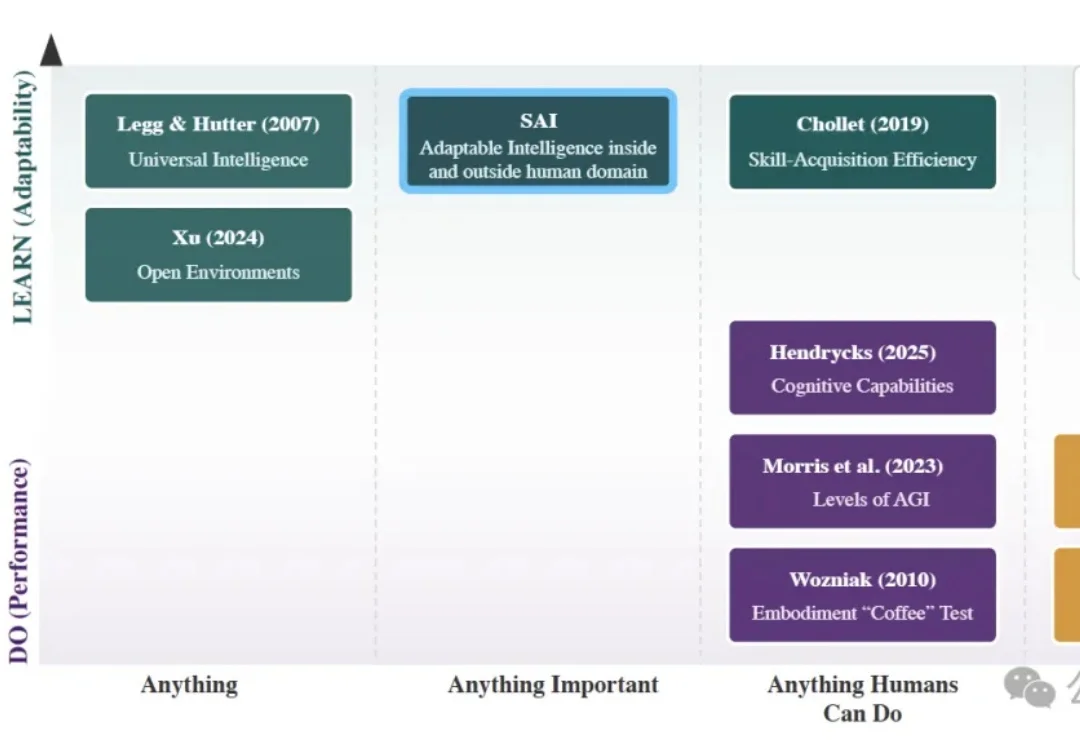
LeCun团队新论文:模仿人类智能搞AI,照猫画虎死胡同
LeCun团队新论文:模仿人类智能搞AI,照猫画虎死胡同AI圈追逐多年的通用人工智能(AGI),可能从一开始就走偏了。
来自主题: AI技术研报
8277 点击 2026-03-10 09:30
 搜索
搜索
AI圈追逐多年的通用人工智能(AGI),可能从一开始就走偏了。

在 AI 视觉生成领域,扩散模型(DM)凭借其强大的高保真数据生成能力,已成为图像合成、视频生成等多模态任务的核心框架。然而,预训练后的扩散模型如何高效适配下游应用需求,一直是行业面临的关键挑战。

自扩散模型提出以来,它不仅在图像、视频和音频生成方面取得了优异效果,也正逐渐成为解决图像复原、超分辨率、去模糊等逆问题的重要工具。

大神Karpathy又开源了新项目——一个能够自主进化的AI科研循环系统。这个项目名叫autoresearch,主打让智能体完全自主地搞科研,只要在Markdown文档里写好指令,剩下的流程全都由AI自动完成。
