# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这不巧了吗……智谱和DeepSeek,又双叒撞车了。
太卷了,DeepSeek-OCR刚发布不到一天,智谱就开源了自家的视觉Token方案——Glyph。

既然是同台对垒,那自然得请这两天疯狂点赞DeepSeek的卡帕西来鉴赏一下:
或许你也会对我们的工作感兴趣。

发论文就发论文,怎么还争上宠了。(doge)
网友调侃be like:AI界也有自己的霸总爱情片。

是的,与DeepSeek-OCR一样,智谱这篇论文的目标同样也是通过视觉的方式,破解当下LLM上下文冗长的难题。
随着LLM能力一路狂飙,用户和厂商对于长上下文的需求也越来越迫切。
毕竟,不论是长文档分析、代码审查,还是多轮对话,模型可不能像金鱼那样看过就忘。要让它们真正靠谱地执行任务,就得有足够稳定的「工作记忆」。
但扩充上下文可是个相当吃力不讨好的工作。
举个例子:如果把上下文从50K扩到100K,算力的消耗大约会变成原来的四倍。
原因在于,更多的Token,就意味着模型需要记住更多的激活值、缓存、注意力权重,这些东西在训练和推理阶段都是靠真金白银堆出来的。
如果能实实在在地提升性能,多花点钱也认了。
可最让人心痛的是,砸了重金扩上下文,模型还不一定更聪明。
IBM的研究就指出,光靠“多塞 Token”并不能保证模型表现线性提升。
相反,当输入太长、信息太杂时,模型反而可能陷入噪声干扰和信息过载,越看越糊涂。
关于这类问题,目前大概有三种比较主流的解决方案:
第一类,是扩展位置编码。
在Transformer结构里,模型并不知道输入的先后顺序,因此要给每个Token加上“位置编码”,告诉模型这是谁先谁后。
而扩展位置编码的做法,就是把原有的位置编码区间直接向外延伸。
比如,把0~32K的位置区间“插值”到0~100K,这样,模型就能在工作时接受更长的输入,而不必重新训练。
虽然如此,这并没有解决推理成本的问题,模型在推理阶段依旧要遍历所有上下文。
而且,模型虽然能继续读下去,但由于它在训练中从未见过如此长的上下文,现在逼着人家读肯定表现不会好。
第二类,是改造注意力机制。
既然上下文变长了,那就让模型「读」快一点,比如用稀疏注意力、线性注意力等技巧,提高每个Token的处理效率。
但再怎么快,账还是那本账,Token的总量没有减少,如果上下文都到了几十万,多高的效率也顶不住。
第三类,是检索增强RAG路线。
它通过外部检索先挑重点、再喂给模型,输入变短了,推理轻快了。
但大家也知道,RAG的输出结果肯定不如模型基于训练数据的回答,而且还会因多出来的检索步骤拖慢整体响应。
踏破铁鞋无觅处,上下文真是个令人头疼的问题。
为了解决这个问题,研究团队提出了一种新范式——Glyph。
大道至简:既然纯文本的信息密度不够,那就把它放进图片里。
普通LLM处理文本时,是把句子拆成一个个独立的Token依次输入,效率很低。
比如,如果一句话能分成1000个Token,模型就得老老实实算1000个向量,还要在它们之间做注意力计算。
相比之下,Glyph不会逐字阅读,而是先把整段文字排版成图像式的视觉Token,再把这张「截图」交给VLM去处理。
之所以要这么做,是因为图像能承载的信息密度远高出纯文本,仅需一个视觉Token就能容纳原先需要好几个文本Token的内容。
借助这种方式,即便是一个上下文固定的VLM,无需借助稀疏注意力、RAG等工具,也能轻松吃下足以「撑死」LLM的超长文本。
举个例子:小说《简·爱》大约有240K的文本Token,对一台上下文窗口只有128K的传统LLM来说,只能塞进去一半。
这种情况下,如果你想问一些涉及到故事跨度比较大的问题,传统模型多半答不上来。
比如:女主离开桑菲尔德后,谁在她陷入困境时帮助了她?
