
全面战胜ReAct!斯坦福全新智能体推理框架,性能提升112.5%
全面战胜ReAct!斯坦福全新智能体推理框架,性能提升112.5%斯坦福和MIT的研究团队推出了一种新的AI智能体推理框架ReCAP,在长上下文任务中全面超越了现有的主流框架ReAct,性能提升显著。ReCAP通过独特的递归树结构和三大机制,解决了大语言模型在复杂任务中常见的目标漂移、上下文断层和成本爆炸等问题。
来自主题: AI技术研报
10750 点击 2025-12-02 15:20
 搜索
搜索
斯坦福和MIT的研究团队推出了一种新的AI智能体推理框架ReCAP,在长上下文任务中全面超越了现有的主流框架ReAct,性能提升显著。ReCAP通过独特的递归树结构和三大机制,解决了大语言模型在复杂任务中常见的目标漂移、上下文断层和成本爆炸等问题。
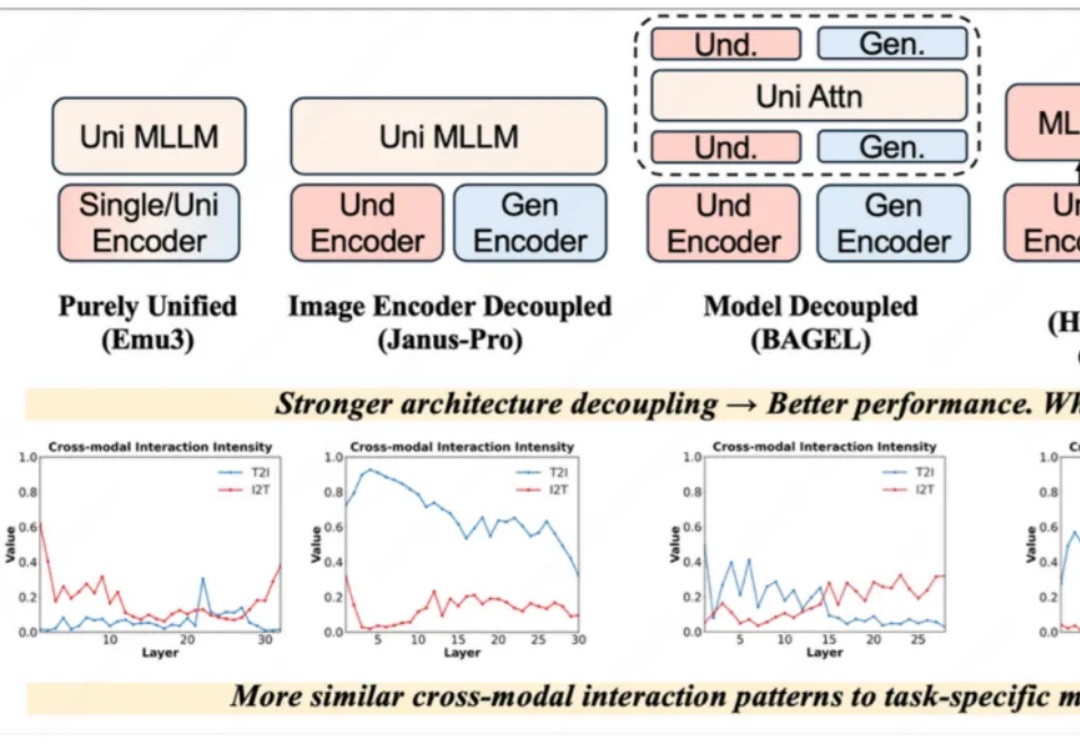
近一年以来,统一理解与生成模型发展十分迅速,该任务的主要挑战在于视觉理解和生成任务本身在网络层间会产生冲突。早期的完全统一模型(如 Emu3)与单任务的方法差距巨大,Janus-Pro、BAGEL 通过一步一步解耦模型架构,极大地减小了与单任务模型的性能差距,后续方法甚至通过直接拼接现有理解和生成模型以达到极致的性能。