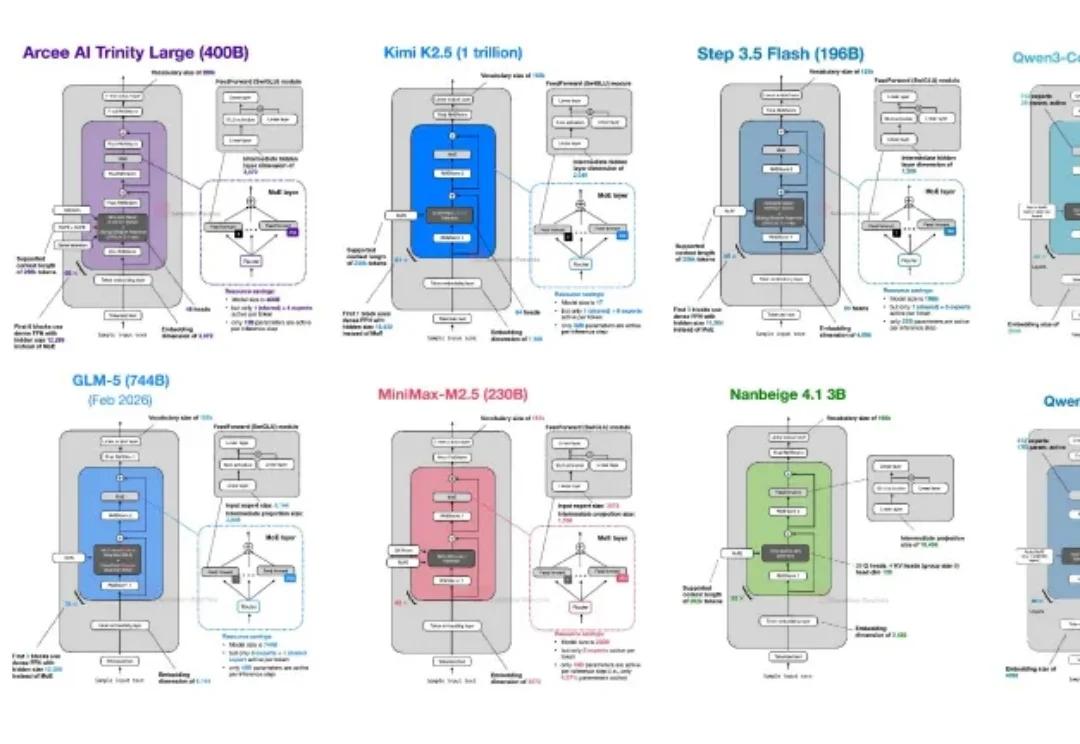
这两年,大模型大厂之间堪比军备竞赛。不论开源还是闭源阵营,为了在指标上领先对手,都在疯狂地卷 Scaling Law,卷算力,卷参数量,已经达到了近乎离谱的程度。

上面就是我最近日常的打字方式,在家、在公司、在咖啡厅都可以。
春节期间, Seedance 2.0 爆火,堪称现象级,这也再次把视频生成推上风口。前两天,字节跳动又携手北大、安努智能和 Canva 共同开源了具备实时生成能力的视频模型 Helios 家族。该系列包含了 Helios-Base、Helios-Mid 与 Helios-Distilled 三个版本,全面覆盖了 T2V、I2V、V2V 以及交互式生成任务。
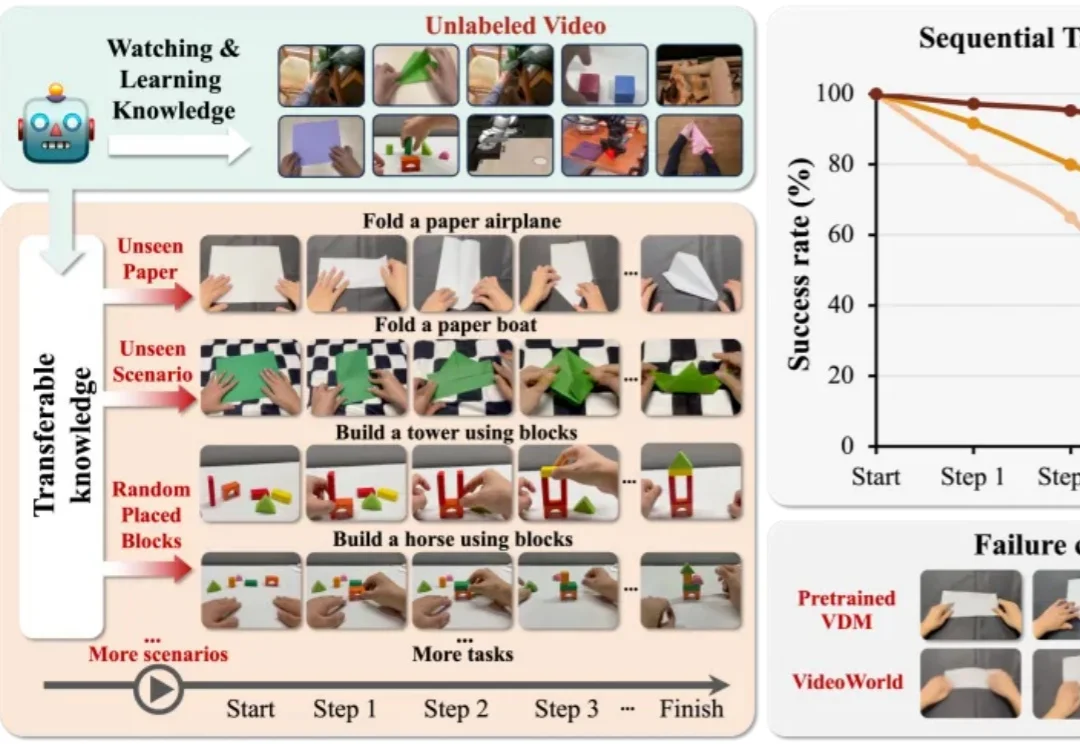
