

全国首例“AI游戏外挂”案告破!过程揭秘→
全国首例“AI游戏外挂”案告破!过程揭秘→AI人工智能拥有高效数据处理和自主学习能力。然而,也有一些人打起了人工智能的歪主意,“AI游戏外挂”是近些年出现的新型违法犯罪行为。
来自主题: AI资讯
8402 点击 2023-11-30 13:51
AI人工智能拥有高效数据处理和自主学习能力。然而,也有一些人打起了人工智能的歪主意,“AI游戏外挂”是近些年出现的新型违法犯罪行为。

训完130亿参数通用视觉语言大模型,只需3天!北大和中山大学团队又出招了——在最新研究中,研究团队提出了一种构建统一的图片和视频表征的框架。利用这种框架,可以大大减少VLM(视觉语言大模型)在训练和推理过程中的开销。

研究人员利用GPT4-Vision构建了一个大规模高质量图文数据集ShareGPT4V,并在此基础上训练了一个7B模型,在多项多模态榜单上超越了其他同级模型。

“人均月薪两万、本科以上学历、直通百度字节。”有些许荒凉的年底招聘市场,在最近的短短一周之内,突然冒出了一大批“AI数据标注员”的岗位,正在火热招聘中。

思维链已经out啦!想让大模型会推理还是得靠知识库:基座模型还是ChatGPT,最新思维图谱技术在多个基准数据集上实现巨大性能提升!

大家都在猜测,Q*是否就是「Q-learning + A*」。 AI大牛田渊栋也详细分析了一番,「Q*=Q-learning+A*」的假设,究竟有多大可能性。 与此同时,越来越多人给出判断:合成数据,就是LLM的未来。

前不久,原阿里首席AI科学家贾扬清的一条朋友圈截图四处流传。贾扬清说,他的一个朋友告诉他,某国产大模型不过是LLaMA架构,只是更换了几个变量名而已。 很快有好事者发现,在大模型、数据集开源社区Hugging Face上,就有一位开发者发出了类似质疑:“该模型使用了Meta LLaMA 的架构,只修改个tensor(张量)”。
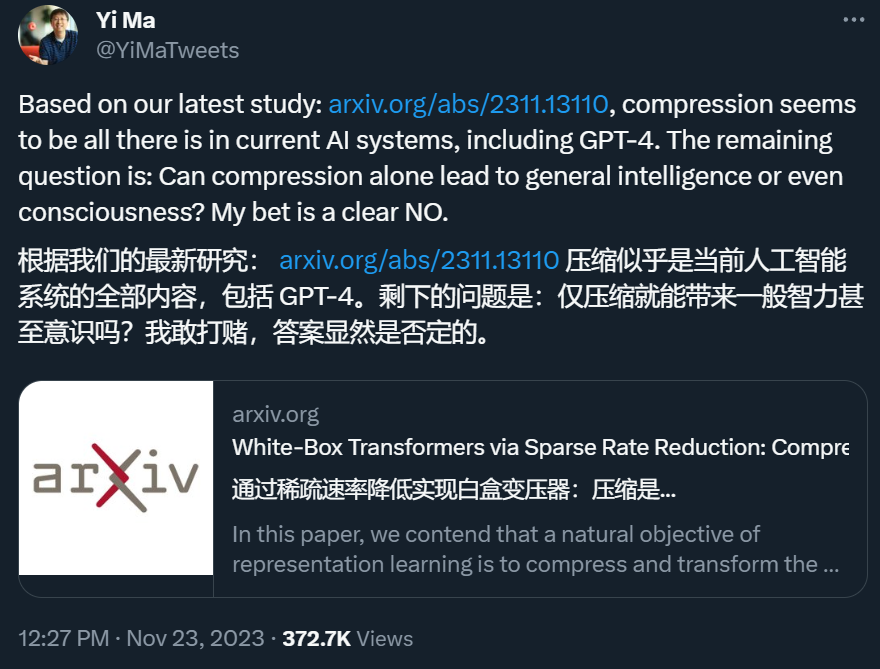
AGI 到底离我们还有多远?在 ChatGPT 引发的新一轮 AI 爆发之后,伯克利和香港大学的马毅教授领导的一个研究团队给出了自己的最新研究结果:包括 GPT-4 在内的当前 AI 系统所做的正是压缩。
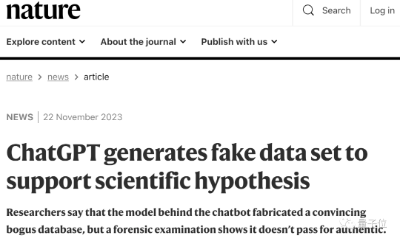
学术造假有了GPT-4,变得更容易了.这两天,一篇刊登在Nature上的新闻表示,GPT-4生成的造假数据集,第一眼还真不一定看得出来。

搜索引擎、手机、电子商务、社交网站等的个人数据,仅占全世界数据量的1成。剩下的9成是工业数据,尚未得到加工利用。企业订单、物联网、汽车行驶数据等,这些企业数据一旦统合,将是一场革新。工业数据争夺将愈演愈烈……