
WAIC机器人探展:我被全场最靓的崽「Moz1」种草了
WAIC机器人探展:我被全场最靓的崽「Moz1」种草了一年一度的世界人工智能大会现场探展,我们被这个「闲不住」的人形机器人圈粉了。2025 年行至过半,人工智能领域的前沿热点屡屡破圈,其中具身智能(Embodied AI)及其载体在国内格外受到了关注,尤其是人形机器人。
来自主题: AI资讯
8556 点击 2025-07-27 14:21
 搜索
搜索
一年一度的世界人工智能大会现场探展,我们被这个「闲不住」的人形机器人圈粉了。2025 年行至过半,人工智能领域的前沿热点屡屡破圈,其中具身智能(Embodied AI)及其载体在国内格外受到了关注,尤其是人形机器人。
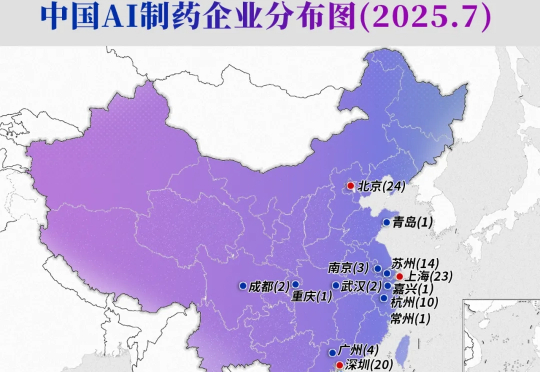
截至2025年7月,据智药局不完全统计,中国AI制药公司已经达到了108家。当前,中国AI+药物研发企业数量进入”百企时代”,成为生物医药领域的一支不容忽视的力量。94%的AI制药企业分布于北京、长三角及大湾区,其中北京、上海、深圳三城各集聚超20家企业。

在大语言模型席卷全球的时代,坚持更接近生命本质的智能是少有人走的路。2025年7月初,一篇来自Numenta与Thousand Brains Project的论文,首次通过一个名为“Monty”的AI系统,实验性地验证了神经科学家杰夫·霍金斯(Jeff Hawkins)提出的“千脑智能理论”。

在首次中国演讲中,AI教父Hinton于WAIC2025上探讨数字智能与生物智能的差异,指出AI因具备永生与高效共享而快速超越人脑。他警示若无全球安全协作,超级智能或将反噬人类。Hinton提出通过AI安全研究所联盟与技术栈分离,推动AI向善发展。
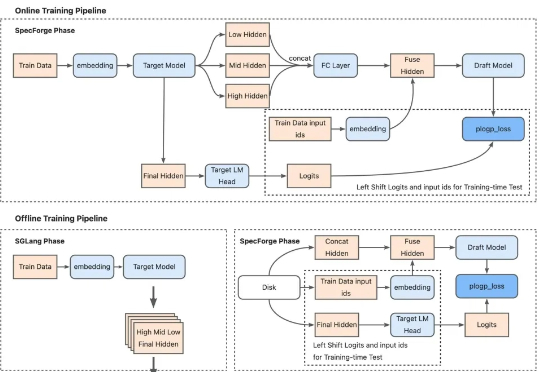
专门适用超大模型、带来2.18倍推理加速,最新投机采样训练框架开源! SGLang团队联合美团搜推平台、Cloudsway.AI开源SpecForge。
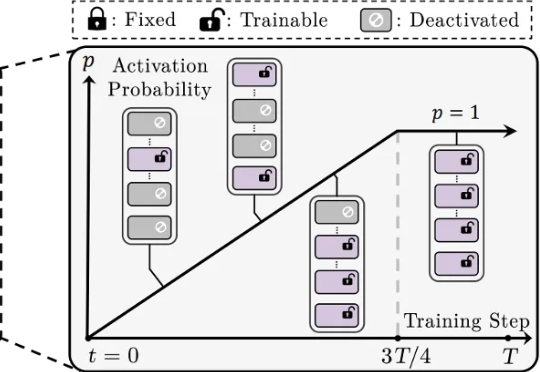
还在为 LoRA 训练不稳定、模型融合效果差、剪枝后性能大降而烦恼吗?来自香港城市大学、南方科技大学、浙江大学等机构的研究者们提出了一种简单的渐进式训练策略,CoTo,通过在训练早期随机失活一部分适配器,并逐渐提高其激活概率,有效缓解了层级不均衡问题,并显著增强了模型在多任务融合和剪枝等操作上的鲁棒性和有效性。该工作已被机器学习顶会 ICML 2025 接收。
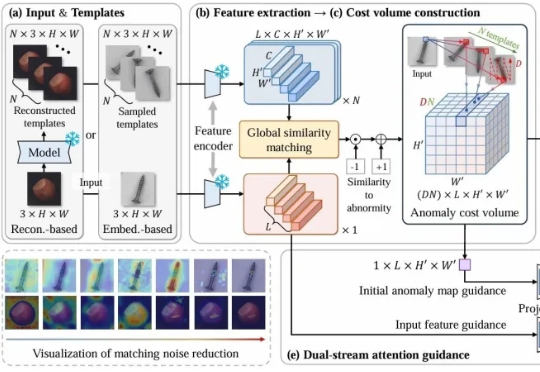
CostFilter-AD通过构建异常代价体并滤波来优化异常检测,能精准识别微小缺陷,无需缺陷样本训练。可作为通用插件提升现有检测系统,帮助工厂提前发现缺陷,提高产品质量。

2025年7月17日,在GenAI Assembling 第五期硅谷Meetup上,最近火热的明星AI Agent 公司Genspark、Lovart、和Simular.ai的创始人,以及新一代基础设施公司SambaNova的Agent技术负责人,一起讨论了他们在今天AI Agent发展第一线所观察和感受到的一切。

如果你因为太热、太懒、太忙,没法来WAIC;或者是来到展馆,却不知从何逛起,在这份指南里,我们帮你把重点划好了。7月26日,世界人工智能大会(WAIC 2025)在上海世博展览馆开幕。这是一年一度中国AI领域最重要的盛会,没有之一。

国内 AI 创企 RockAI 提出的非 Transformer 架构 Yan 2.0 Preview。这个架构极大地降低了模型推理时的计算复杂度,因此可以在算力非常有限的设备上离线运行,比如树莓派。