视觉世界模型 “VideoWorld 2” 由豆包大模型团队与北京交通大学联合提出。不同于 Sora 2 、Veo 3、Wan 2.2 等主流多模态模型,VideoWorld 系列工作在业界首次实现无需依赖语言模型,即可认知世界。

港科大团队提出音频生成统一模型AudioX,只需一个模型,就能从文本、视频、图像等任意模态生成高质量音效和音乐,在多项基准上超越专家模型。团队同时开源了700万样本的细粒度标注数据集IF-caps与可控T2A评测基准T2A-bench,并在该基准上大幅领先现有方法。论文已被ICLR 2026接收。
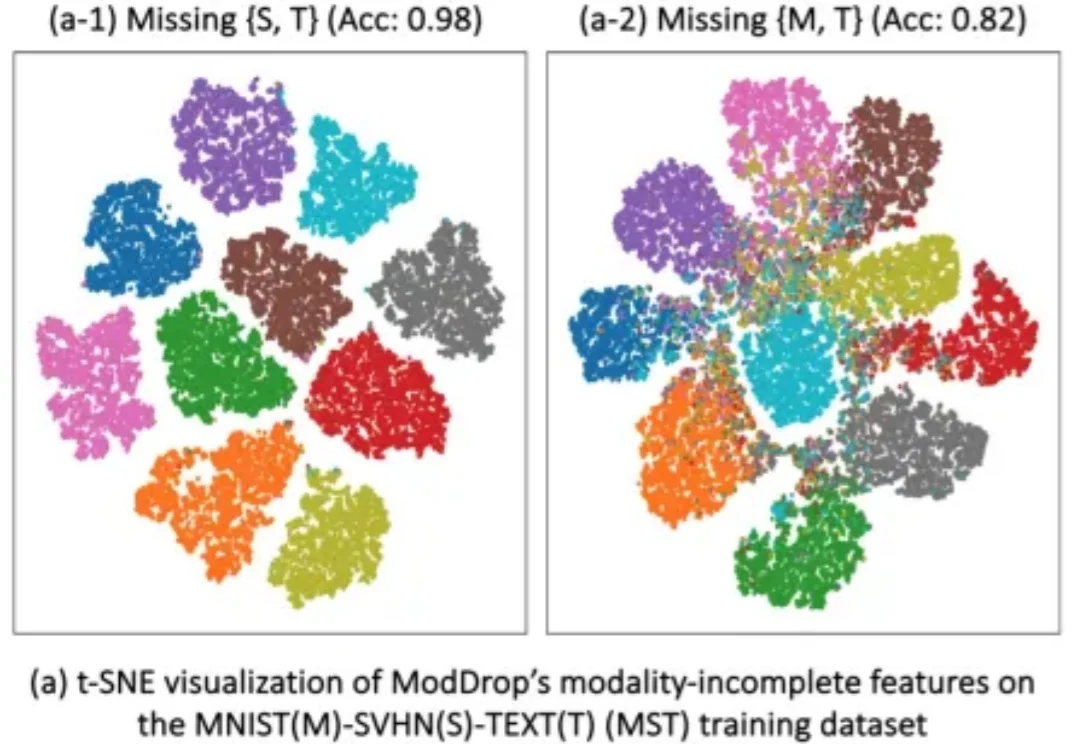
多模态学习(Multimodal Learning)正在推动 AI 在医学影像、自动驾驶、人机交互等领域取得突破。通过融合图像、文本、表格等多种模态,模型能够获得更全面的信息,从而显著提升性能。
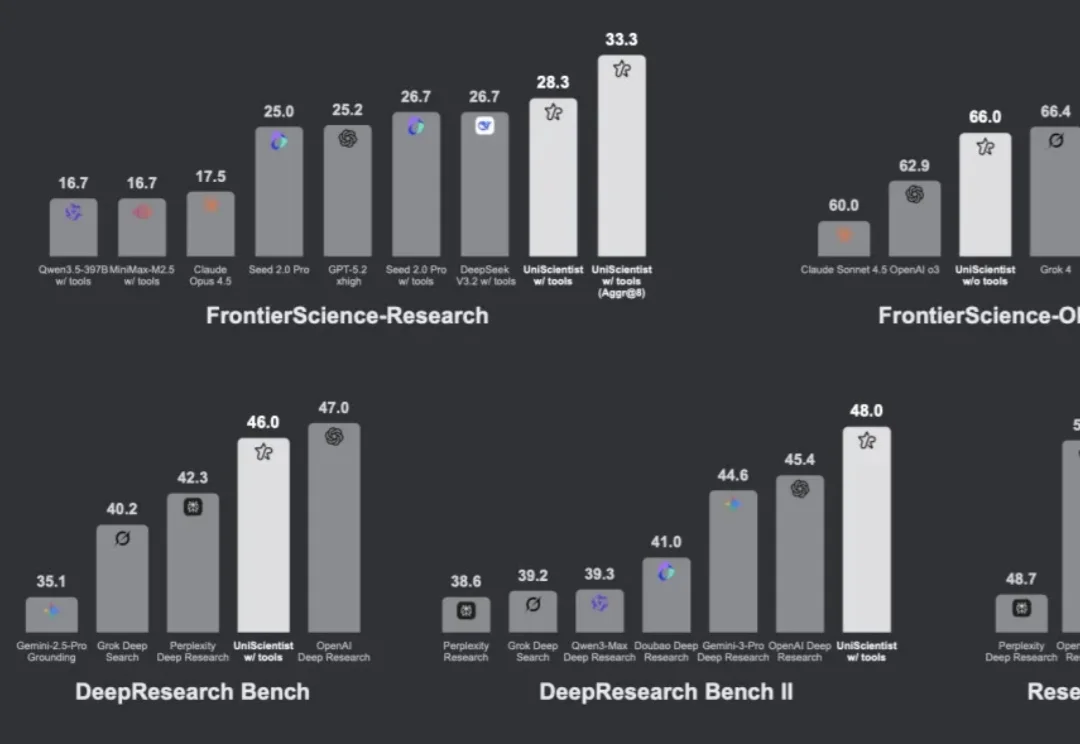
多数大模型能生成 “看起来像” 研究的文本,但极少数能真正做研究 —— 提出假设、收集证据、执行可复现的推导、迭代验证直至结论成立。

