

英伟达3D模型打造“AI建筑师特工队”,8位华人合著,包括千问实习生
英伟达3D模型打造“AI建筑师特工队”,8位华人合著,包括千问实习生英伟达新论文让AI学会先盖房、再装修。
来自主题: AI技术研报
7661 点击 2026-02-04 17:26
英伟达新论文让AI学会先盖房、再装修。
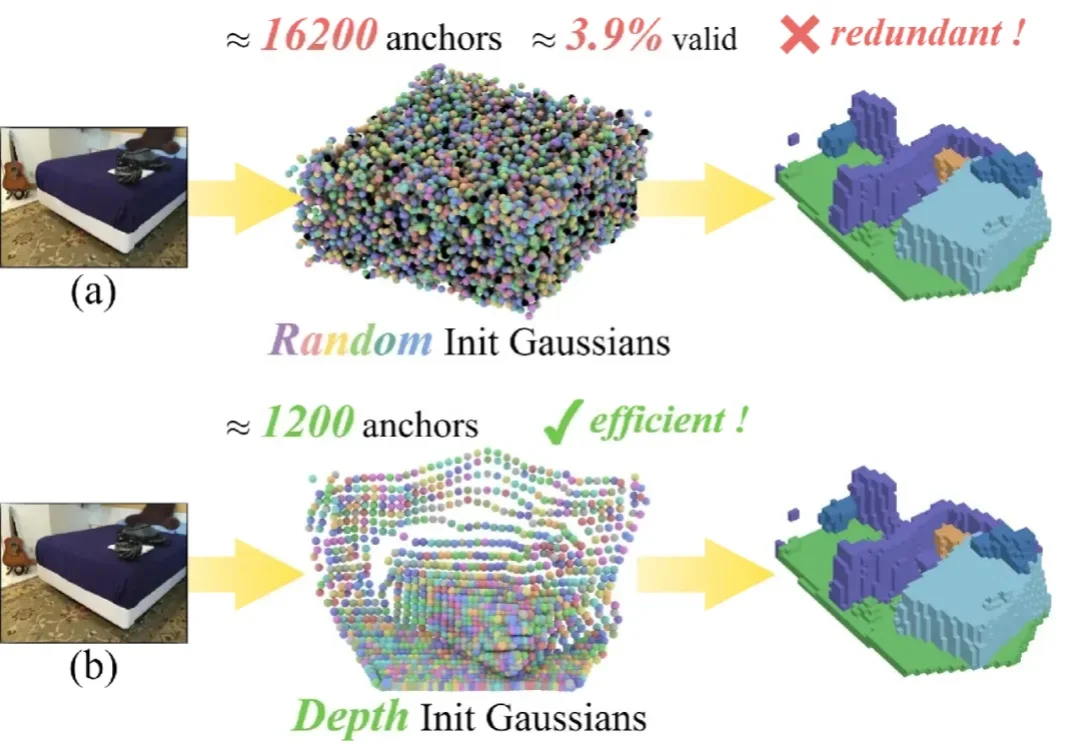
单目 3D 语义场景补全 (Semantic Scene Completion, SSC) 是具身智能与自动驾驶领域的一项核心技术,其目标是仅通过单幅图像预测出场景的密集几何结构与语义标签。
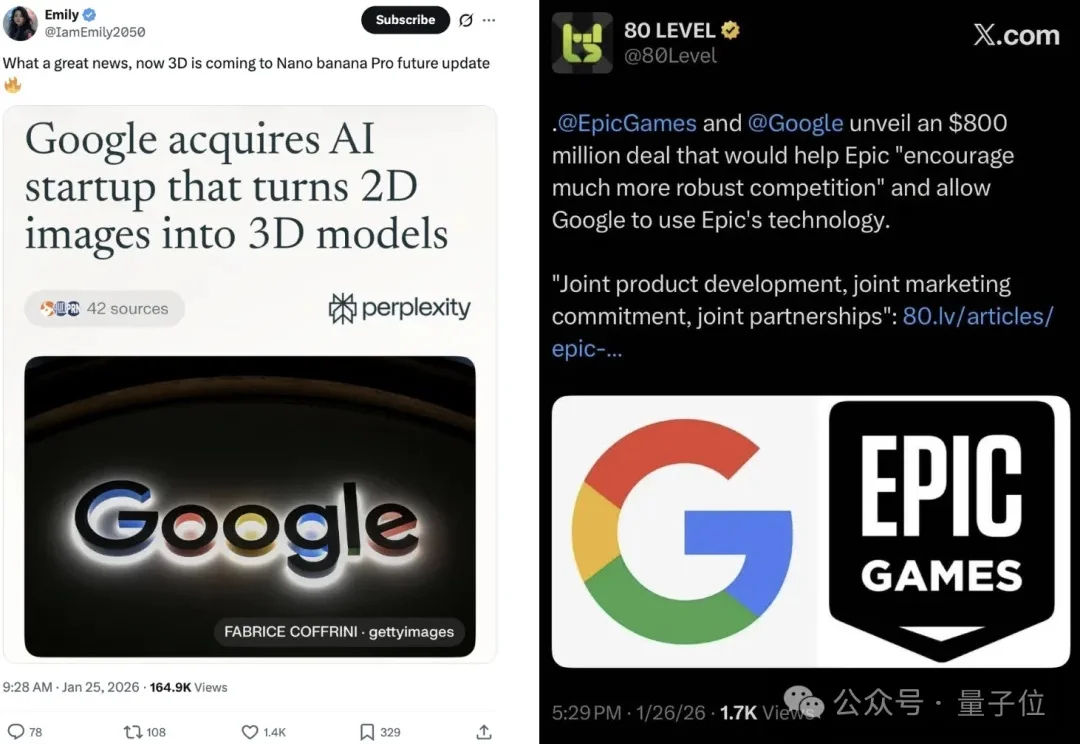
过去一年,AI的主战场几乎被大模型、生图和生视频占满。2026年伊始,市场终于开始把目光投向一个更难、也更关键的领域:3D生成。

