
独家|多模态通用智能公司Prana Labs完成近千万美金种子轮融资
独家|多模态通用智能公司Prana Labs完成近千万美金种子轮融资Z Potentials获悉,近日,总部位于硅谷与新加坡的Prana Labs正式完成近千万美金种子轮融资,由元生资本、XVC、Creekstone、三七互娱联合投资,澜松资本担任独家财务顾问。 与赛
来自主题: AI资讯
8587 点击 2026-07-17 11:46
 搜索
搜索
Z Potentials获悉,近日,总部位于硅谷与新加坡的Prana Labs正式完成近千万美金种子轮融资,由元生资本、XVC、Creekstone、三七互娱联合投资,澜松资本担任独家财务顾问。 与赛
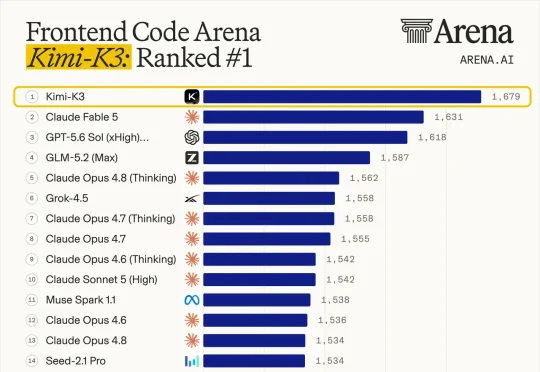
今天凌晨看到 Arena AI 更新 Code Arena 榜单时,我第一反应是有点意外。刚刚发布的 Kimi K3 拿到了 1679 分,排在全球第一,压过了 Claude Fable 5 的 1631 分和 GPT-5.6 Sol 的 1618 分。
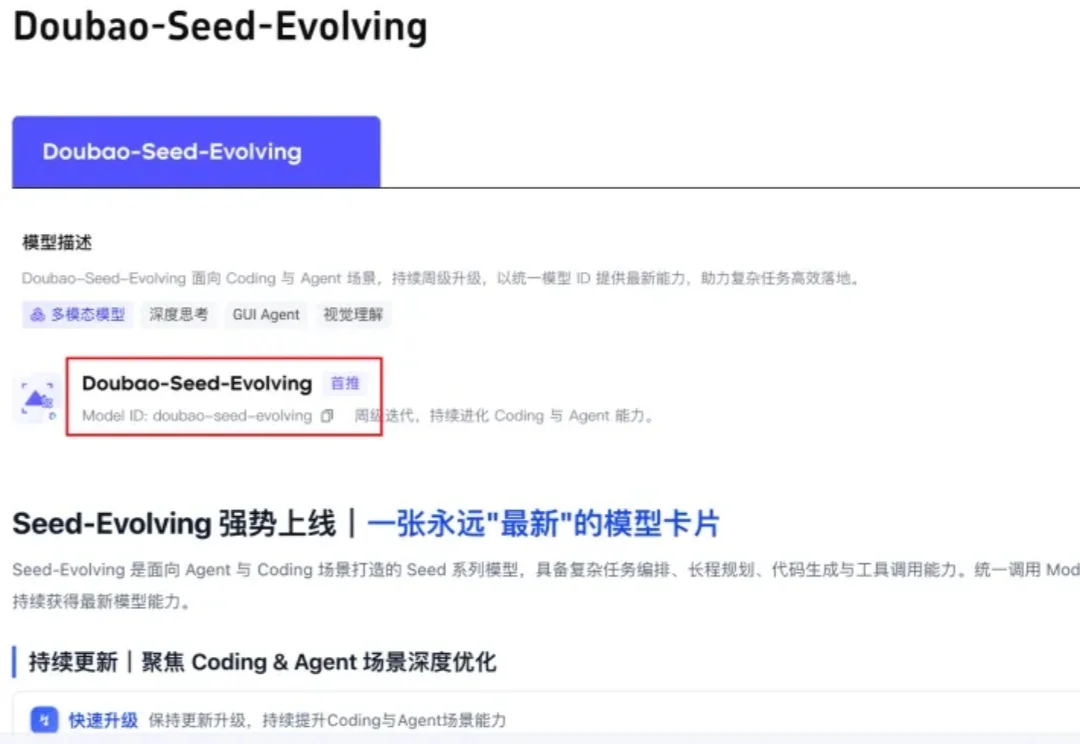
大家好,我是袋鼠帝。 前几天,火山的朋友提前跟我同步了一个消息,说豆包Seed模型又更新了。

循环真正的门槛,并不在于让AI一直跑,而在于它能不能自己踩住刹车。
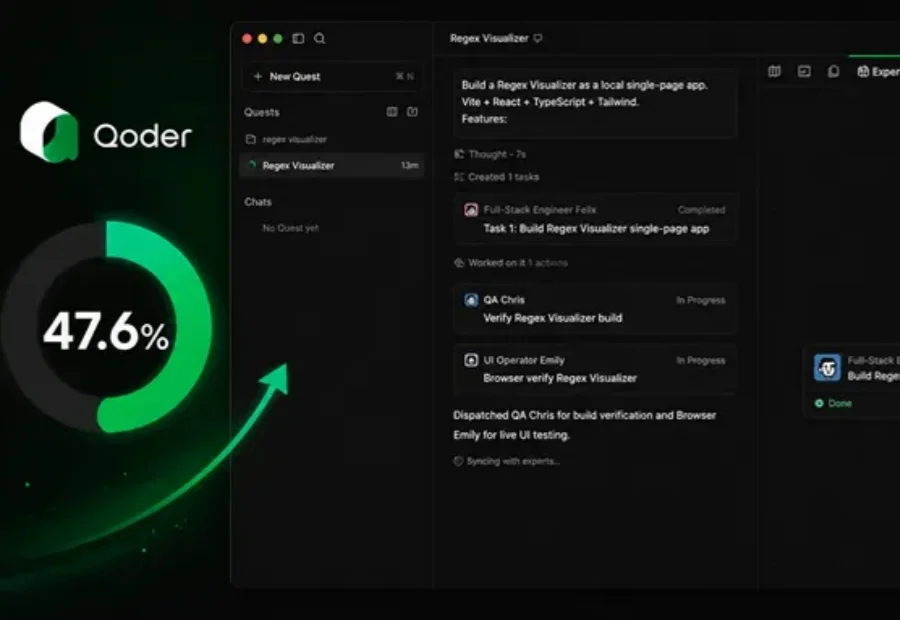
AI编程工具有望成为新的入口级产品。

这场越来越快、越来越贵、越来越拥挤的竞赛里,我们还能做什么?
天哪,打工人也能有自己的私人助理了!

数亿美金,竟输给了一台相机?

ICML 2026落幕了。

“中国的Anthropic”走出了比Anthropic更陡峭的增长曲线。