十亿参数的三维重建模型,能塞进手机吗?
OpenClaw 火爆的盛况至今仍在持续,在国内甚至出现了排队在腾讯总部楼下等待安装 OpenClaw 的场景,让人感叹「一代人有一代人的领鸡蛋」。

基础模型时代,大模型能力的爆发,很大程度上源于在海量文本上的预训练。然而问题在于,文本本质上只是人类对现实世界的一种抽象表达,是对真实世界信息的有损压缩。
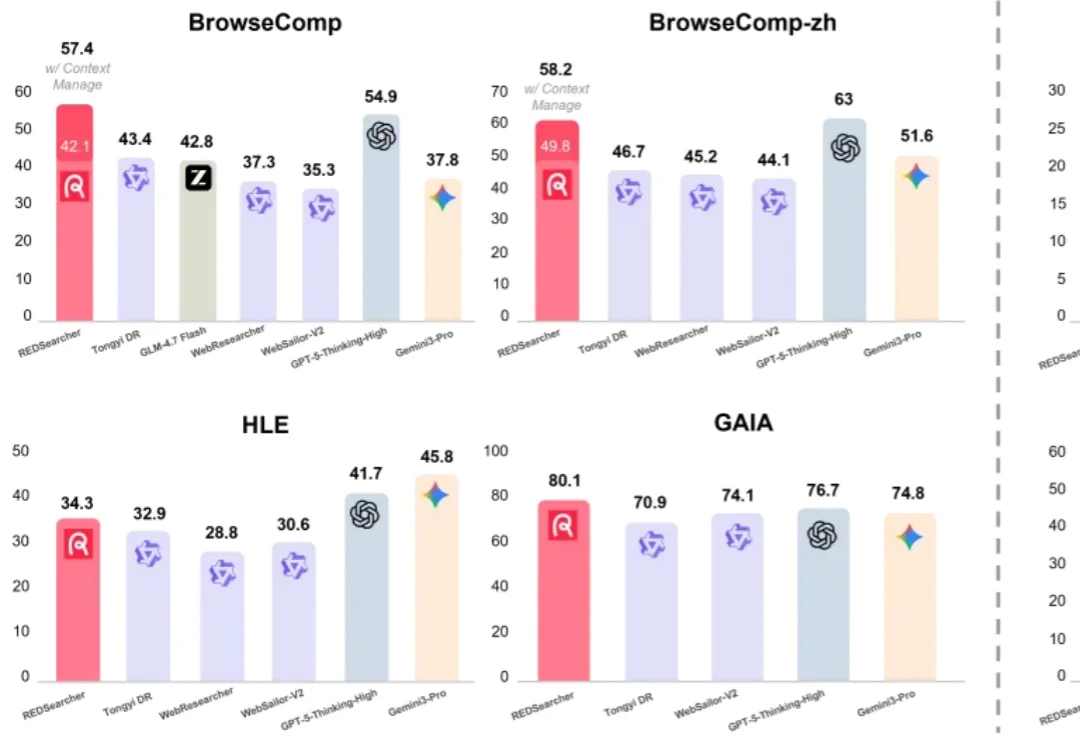
「2018 到 2023 年间在 EMNLP 会议上发表的那篇论文中,第一作者本科就读于达特茅斯学院、第四作者本科就读于宾夕法尼亚大学的那篇科学论文,题目是什么?」
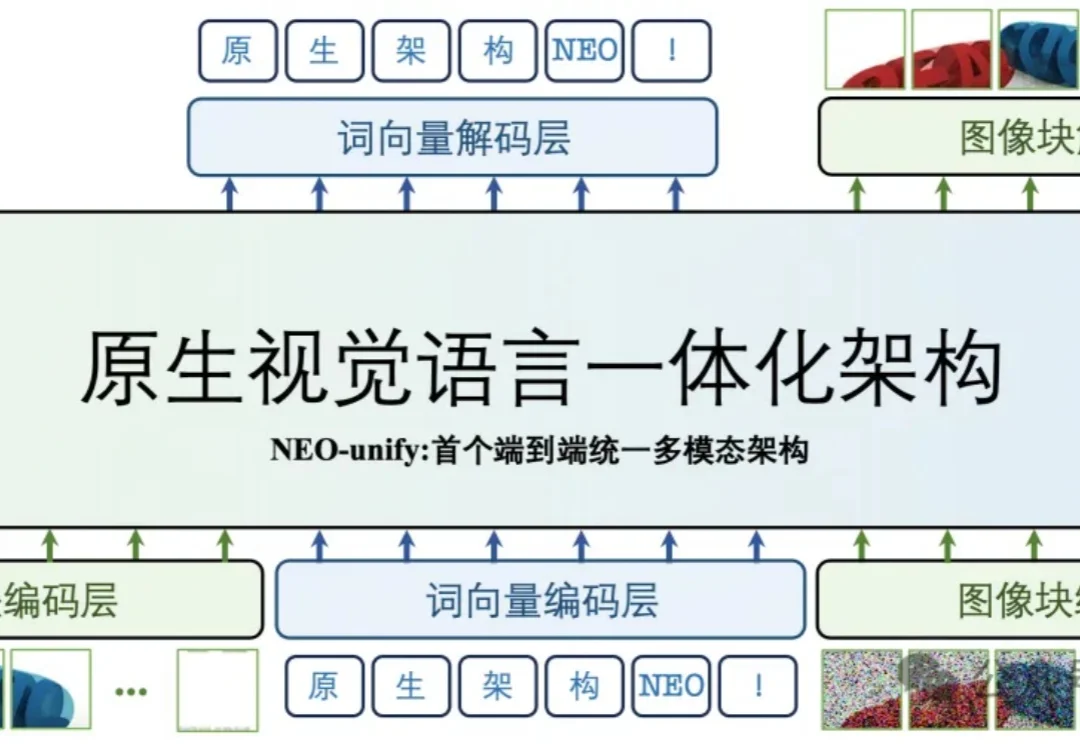
多模态大模型的研发范式,正在被彻底重构。
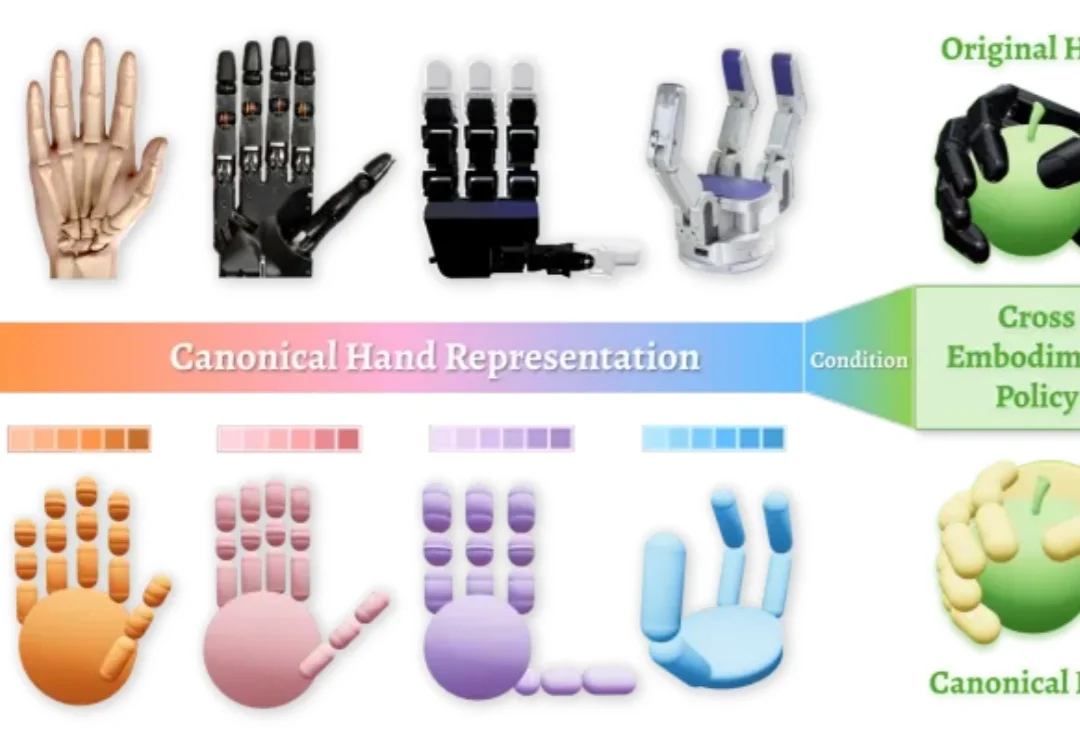
在机器人操作领域,一个长期悬而未决的核心问题始终困扰着研究者: 面对形态各异的灵巧手,我们是否注定要为每一种手型单独设计表示方式与控制策略?