但如果使用Glyph,把整本书渲染成紧凑的图像,大约只需要80K视觉Token。
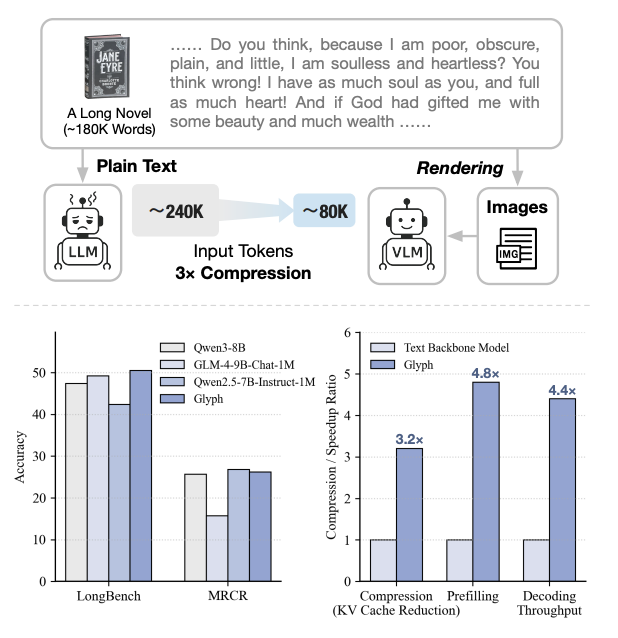
这样一来,同样是128K上下文的VLM就能轻松看完整部《简·爱》,对故事脉络心中有数,也能从更大的全局视角来回答问题。
这么立竿见影的效果,是怎么实现的呢?
Glyph的训练流程主要分为三个阶段:
第一阶段:持续预训练(Continual Pre-training)
这一阶段的目标,是让模型把自己的长上下文理解能力从文字世界迁移到视觉世界。
具体而言,研究团队先尽可能多地将海量长文本渲染成不同风格的图像,把VLM扔在各式各样排版、字体、布局中“读图识文”,以便训练出更强的泛化能力。
在这个过程中,模型会不断学习如何把图像中的文字信息,与原始文本语义对齐。
第二阶段:LLM驱动的渲染搜索(LLM-driven Rendering Search)
虽然多样化的渲染方式能提升模型的泛化能力,但在实际应用中,效率和精度必须兼顾。
文字如何转成图,决定了压缩率与可读性之间的微妙平衡。
字体太大、排版太松固然不好,这样做信息密度太低,有悖于视觉Token的初衷。
不过,过于追求信息密度也不是好事。
字体小、布局紧,虽然压缩率高,却可能让模型“看不清”,理解出现偏差。
为此,研究团队引入由LLM驱动的遗传搜索算法,让模型自动探索最优的渲染参数——比如字体大小、页面布局、图像分辨率等——力求在尽可能压缩的同时不丢语义。
第三阶段:后训练(Post-training)
在找到最优的渲染方案后,研究团队又动手做了两件事:有监督微调和强化学习,旨让模型在“看图读文”这件事上更聪明、更稳。