周末看到一个好玩的东西。 3D领域的NanoBanana也来了。 中间有一句比较重要的功能,是我觉得非常有意思的: 可以通过提示进行局部编辑。 玩过NanoBanana的肯定很熟了。 算了补全了一块有
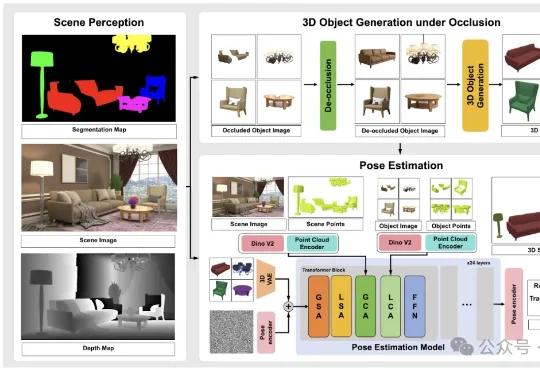
IDEA研究院张磊团队与香港科技大学谭平团队联合推出SceneMaker框架,有望攻克这一问题。 它以视启未来的万物检测模型DINO-X与光影焕像的万物3D生成模型Triverse为基础,实现了从任意开放世界图像(室内/室外/合成图等)到带Mesh的3D场景的完整重建。

上海交通大学、波恩大学等院校的研究团队全面总结了当前机器人技术中常用的场景表示方法。这些方法包括传统的点云、体素栅格、符号距离函数以及场景图等传统几何表示方式,同时也涵盖了最新的神经网络表示技术,如神经辐射场、3D 高斯散布模型以及新兴的 3D 基础模型。
