
WorkBuddy日活破千万了,KroWork还在角落里吃灰,快手这张牌到底怎么打
WorkBuddy日活破千万了,KroWork还在角落里吃灰,快手这张牌到底怎么打4月30号,快手Krow团队推出了一款桌面端AI智能体KroWork,在这里你不用写一行代码,对着它说一句话,它就能自己写代码、调试、部署,最后交付一个能直接在桌面运行的应用。
来自主题: AI资讯
5800 点击 2026-07-14 10:36
 搜索
搜索
4月30号,快手Krow团队推出了一款桌面端AI智能体KroWork,在这里你不用写一行代码,对着它说一句话,它就能自己写代码、调试、部署,最后交付一个能直接在桌面运行的应用。
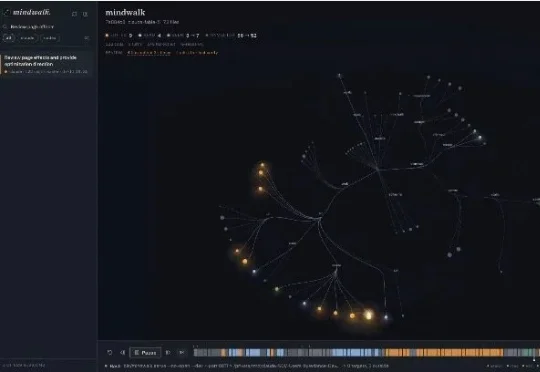
把一个Bug交给Claude Code或Codex,十几分钟后它回了一句“Done”和一大片Diff。过程中它读错了什么、为什么反复改同一个文件、最后有没有重新跑测试......开发者想知道就只能去几百行日志里碰运气。7月11日,一个名叫Mindwalk的开源项目发布了v0.1.0。

2026年,视频生成赛道正在经历一场从“离线生成”到“实时交互”的范式转移。7月3日全球数字经济大会上——生数科技创始人朱军正式发布Vidu S1实时交互模型,让AI从“视频生成”正式迈入“实时交互”的新阶段。

AI基础设施的核心任务,已经从支撑大模型推理,转向支撑海量智能体的规模化运行与高质量Token的持续生产。

Lyzr 的为其 Agent B 轮融资开展外联活动。该轮融资据公司称有望筹集 1 亿美元,估值约为 5 亿美元。Agent 回应了来自 130 多位投资者的查询,并协助起草了数十份投资备忘录。最终,这家获得 Accenture 支持的公司吸引了来自硅谷基金、中东风投公司和金融行业投资者共计 4 亿美元的兴趣。

CB Insights 上个月公布了 2026 年 AI 100。简单来说,就是从全球 AI 初创公司里,挑出 100 家它认为最值得关注的企业。CB Insights 的筛选范围超过 4 万家公司,不只看融资,还会综合交易活动、投资机构、团队招聘、行业合作和实际商业进展等数据。
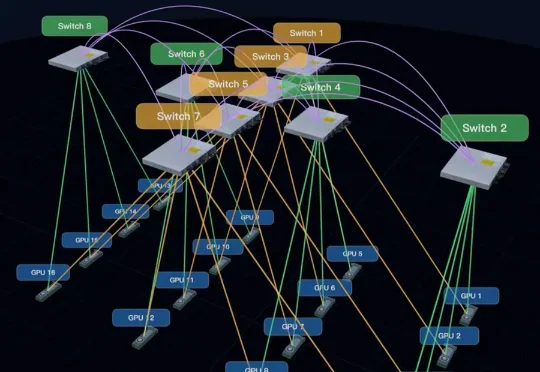
一家推翻传统网络架构的清华系创业公司,联合智谱、清华大学推出了全新的网络架构ZCube,能提升推理算力集群15%的Token产量,还能砍下约33%的网络硬件成本。近日,驭驯网络已完成智谱独家领投的数千万元融资,源合资本担任长期财务顾问。
过去十几年,程序员面试早就形成了一套成熟的应试套路。背题、刷题、共享面经,一条龙服务,从几块钱的 PDF 到十几万的“包过内推”,每一个价位都有对应的产品。只要你花够时间准备,进大厂的概率不低。

米哈游吊了人们一年的AI陪伴产品《BSide:Olivia Lin》(以下简称《林离》)在今天悄悄开放了抢先体验。这款产品的主角就叫林离,在前几日的BW展会上,米哈游还带着她来到了现场。不过当时现场的互动内容只有简单地写信与回信,我们还是不清楚具体到了桌面之后,她会是什么样子的。

就在今天,阶跃星辰在发布会上一口气抛出三样东西——全球首个大模型原生AI终端品牌STEPX;全球首个智能体原生操作系统Step AOS;全球首款大模型原生智能体手机STEPX Neo。