这是一篇报告解读,原文是《DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models》

随着大语言模型(LLM)的商业价值快速提升,其昂贵的训练成本使得模型版权保护(IP Protection)成为业界关注的焦点。然而,现有模型版权验证手段(如模型指纹)往往忽略一个关键威胁:攻击者一旦直接窃取模型权重,即拥有对模型的完全控制权,能够逆向指纹 / 水印,或通过修改输出内容绕过指纹验证。

字节新视频模型Vidi2,理解能力超过了Gemini 3 Pro。

本文为Milvus Week系列第一篇,该系列旨在分享Zilliz、Milvus在系统性能、索引算法和云原生架构上的创新与实践,以下是DAY1内容划重点:
当今自动驾驶模型越来越强大,摄像头、雷达、Transformer 网络一齐上阵,似乎什么都「看得见」。但真正的挑战在于:模型能否像人一样「想明白」为什么要这么开?

最近看到一篇关于Claude Skills的质量非常高的文章, 标题:Claude Agent Skills: A First Principles Deep Dive 链接:https://leehanchung.github.io/blogs/2025/10/26/claude-skills-deep-dive/

随着大语言模型与开发工具链的深度融合,命令行终端正被重塑为开发者的AI协作界面。本文以 Google gemini-cli 为范本,通过源码解构,系统性分析其 Agent 内核、ReAct 工作流、工具调用与上下文管理等核心模块的实现原理。为希望构建终端 Agent 的开发者,提供工程实现的系统化参考。
6B小模型,首日下载量高达50万次,上线不到两天直接把HuggingFace两个榜单都冲了个第一。
为什么 AI 让小众市场突然变得值钱了!Ben 提出了一个非常关键的洞察:软件革命催生了 6500 亿美元的软件市场,但 AI 是第一个真正能够自动化劳动力的技术,这意味着我们现在面对的是一个 10 万亿美元的劳动力市场,仅在美国就有这么大的规模。到目前为止,只有 0.2% 的劳动力市场被自动化了。这个数字让我震惊,因为它意味着我们还处在这场革命的最初阶段,99.8% 的机会还在等待被发掘。
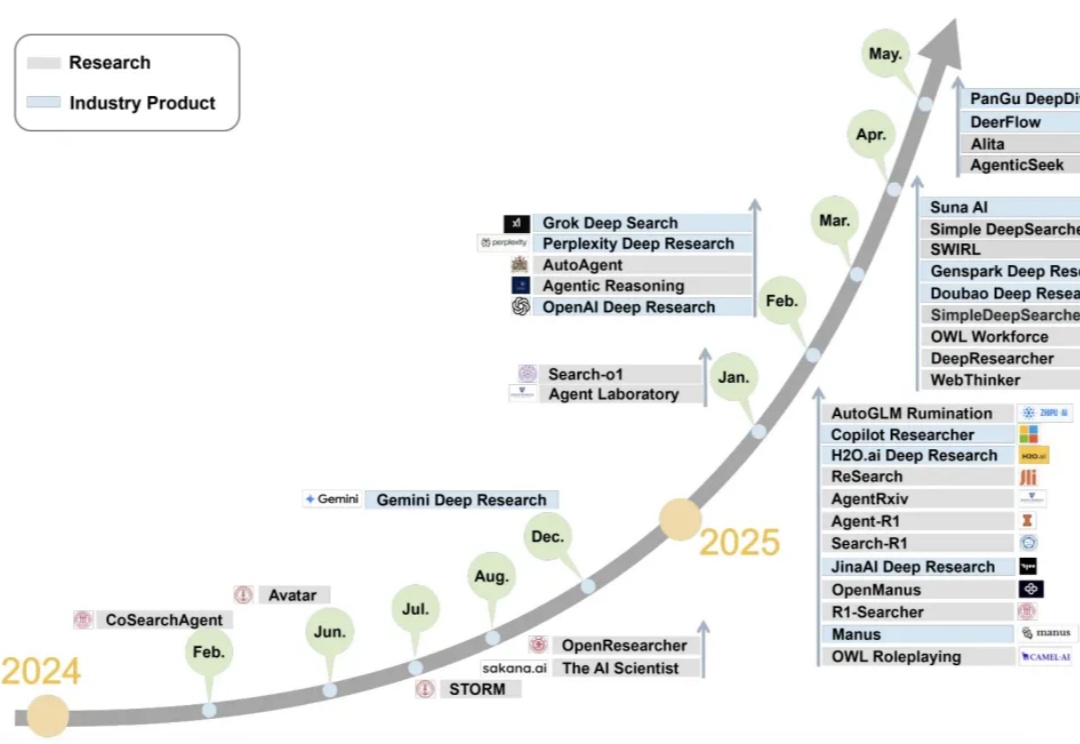
如果AI的终极使命是拓展人类认知的边界,那么“研究”——这项系统性探索未知的核心活动,无疑是其最重要的试金石。2024年,AI Agent技术迎来突破性进展,一个名为 Deep Research(深度研究) 的方向正以前所未有的速度站上风口,成为推动“AI应用元年”的真正引擎。