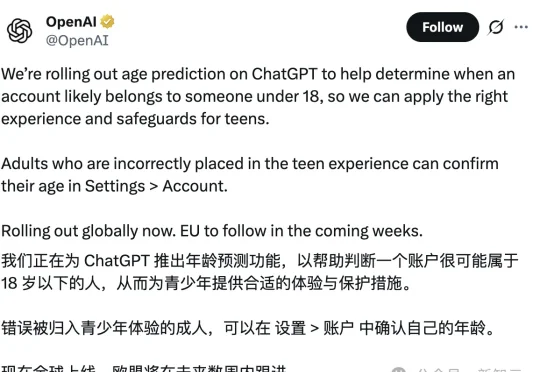
ChatGPT也推出「防沉迷系统」了?如果你习惯用缩写、语气太嫩,或者仅仅是作息不规律,都可能被判定为未成年!想恢复成人权限,代价是上传你的脸部3D扫描数据。不需要等到未来,欢迎来到2026年的「行为算命」时代。

2025年,风光无限的机器人们在Demo中大秀绝活,从叠衣服、工厂和物流站分拣包裹,到零售店卖货……它们忙碌的身影存在于各种各样的场景中。但回到现实世界,具身智能真正参与的生活和生产环节,却少之又少。
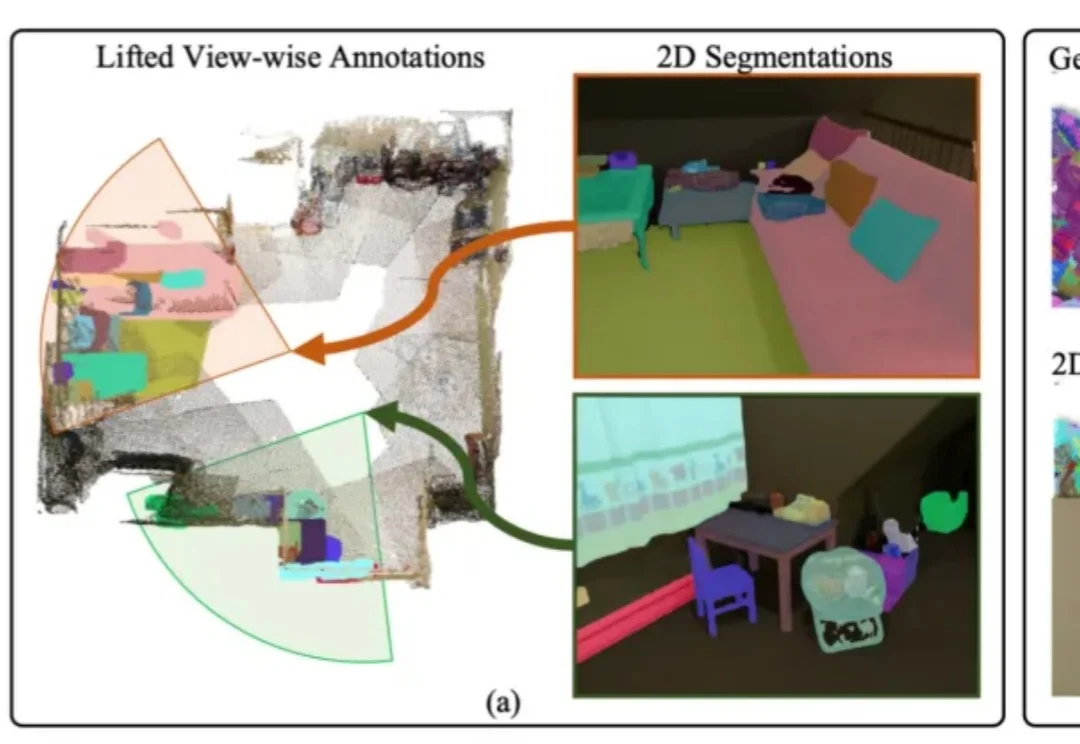
3D模型的实例分割一直受限于稀缺的训练数据与高昂的标注成本,训练效果有待提升。
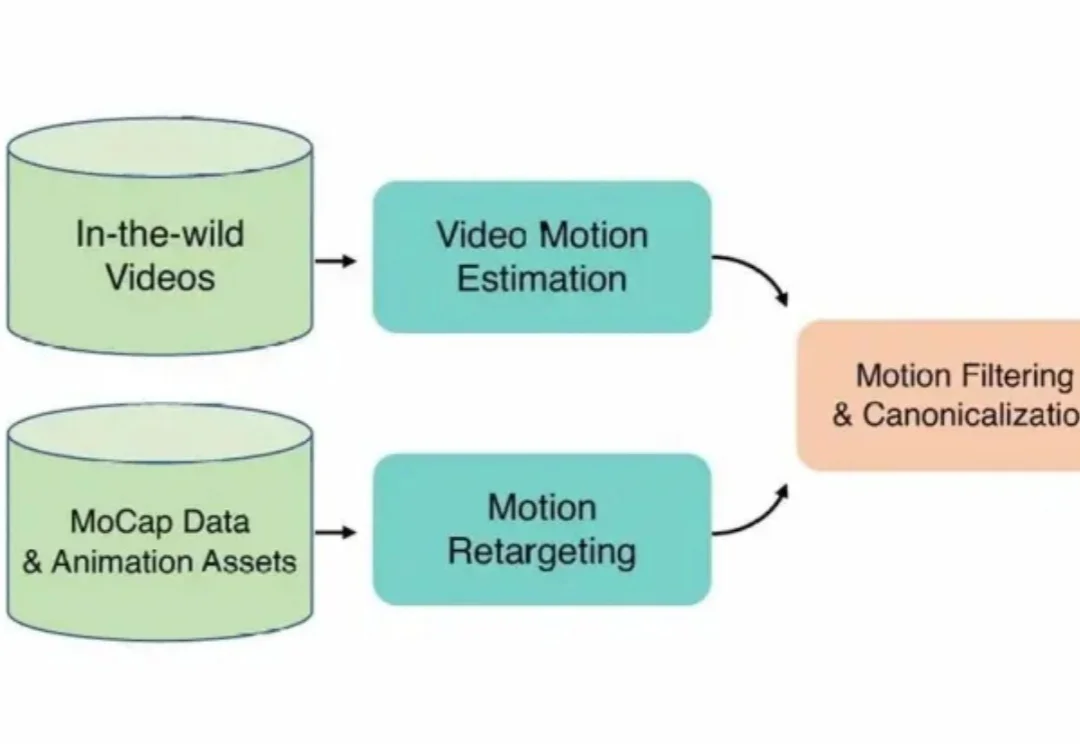
在3D角色动画创作领域,高质量动作资产的匮乏长期制约着产出的上限。