
LeCun亲自出镜打脸质疑者!憋了20年的AI世界模型,终于爆发了
LeCun亲自出镜打脸质疑者!憋了20年的AI世界模型,终于爆发了刚刚,LeCun竟然亲自出镜,重磅讲解了V-JEPA 2!就在外界猜测他已被边缘化之际,这位AI老将用一支视频回应了质疑:要坚定不移做世界模型!这位20年孤勇者押注的方向,是将引领AI的下一个潮流,还是走上了歧路?
来自主题: AI资讯
10559 点击 2025-06-12 15:01
 搜索
搜索
刚刚,LeCun竟然亲自出镜,重磅讲解了V-JEPA 2!就在外界猜测他已被边缘化之际,这位AI老将用一支视频回应了质疑:要坚定不移做世界模型!这位20年孤勇者押注的方向,是将引领AI的下一个潮流,还是走上了歧路?
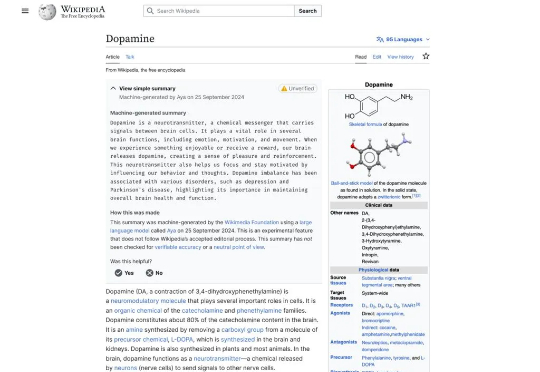
6 月 12 日消息,科技媒体 404Media 昨日(6 月 11 日)发布博文,报道称在维基百科编辑们的强烈反对下,维基媒体基金会(Wikimedia Foundation)宣布暂停测试 AI 文章摘要功能。
2025年是AI Agent爆发之年。
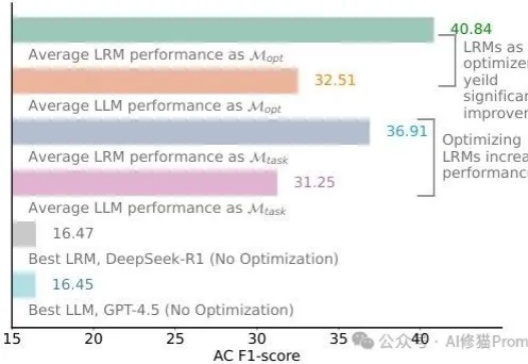
还记得DeepSeek-R1发布时AI圈的那波狂欢吗?"提示工程已死"、"再也不用费心写复杂提示了"、"推理模型已经聪明到不再需要学习提示词了"......这些观点在社交媒体上刷屏,连不少技术大佬都在转发。再到最近,“提示词写死了”......现实总是来得这么快——乔治梅森大学的研究者们用一个严谨得让人无法反驳的实验,狠狠打了所有人的脸!
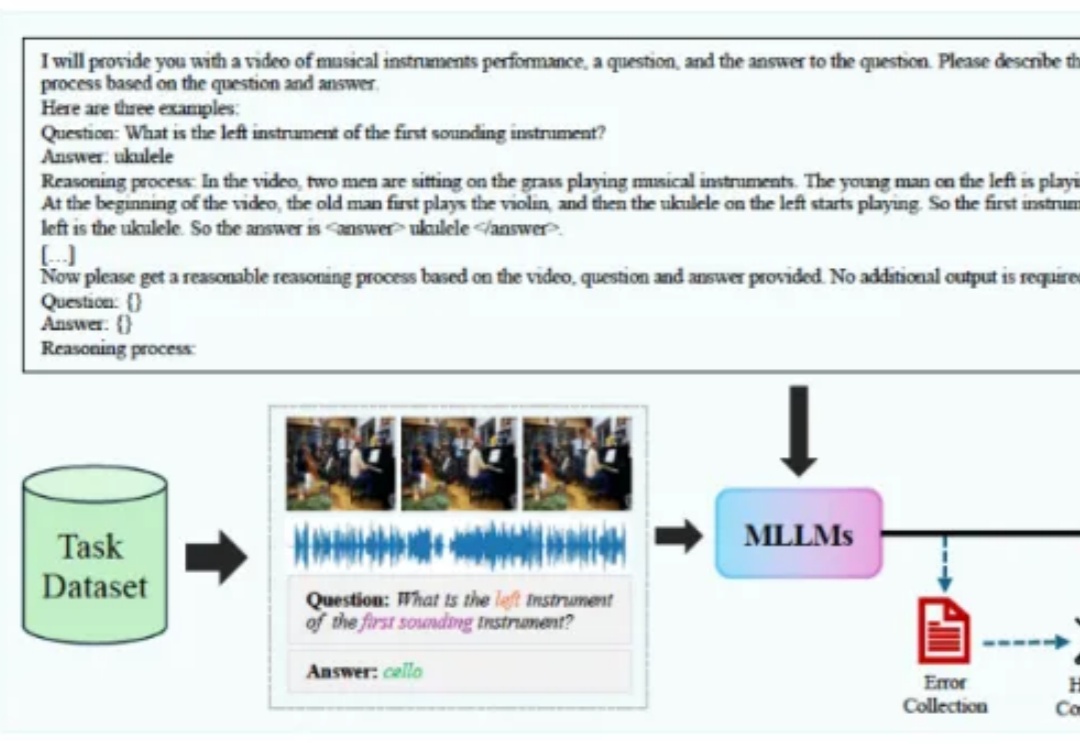