此外,他们还在SFT和RL阶段都加上了辅助OCR对齐任务,教模型学会从图像里准确还原文字细节,让视觉和文本两种能力真正融为一体。
最终,Glyph一举练成两大神功:
1、看懂长文,推理稳准狠。
2、认清细节,读图不伤脑。
靠着这套组合拳,Glyph在高压缩的视觉上下文任务里依然能游刃有余。
读懂了原理,接下来让我们看看Glyph的实际表现如何。
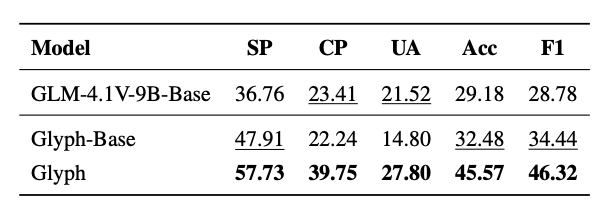
事实证明,Glyph的确有助于大幅削减Token数。
实验结果显示,Glyph在多项长上下文基准测试中实现了3–4倍的Token压缩率,同时依然保持与主流模型(如Qwen3-8B)相当的准确度。
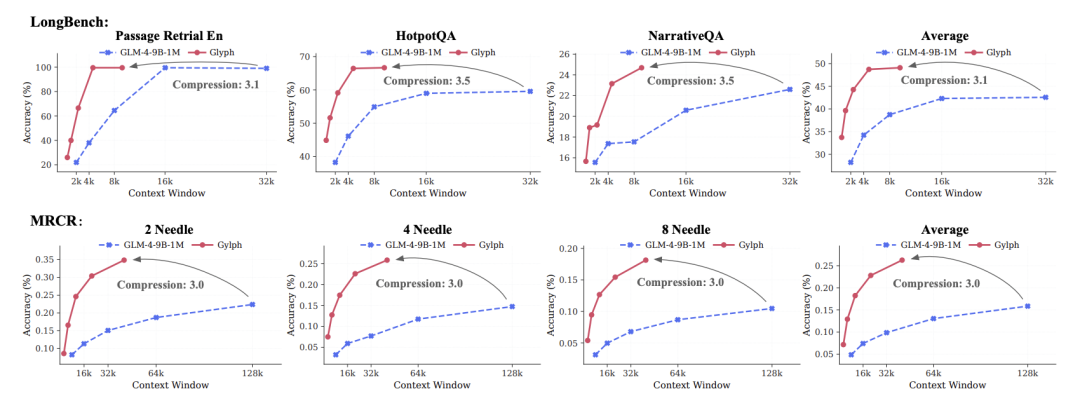
这种压缩不仅减轻了算力负担,还带来了约4倍的prefill与解码速度提升,以及约2倍的SFT训练加速。
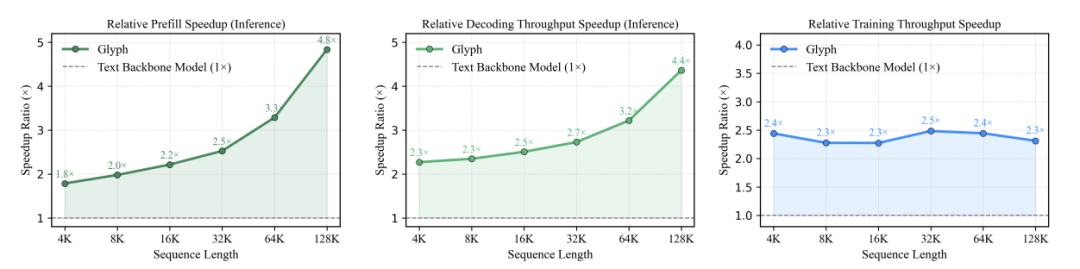
更令人惊喜的是,在极端压缩的情况下,一个上下文窗口仅128K的VLM,依然能够应对相当于百万Token级的文本任务,并丝毫不落下风。
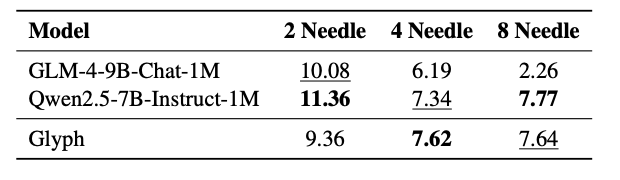
此外,虽然Glyph的训练数据主要来自渲染后的文本图像,但它在多模态任务上同样表现出色,证明了其强大的泛化潜力。
综上所述,这篇论文提出了一种名为Glyph的长上下文建模框架。
核心思路是把长文本“画”成图,再让VLM去看图读文,做到一目十行,从而能实现高效的上下文扩展。
这么厉害的成果,都是谁做出来的?