在当前的情感计算研究中,存在一个显著的“断层”:我们拥有越来越精准的情感识别算法(输入端),也有了逼真的语音和面部生成技术(输出端),但连接这两端的“中间层”却鲜有人问津。机器能识别出你在愤怒,也能模拟出抱歉的语气,但它真的理解愤怒的起因吗?它能基于这种理解去调整后续的决策逻辑吗?

当AI开始学会「摸鱼」,整个行业都该警醒了。

一般人和 ChatGPT 聊天时,往往不会在意要不要讲究礼貌。但来自爱荷华大学的一项最新研究显示:即便回答内容几乎相同,对 ChatGPT 粗鲁无礼也会让你花费更高的输出成本。
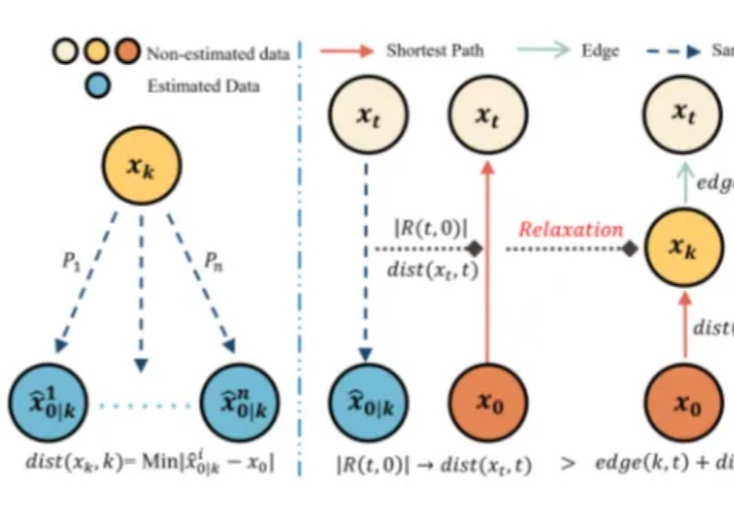
从“在线训练”到“离线建图”,扩散模型速度再突破!
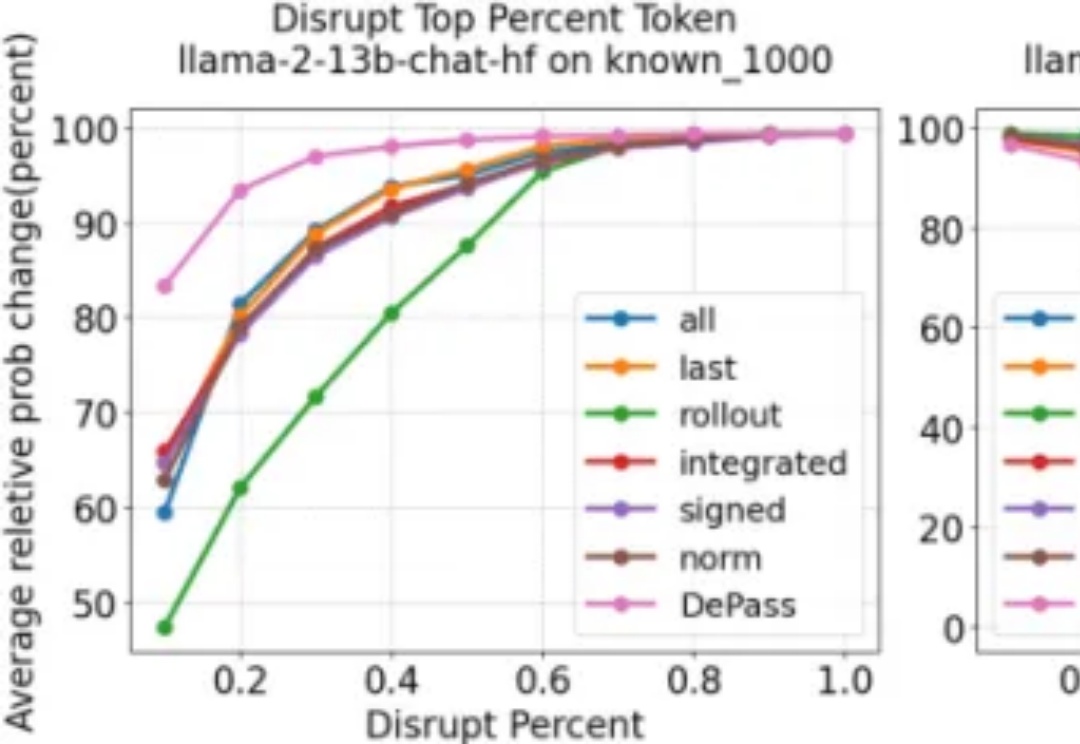
随着大型语言模型在各类任务中展现出卓越的生成与推理能力,如何将模型输出精确地追溯到其内部计算过程,已成为 AI 可解释性研究的重要方向。然而,现有方法往往计算代价高昂、难以揭示中间层的信息流动;同时,不同层面的归因(如 token、模型组件或表示子空间)通常依赖各自独立的特定方法,缺乏统一且高效的分析框架。