我们人类生活在一个充满视觉和音频信息的世界中,近年来已经有很多工作利用这两个模态的信息来增强模型对视听场景的理解能力,衍生出了多种不同类型的任务,它们分别要求模型具备不同层面的能力。
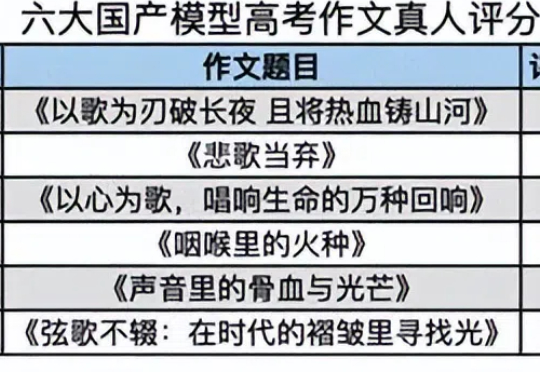
"AI装饰了你的梦,你成为了AI的韭菜" 6月7日-10日,2025年高考,1335万人参加。 如按参加高考学生平均年龄18岁计算,那么他们是第一批被AI深度影响的高考生——2022年OpenAI走红,这批学生刚进入高中。

多鲸即将发布《2025 AI 赋能教育行业发展趋势报告》,该文为预览先导精彩内容。本文将从 AI 如何驱动教育「需求演进」、AI 在「场景创新」中的具体应用,以及由此形成的「生态融合与市场爆发」这四个维度,深入探讨 AI+教育的未来图景。

就在刚刚,Meta 又有新的动作,推出基于视频训练的世界模型 V-JEPA 2(全称 Video Joint Embedding Predictive Architecture 2)。其能够实现最先进的环境理解与预测能力,并在新环境中完成零样本规划与机器人控制。

2025年5月,美国数字健康企业 Akido Labs 宣布完成6000万美元B轮融资,由 McKesson Ventures 和 Polaris Partners 联合领投,老股东 Andreessen Horowitz(a16z)与 SVB Capital 跟投。融资所得将主要用于扩大其核心平台 ScopeAI 的部署,尤其是在医疗资源匮乏的社区加速落地。
企业搜索聊天机器人开发商 Glean 在威灵顿管理公司领投的 F 轮融资中筹集了 1.5 亿美元。这再次表明投资者对企业搜索市场的乐观态度,该领域还有亚马逊云服务、谷歌、Snowflake 等竞争者参与角逐。