论文的一作是Jiale Cheng,他是清华大学的博士生,主要研究方向包括自然语言生成、对话系统和相关的人工智能交互技术。

目前,Jiale已发布了多篇论文,并在谷歌学术上有不错的影响力。

此外,论文还有三位主要贡献者:Yusen Liu、Xinyu Zhang、Yulin Fei。
遗憾的是,都没有太多公开资料。
担任本文通讯作者的是黄民烈教授。

黄教授本科与博士均毕业于清华大学,目前是清华大学计算机科学与技术系长聘教授,同时兼任智能技术与系统实验室副主任、清华大学基础模型中心副主任。
此外,他还是北京聆心智能科技有限公司的创始人兼首席科学家。
黄教授的研究方向主要集中在人工智能、深度学习、强化学习,自然语言处理等。
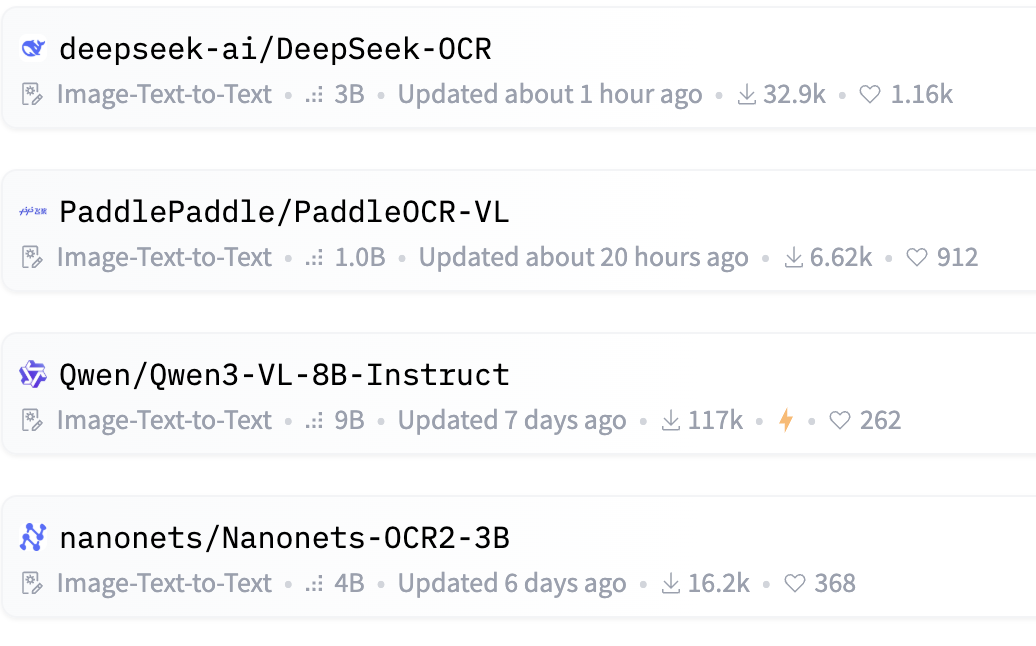
继MoE名声鹊起后,DeepSeek-OCR的出现再次在AI领域掀起了一波技术革命。
截至10月22日,抱抱脸上最受欢迎的前四个模型,全部都支持OCR。
一方面,自然是视觉Token本身的巨大潜力。
在上下文建模方面,视觉Token的表现堪称惊艳——
DeepSeek-OCR仅用100个视觉Token,就能在原本需要800个文本Token的文档上取得高达97.3%的准确率。
这种效率提升,意味着AI的门槛正被迅速拉低。
据DeepSeek介绍,引入OCR技术后,单张NVIDIA A100-40G GPU每天可处理超过20万页文档。
按这个速度推算,仅需一百多张卡,就足以完成一次完整的模型预训练。
降本增效历来是开源阵营的强项,但在这次热议中,大家的关注点不再仅仅停留于此——
视觉Token的出现,或许正在从底层重塑LLM的信息处理方式。
未来,像素可能取代文本,成为下一代AI的基本信息单元。
卡帕西指出,像素天生比文本更适合作为LLM的输入,主要有两点原因:
1、信息压缩更高 → 更短的上下文窗口,更高的效率。
2、信息流更广泛 → 不仅能表示文字,还能包含粗体、颜色、任意图像。
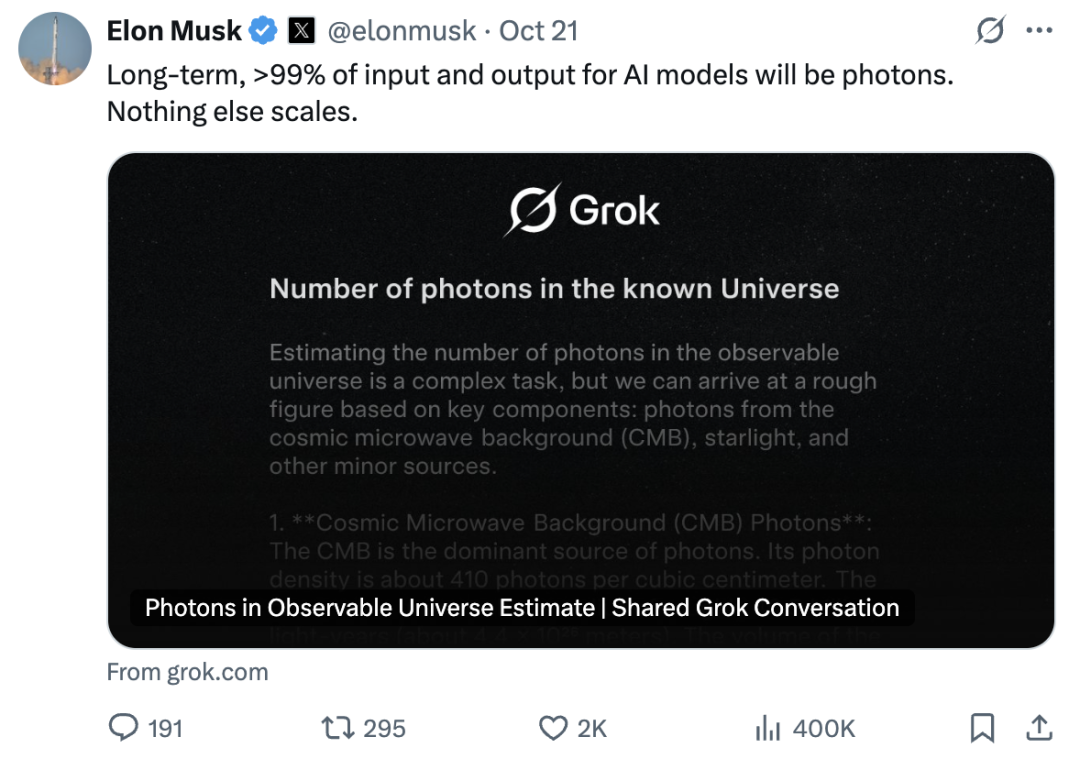
马斯克的观点则更加激进:
此外,OCR的爆火也不禁让人再次思考AI与脑科学之间千丝万缕的联系。
用图像而非文本作为输入,乍看之下似乎反直觉,但细想便会发现,这反而更贴近人脑的信息处理方式。
人类获取任何新信息时,最先感知到的都是图像。
即便是阅读,我们的大脑最初接收的也只是由像素按特定规律排列组合的一串图形,在经过一层层视觉处理后,这些像素才被翻译成“文字”的概念。
从这个角度来看,OCR的表现固然惊艳,但也没那么出乎意料了。
毕竟,视觉才是人类数万年来接触世界的一手资料。
相比之下,语言不过是我们基于视觉与其他感官体验提炼出的高度浓缩的抽象层。它标准化、成本低,但本质上依旧是视觉的降维产物。
即便再清晰的影子,也注定会流失不少细节。
有趣的是,当AI在各项指标上不断逼近人类、引发普遍焦虑的同时,每当技术发展陷入瓶颈,我们又总能从那个被质疑“没那么智能”的人脑里重新找到答案。
神经网络、注意力机制、MoE……都是这个规律下的产物。
而这一次,深不可测的「人类智能」,从视觉Token上再次得到了印证。
论文:
https://arxiv.org/pdf/2510.17800
GitHub:
https://github.com/thu-coai/Glyph
参考链接:
[1]https://x.com/ShawLiu12/status/1980485737507352760
文章来自于微信公众号 “量子位”,作者 “量子位”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