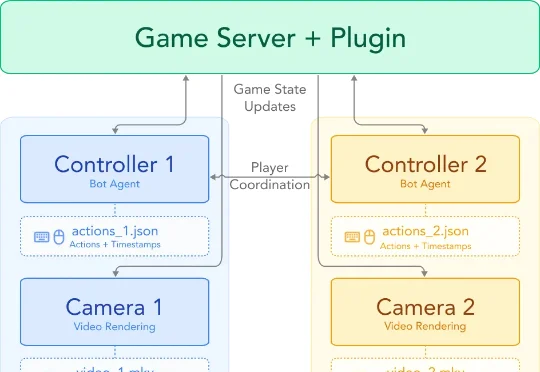
谢赛宁团队的最新视频世界模型 Solaris,首个多人视频世界模型,能够同时生成多个玩家之间保持一致的第一视角。研究团队发现,目前的视频世界模型仅能处理单人视角,这并不能反映现实世界的真实运作方式,希望能够能够实现多人同步观察一个统一世界。于是,研究团队把视角投向了电子游戏。
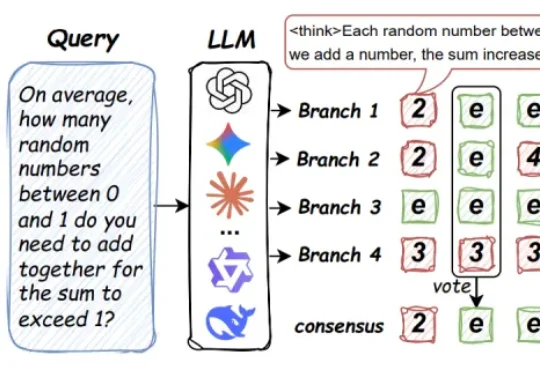
来自马里兰大学、圣路易斯华盛顿大学、北卡罗来纳大学教堂山分校等机构的研究团队提出了 Parallel-Probe。不同于直接从算法设计出发,该研究首先通过引入 2D Probing,对 online 并行推理过程中的全局动态性进行了系统性刻画。

随着OpenClaw的爆火,全球用户在AI Agent上消耗的Token量整整暴涨了1000倍!这不是一次普通的开源项目走红,这是一个信号——一个比编程奇点更加剧烈的奇点,正在撕裂我们习以为常的世界。