Hi,早上好。 我是洛小山,和你聊聊 AI 应用的降本增效。
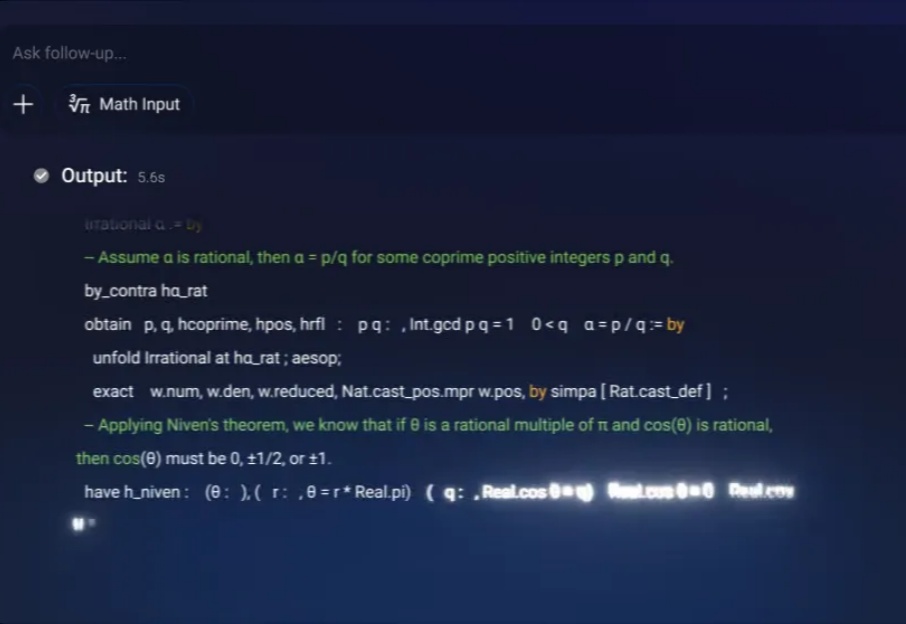
刚刚,Erdos 问题 #124 的一个弱化版本被证明。

