
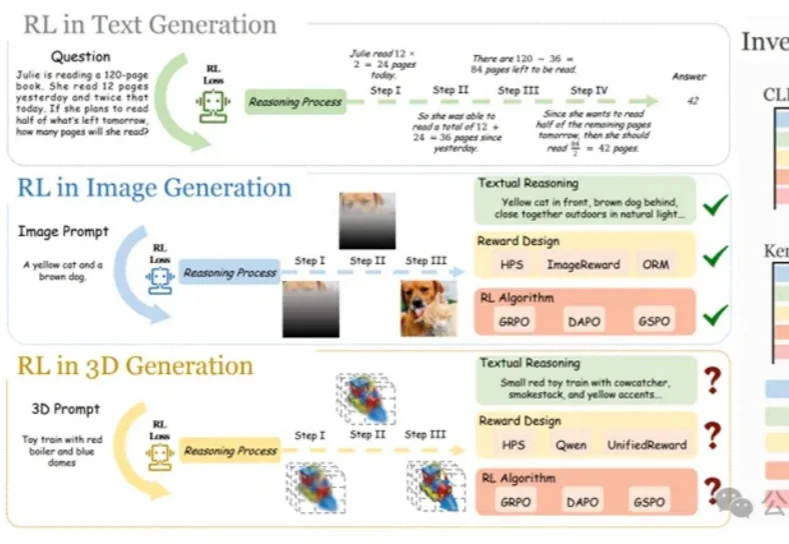
首个文本到3D生成RL范式诞生,攻克几何与物理合理性
首个文本到3D生成RL范式诞生,攻克几何与物理合理性在大语言模型和文生图领域,强化学习(RL)已成为提升模型思维链与生成质量的关键方法。
来自主题: AI技术研报
6500 点击 2025-12-22 09:38
在大语言模型和文生图领域,强化学习(RL)已成为提升模型思维链与生成质量的关键方法。

智东西12月19日报道,由三名00后武汉大学校友创办的大模型领域科技创企模态跃迁(MercAllure),已完成两轮累计数千万元融资,投资方包括深圳高新投、力合科创、楚天凤鸣天使基金、武汉基金、奇绩创坛等机构。

