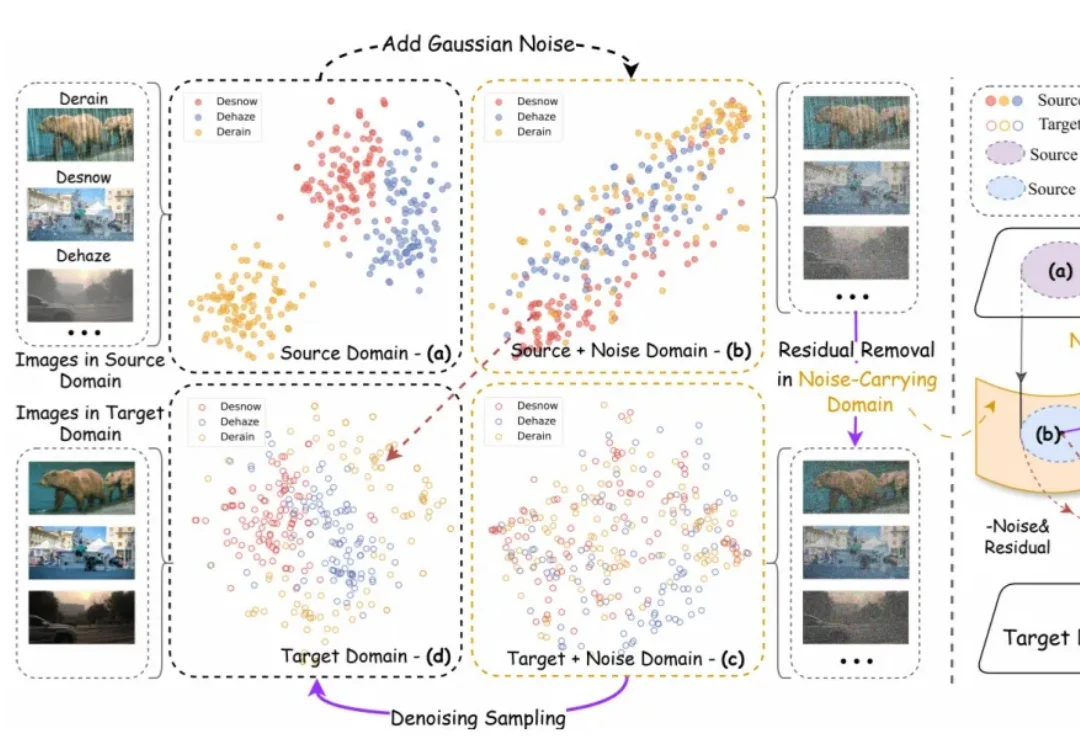
扩散模型里的噪声,原来还有这样的作用:DRDD重新定义统一图像翻译
扩散模型里的噪声,原来还有这样的作用:DRDD重新定义统一图像翻译在图像到图像翻译(Image-to-Image Translation, I2I)这个任务上,扩散模型过去几年几乎形成了一套默认逻辑:先把输入图像和噪声混合,再一步步去噪,把目标图像 “还原” 出来。
来自主题: AI技术研报
9350 点击 2026-06-10 15:15
 搜索
搜索