我们能否像《头号玩家》那样伸手就能触摸到虚拟世界?像《阿凡达》那样植物和动物仿佛就在眼前飞舞?这不再只是科幻。11 月 26 日,在一篇最新 Nature 论文中,来自复旦大学团队和上海人工智能实验室的研究人员打造出一款名为 EyeReal 的裸眼 3D 显示器。
你好,我是袋鼠帝 我最近几乎天天都在用飞书多维表格,使用频率贼高,这玩意儿用起来是真滴爽。

观猹社区里聚集着一群富有创意、动手能力又特别强的创造者。他们来自不同的行业和背景,却在这里形成了某种微妙的共识:认真做产品、诚实写评价、乐于分享想法。
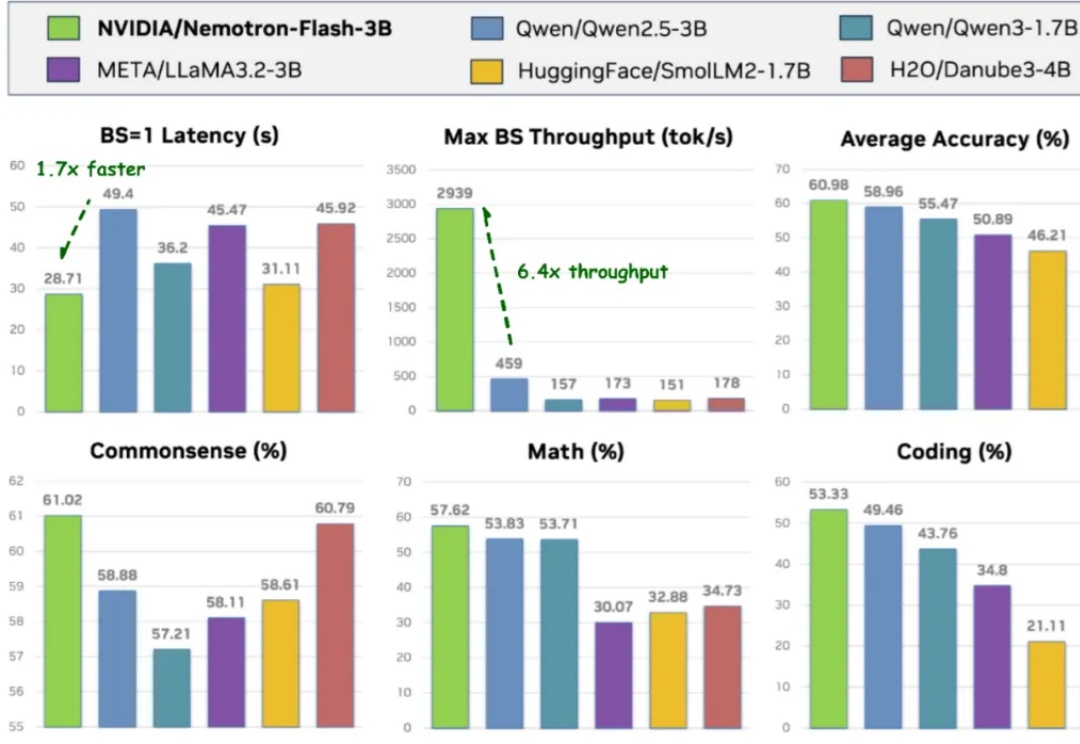
导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。