在计算机图形学、三维视觉、虚拟人、XR 领域,SIGGRAPH 是毫无争议的 “天花板级会议”。 SIGGRAPH Asia 作为 SIGGRAPH 系列两大主会之一,每年只接收全球最顶尖研究团队的成果稿件,代表着学术与工业界的最高研究水平与最前沿技术趋势。
继 SAM(Segment Anything Model)、SAM 3D 后,Meta 又有了新动作。
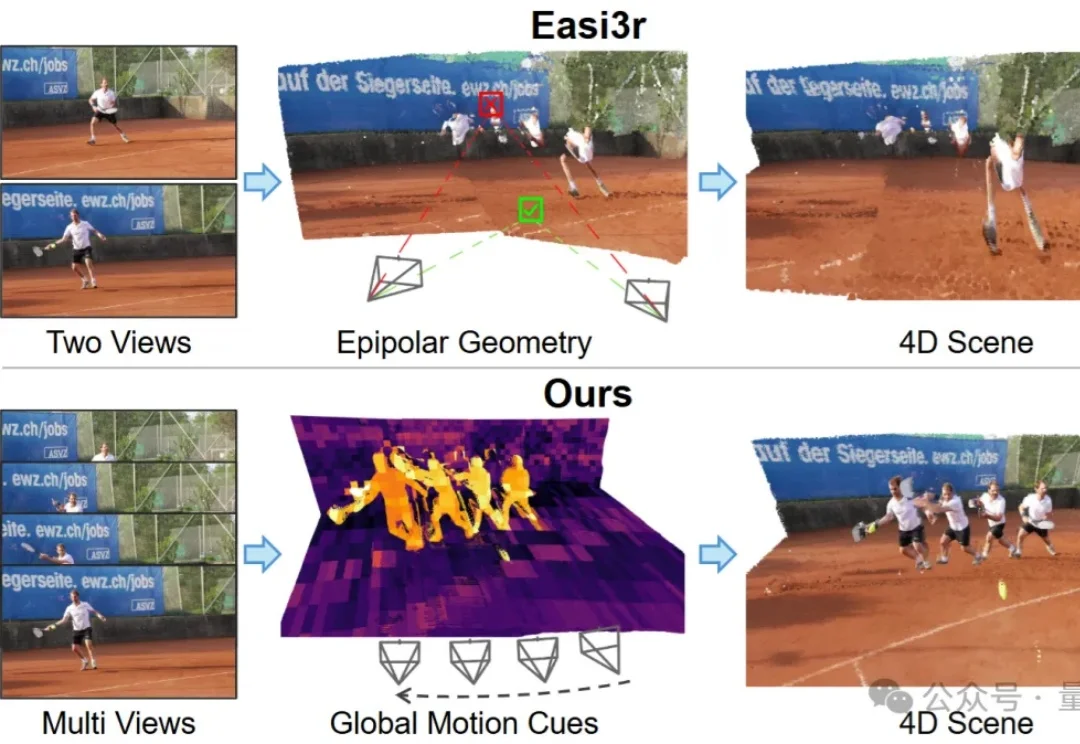
如何让针对静态场景训练的3D基础模型(3D Foundation Models),在不增加训练成本的前提下,具备处理动态4D场景的能力?
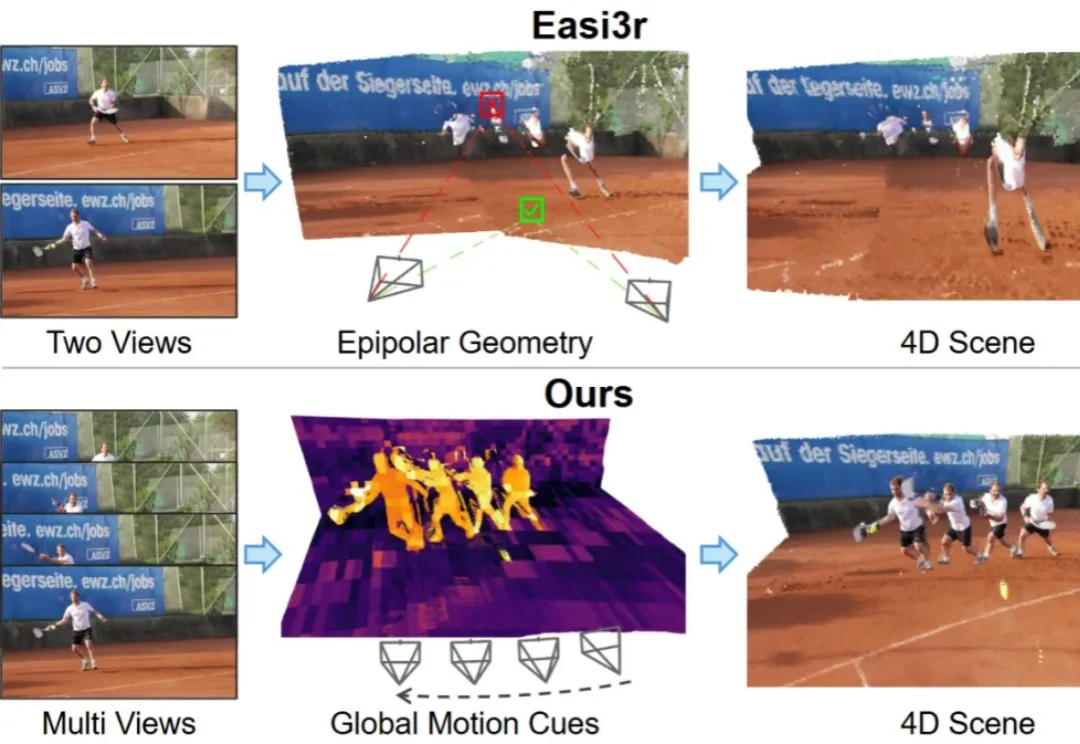
如何让针对静态场景训练的 3D 基础模型(3D Foundation Models)在不增加训练成本的前提下,具备处理动态 4D 场景的能力?
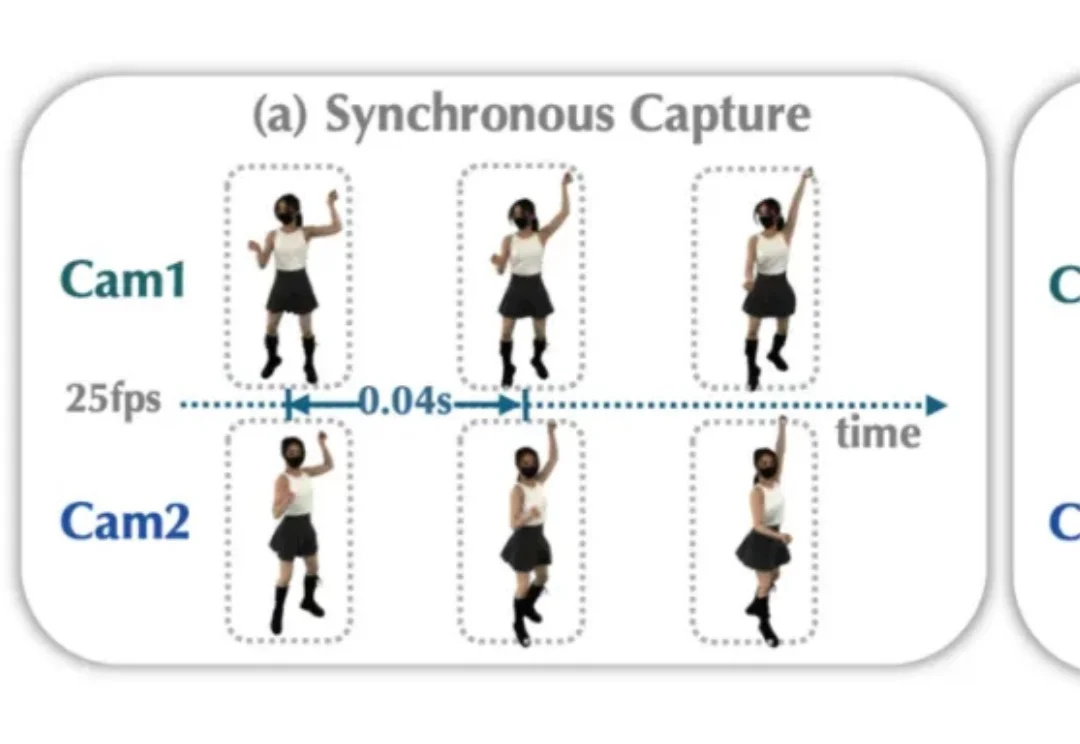
当古装剧中的长袍在武林高手凌空翻腾的瞬间扬起 0.01 秒的惊艳弧度,当 VR 玩家想伸手抓住对手 “空中定格” 的剑锋,当 TikTok 爆款视频里一滴牛奶皇冠般的溅落要被 360° 无死角重放 —— 如何用普通的摄像机,把瞬间即逝的高速世界 “冻结” 成可供反复拆解、传送与交互的数字化 4D 时空,成为 3D 视觉领域的一个难题。

他是SIGGRAPH 50年历史上第一位、也是迄今唯一一位登上大会主题演讲舞台的中国人,与英伟达黄仁勋等行业领袖同台。

无需懂一行代码,Gemini 3正在重塑3D交互创作的边界!详细对比了Canvas与AI Studio在开发场景下的独特优势,带你亲身体验这场「零门槛」的3D交互革命。

奥特曼又得拉响红色警报了。刚刚,谷歌再次扔出重磅炸弹——Gemini 3 Deep Think正式上线!轻松把草图变成逼真3D场景,不仅结构还原到位,就连镂空花纹与光影都处理得明明白白。