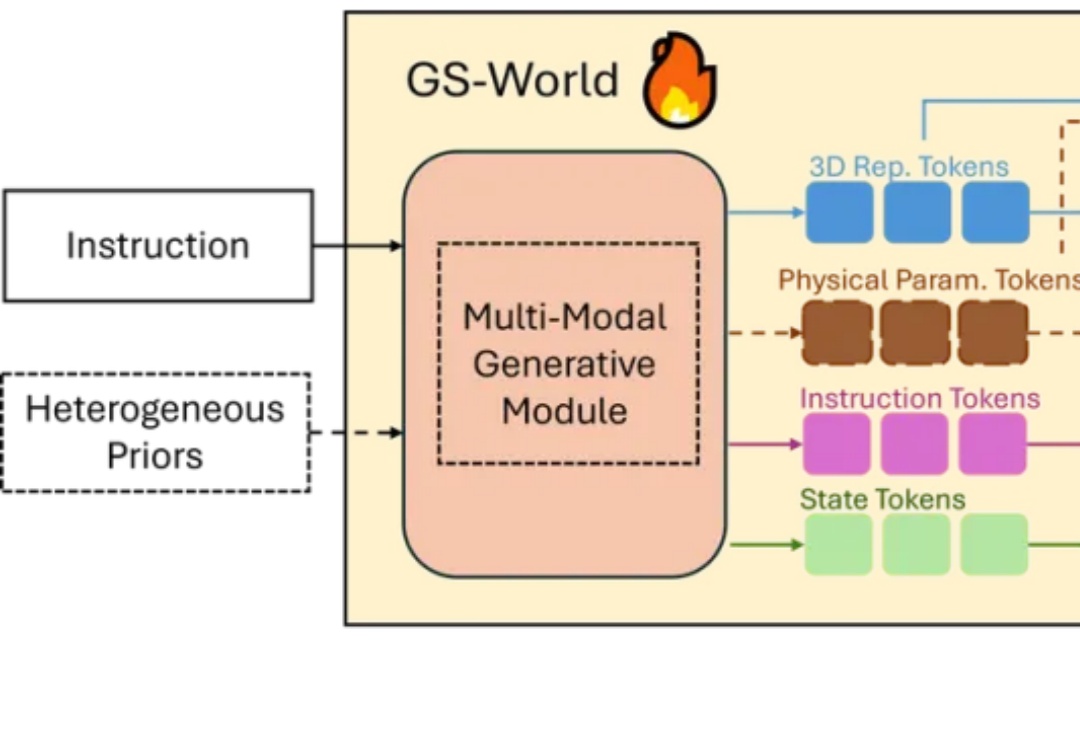
2025 年秋的具身智能赛道正被巨头动态点燃:特斯拉上海超级工厂宣布 Optimus 2.0 量产下线,同步开放开发者平台提供运动控制与环境感知 SDK,试图通过生态共建破解数据孤岛难题;英伟达则在 SIGGRAPH 大会抛出物理 AI 全栈方案,其 Omniverse 平台结合 Cosmos 世界模型可生成高质量合成数据,直指真机数据短缺痛点。
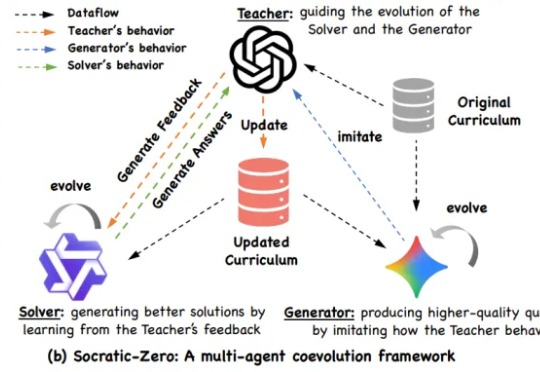
阿里巴巴与上海交通大学 EPIC Lab 联合提出 Socratic-Zero,一个完全无外部数据依赖的自主推理训练框架。该方法仅从 100 个种子问题出发,通过三个智能体的协同进化,自动生成高质量、难度自适应的课程,并持续提升模型推理能力。
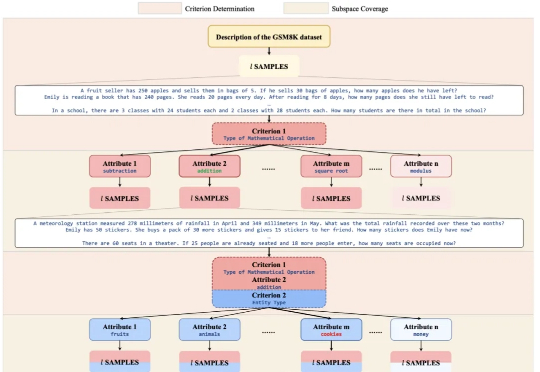
“TreeSynth” 就这样起源于作者们最初的构想:“如何通过一句任务描述生成海量数据,完成模型训练?” 同时,大规模 scalibility 对合成数据的多样性提出了新的要求。
开源赛道也是热闹了起来。 就在深夜,字节跳动 Seed 团队正式发布并开源了 Seed-OSS 系列模型,包含三个版本: Seed-OSS-36B-Base(含合成数据) Seed-OSS-36B-Base(不含合成数据) Seed-OSS-36B-Instruct(指令微调版)