是不是经常纠结于 VLA(视觉 - 语言 - 动作)模型的训练技巧?面对层出不穷的 VLA 算法,是不是常常感到眼花缭乱,不知道哪种数据模态、训练策略最有效? 别急,丰田研究院(TRI)和清华大学刚刚

现在,一篇来自 CISPA 亥姆霍兹信息安全中心的最新论文《Real Money, Fake Models: Deceptive Model Claims in Shadow APIs》为我们揭开了一点谜底:那些你花真金白银购买的「第三方 API」,有可能偷偷把前沿大模型换成了廉价的替代品。
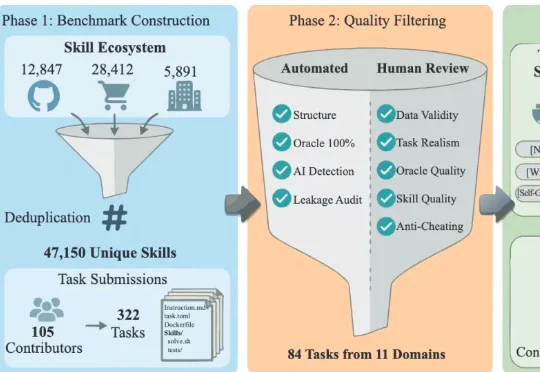
近日,一篇名为《SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks》的论文预印本引爆了海外 AI 社区,YC 总裁 Garry Tan 亲自转发,登顶 Hacker News(363 票 / 163 评论),霸榜 AlphaXiv #1,