在图像到图像翻译(Image-to-Image Translation, I2I)这个任务上,扩散模型过去几年几乎形成了一套默认逻辑:先把输入图像和噪声混合,再一步步去噪,把目标图像 “还原” 出来。
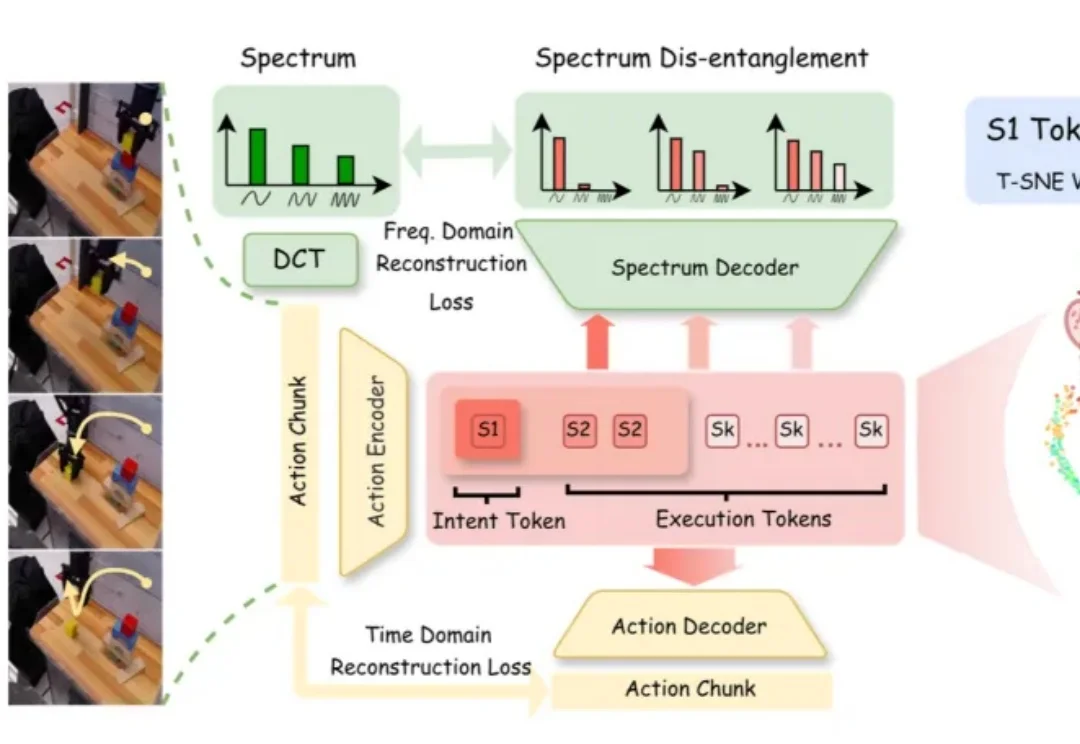
机器人视觉语言动作(Vision-Language-Action, VLA)模型越来越多地开始展示叠衣服、倒茶、做咖啡等复杂操作。但是,今天的大多数 VLA 更像 “展台机器人”。
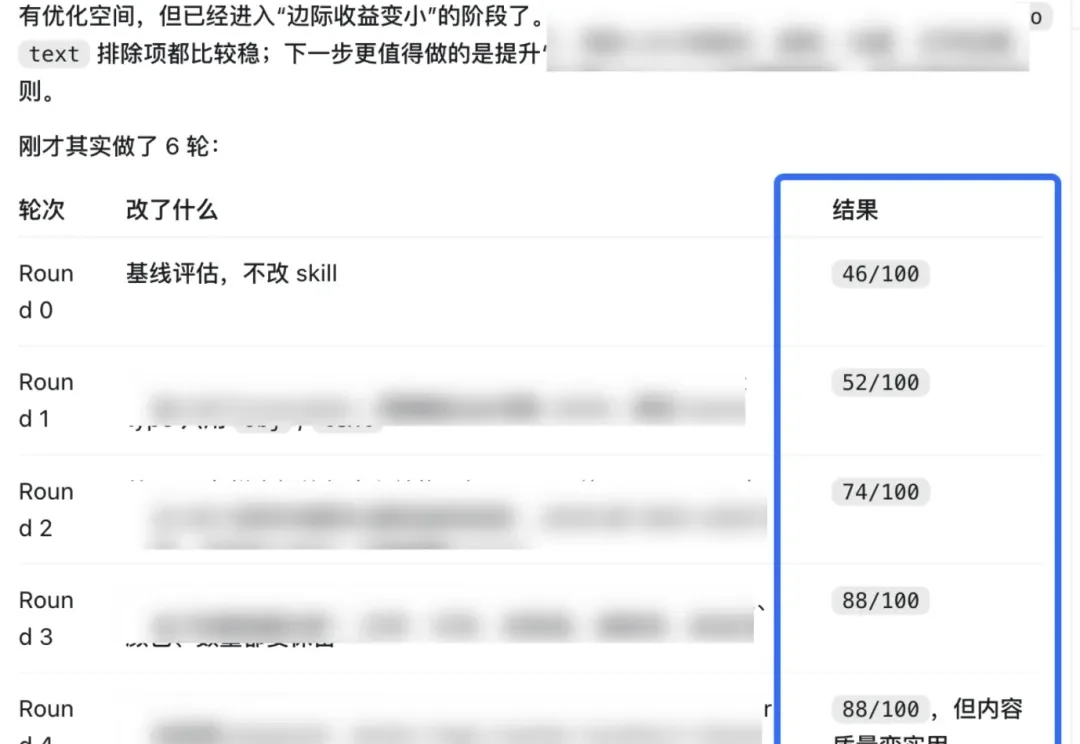
前几天我们讨论过一个观点:自从2026年Q2起,未来人类所谓的“编程工作”其实比拼的是「谁能一次性把“什么叫完成”定义清楚」

