“20世纪发明的所有职业,都难逃AI的冲击!”
“20世纪发明的所有职业,都难逃AI的冲击!”《黑天鹅》作者、以毒舌和高智商著称的纳西姆·塔勒布最近发了一条推文,只有一句话: “20世纪发明的所有职业,都难逃AI的冲击。”
来自主题: AI资讯
8846 点击 2026-05-21 16:08
 搜索
搜索
《黑天鹅》作者、以毒舌和高智商著称的纳西姆·塔勒布最近发了一条推文,只有一句话: “20世纪发明的所有职业,都难逃AI的冲击。”

如果把现在最热门的几条 3D 生成技术线放在一起看,你会发现它们正在遇到一个很像的问题。

专为 AI 构建搜索引擎的基础设施公司 Exa 宣布完成 2.5 亿美元 C 轮融资,投后估值达到 22 亿美元,由 a16z 领投,a16z 合伙人 Sarah Wang 主导了本轮交易。

就在刚刚,智谱率先在 GLM-5.1 线上生产集群中完成了新一代组网架构 ZCube 的规模化落地。ZCube 发表于网络领域顶会ACM SIGCOMM 2025,被评价为「significantly change the way we think about and understand networking/显著改变整个行业对网络认知方式」。

Agent不再只住在云端——联想携手此芯科技,把190 TOPS本地AI算力装进手掌大小的AI主机,让每个人都能拥有一座7×24小时运行的私人Token工厂。
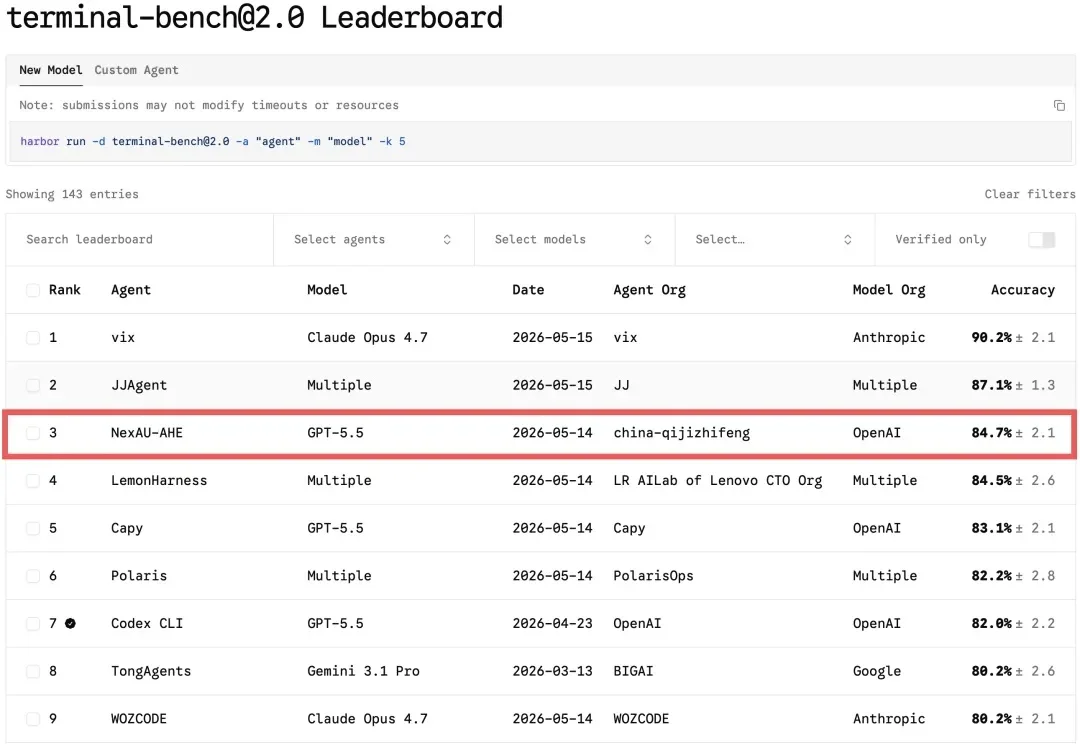
2026 年以来,OpenAI、Anthropic、LangChain 等机构纷纷发布关于 Harness Engineering 的技术博客,OpenClaw、Hermes Agent 等项目的火爆更让 Harness Engineering 成为业界热词。人们的共识正在形成:模型的能力释放,依赖于一套精密的外部框架。

智联招聘《2025雇佣关系趋势报告》显示,高达78.2%的职场人每周都会借助AI开展工作;另一份调研则指出,近五成职场人在过去一年被要求提升AI使用能力。

有一个问题,值得在2026年认真问一次—— 你上一次用AI应用,是让它回答了一个问题,还是让它完成了一件事?

2026年,AI产业正在进入新一轮高强度算力周期。
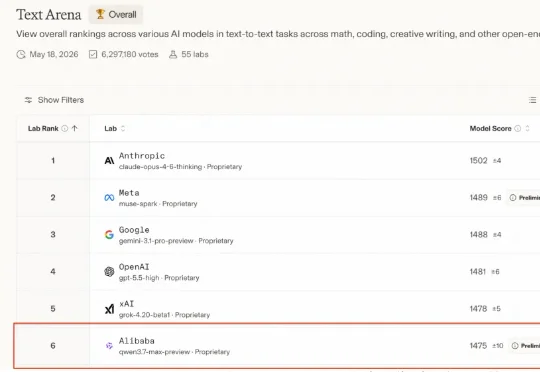
仅仅一个月后,阿里又带着最强旗舰模型杀回来了!今天上午,在 2026 阿里云峰会上,阿里全新一代千问旗舰模型 Qwen3.7-Max 登场了!在 Arena 公布的最新一期全球大模型盲测总榜中,Qwen3.7-Max 总成绩位列国产模型第一:傲视一众国产大模型