在大语言模型(LLM)的研究浪潮中,绝大多数工作都聚焦于优化模型的输出分布 —— 扩大模型规模、强化分布学习、优化奖励信号…… 然而,如何将这些输出分布真正转化为高质量的生成结果 —— 即解码(decoding)阶段,却没有得到足够的重视。
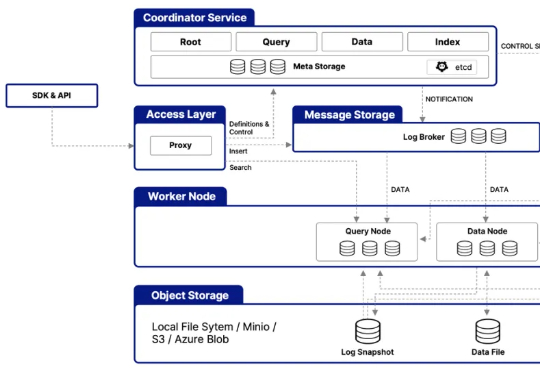
在架构层面,Milvus 2.6 大幅简化系统架构,整合多个核心组件 —— 例如将原有的 Coordinator 组件(含 RootCoord、QueryCoord、DataCoord)统一整合为 MixCoord,并将 IndexNode 与 DataNode 合并为单一组件。这些调整不仅降低了系统复杂度,更显著提升了系统的可维护性与横向扩展性。
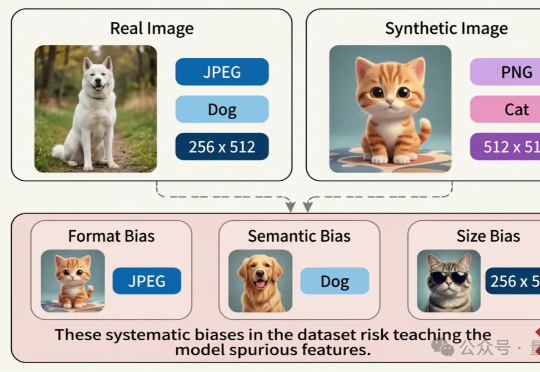
近日,腾讯优图实验室联合华东理工大学、北京大学等研究团队在A生成图像检测(AI-Generated Image Detection)泛化问题上展开研究,提出Dual Data Alignment(双重数据对齐,DDA)方法,从数据层面系统性抑制“偏差特征”,显著提升检测器在跨模型、跨数据域场景下的泛化能力。

本文第一作者为刘禹宏,上海交通大学人工智能专业本科四年级学生,相关研究工作于上海人工智能实验室科研实习期间完成。通讯作者为王佳琦、臧宇航,在该研究工作完成期间,均担任上海人工智能实验室研究员。

a16z 指出:“模型开发的进展正在简化整个基础设施栈,使得语音智能体具备更低延迟和更高性能。这一提升主要出现在过去六个月内,得益于新一代对话模型的出现。”基于这些趋势,Deepgram 与 Opus Research 合作开展的《2025 语音 AI 状况调查报告》,基于 400 位商业领袖的洞察,涵盖十多个行业,分析了语音 AI 的应用现状与关键特性。

CB Insights 发布的《2025 Future Tech Hotshots:Scouting Reports》报告,结合生成式 AI 分析与专有 Mosaic 评分体系,从全球海量初创企业中遴选出 45 家最具潜力的科技公司。
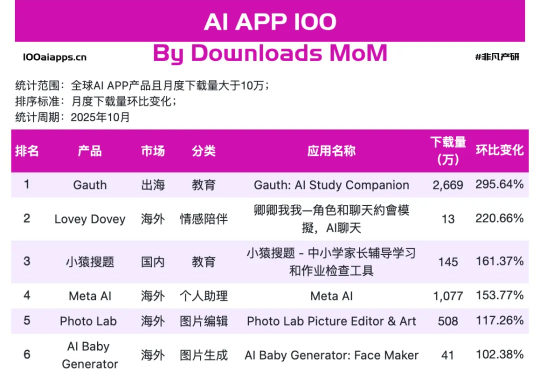
但当我们把视线从焦点模型上,挪到手机里AI应用真实数据上,就会发现一幅不同的画面。可以看到在非凡产研 10 月 AI App 增速榜上,跑得最快的那 17 个,并不是万事皆可聊的通用助手,而是一群看上去有点普通、甚至有点土气的小应用,其中Gauth、Starry、Knowunity、AI Baby Generator已经连续两个月上榜了。