近日,清研精准完成数亿元B2轮融资,由星源资本领投,一汽富晟旗下吉晟资产、某央企产业基金跟投。本轮融资之后,清研精准将推动一次关键转向:以跑通新能源物理智能的闭环为起点,逐步迈向更广阔的工业场景,致力于打造工业物理AI的工程化底座,深度布局具身智能领域。

百亿美元,曾经是顶级独角兽的天花板,如今在火热的AI赛道,可能只是入场的起步价。

今日,美团GN06(原光年之外)团队正式发布AI浏览器Tabbit V1.0,并承诺核心功能将永久免费开放。Tabbit自3月2日开放公测至今,正好是100天,每周迭代,共迭代12个版本,收获了大量用户好评,比如“Windows上最好看的浏览器”、“特别务实的工具产品”、“低门槛且安全稳定地用到头部模型的方式”等等。
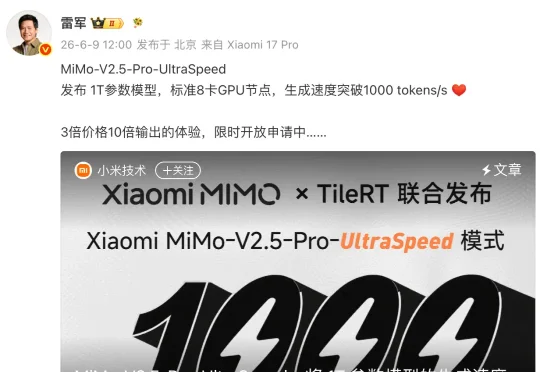
今日,小米MiMo团队与推理系统团队TileRT联合宣布,Xiaomi MiMo-V2.5-Pro的UltraSpeed模式已实现万亿参数(1T)旗舰模型输出速度首次突破1000 tokens/s。
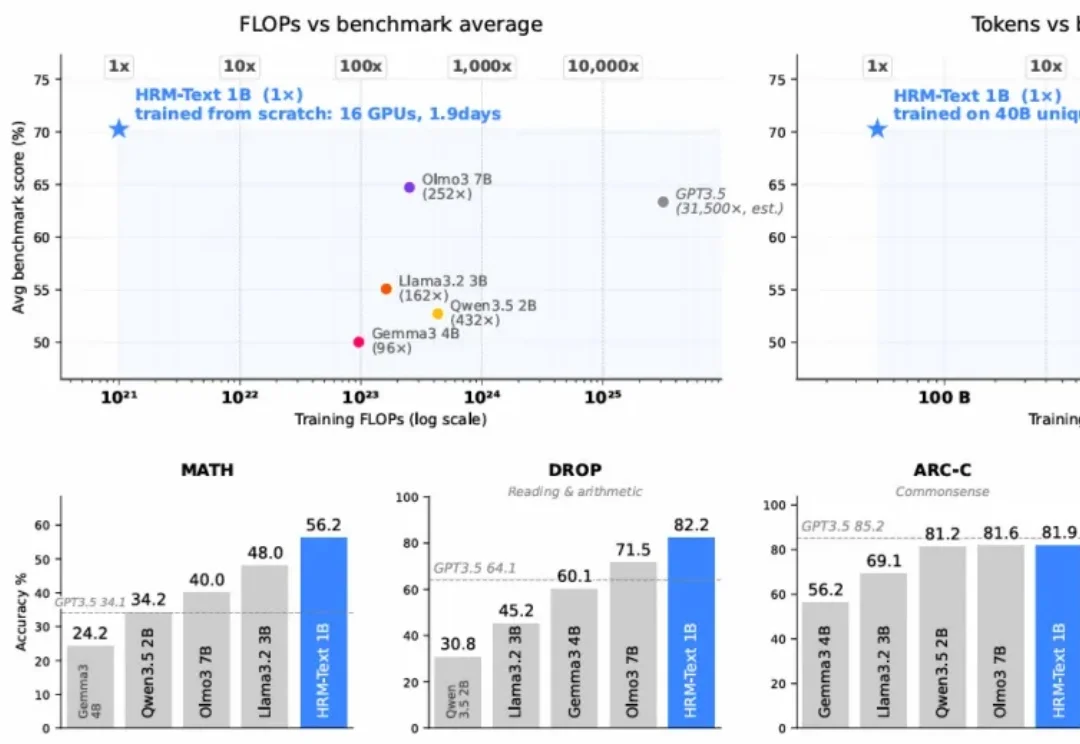
一个约 1B 参数的模型,在 MATH 上拿到 56.2,在 GSM8K 上拿到 84.5,在 ARC-Challenge 上拿到 81.9。训练成本约 1500 美元,16 块 H100 跑了不到两天。

昨天,奇绩创坛举办了 2026 年春季创业营路演日,共有 56 个项目上台。从赛道分布来看,覆盖: 智能体(39 家)、具身与物理智能(19 家)、数据(10 家)、AI 基础设施(14 家)、FDE & AI 咨询(10 家)。

几经波折之后,我们终于将手里的几台 iPhone 都更新到了 iOS 27,体验到了五年以来最重大的一次 Siri 更新。