3月6日,腾讯混元发布了一篇名为“HY-WU (Part I): An Extensible Functional Neural Memory Framework and An Instantiation in Text-Guided Image Editing”的技术报告。提出了一种崭新的功能性记忆(functional neural memory)范式(weight unleashing),

近日,深度学习领域重要底层优化技术 FlashAttention 迎来大版本更新。FlashAttention 核心作者、普林斯顿大学助理教授 Tri Dao 表示,在 Blackwell GPU 上,即使瓶颈截然不同,注意力机制的执行速度现在也几乎与矩阵乘法一样快了!

Anthropic最新报告炸场了:调查显示,程序员75%的任务已被AI覆盖!客服、数据录入紧随其后。更可怕的是,这还只是开始,报告预警:AI对劳动力市场的影响,是一场长达十年的「温水煮青蛙」!
近期,大连理工与快手可灵团队推出了 MultiShotMaster—— 一个高度可控的多镜头视频生成框架,该论文向研究社区展示了即使在 1B 左右的小参数量级模型上,也可以实现导演级的镜头调度和连贯叙事,且支持多图参考、主体运动控制。
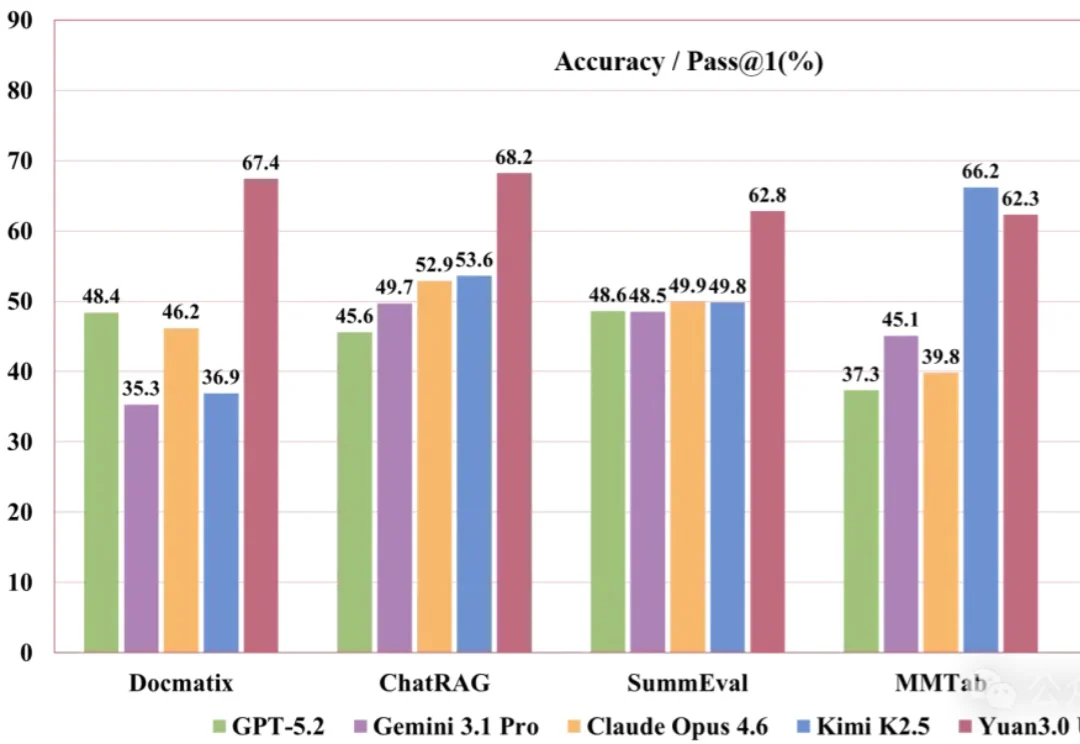
刚刚,YuanLab.ai团队正式开源发布源Yuan3.0 Ultra多模态基础大模型。
昨天,Thinking Maching Lab 研究者、斯坦福大学博士生 Zitong Yang 正式完成了他的博士论文答辩,课题为「持续自我提升式 AI」(Continually self-improving AI),并且他在答辩完成后很快就放出了自己的答辩视频,从中我们可以看到他对未来 AI 发展路径的系统性探索。
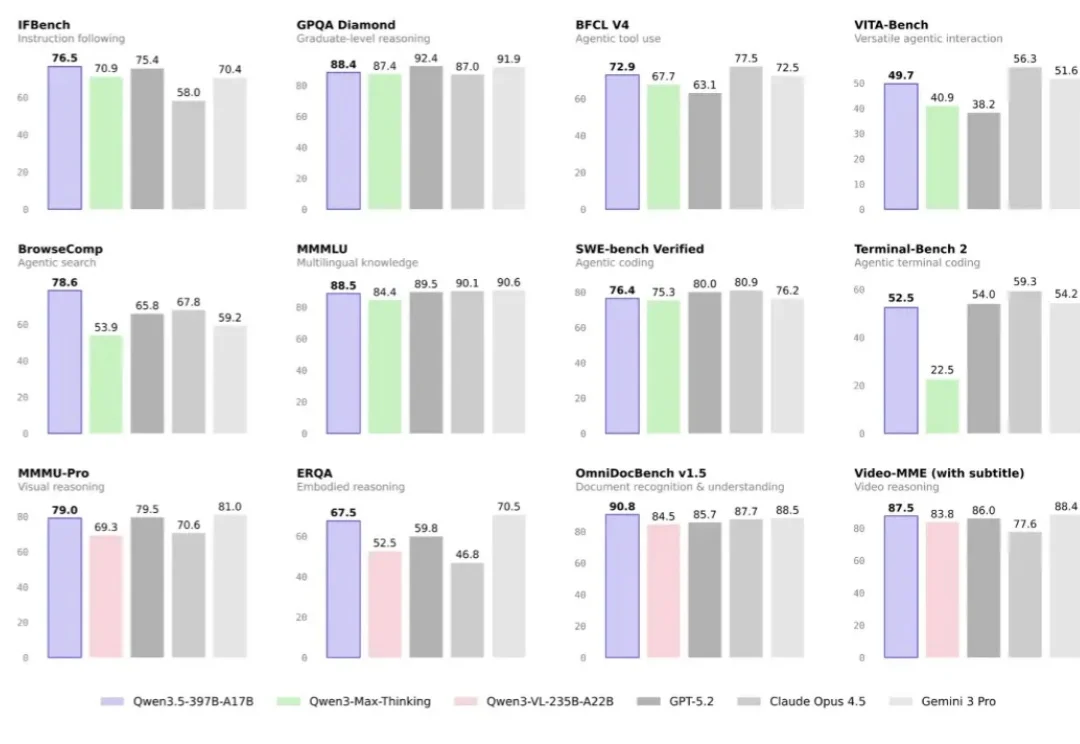
最近关于Qwen3.5还有其幕后团队,市场上的讨论沸沸扬扬,但今天我们不聊八卦,主要讲讲干货。