

百倍提升7B模型推理能力!颜水成团队携手新加坡南洋理工大学发布Q*算法
百倍提升7B模型推理能力!颜水成团队携手新加坡南洋理工大学发布Q*算法近日,一篇出自中国团队之手的AI论文在外网引发热议。论文中,研究团队提出了Q*模型算法,帮助Llama-2-7b等小模型达到参数量比其大数十倍、甚至上百倍模型的推理能力,使模型性能迎来惊人提升。
来自主题: AI资讯
11733 点击 2024-06-26 10:57
近日,一篇出自中国团队之手的AI论文在外网引发热议。论文中,研究团队提出了Q*模型算法,帮助Llama-2-7b等小模型达到参数量比其大数十倍、甚至上百倍模型的推理能力,使模型性能迎来惊人提升。
自 OpenAI 的 Q* 项目曝光后,引发业内众多讨论。据现有信息汇总,Q* 项目被视作 OpenAI 在探索人工通用智能(Artificial General Intelligence, AGI)道路上的一次重大尝试,有望在包括数学问题解决能力、自主学习和自我改进等多个层面对人工智能技术带来革新性突破。

大模型执行图推理任务,我们是希望大模型仅仅给出结果,还是在给出准确答案的同时,输出详细的推理过程?
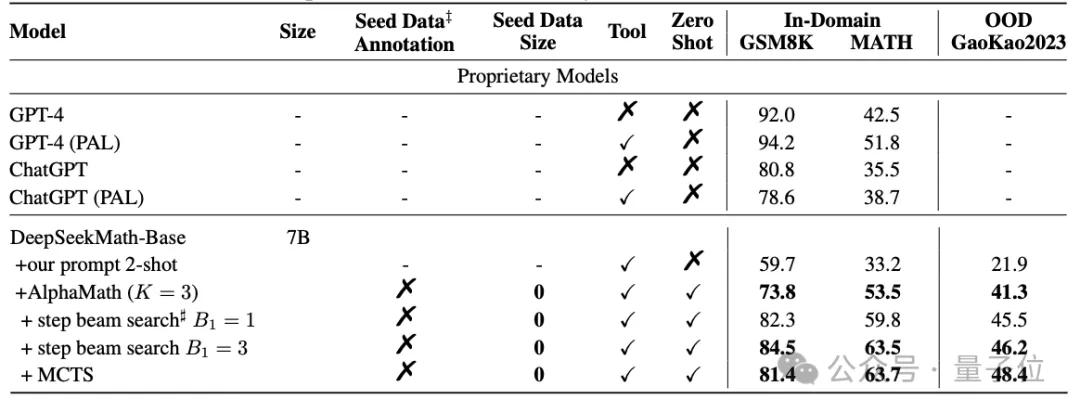
把AlphaGo的核心算法用在大模型上,“高考”成绩直接提升了20多分。

基于 Transformer 架构的大语言模型在 NLP 领域取得了令人惊艳的效果,然而,Transformer 中自注意力带来的二次复杂度使得大模型的推理成本和内存占用十分巨大,特别是在长序列的场景中。

大模型内卷时代,也不断有人跳出来挑战Transformer的统治地位,RWKV最新发布的Eagle 7B模型登顶了多语言基准测试,同时成本降低了数十倍

Mixtral 8x7B模型开源后,AI社区再次迎来一大波微调实践。来自Nous Research应用研究小组团队微调出新一代大模型Nous-Hermes 2 Mixtral 8x7B,在主流基准测试中击败了Mixtral Instruct。

爆火社区的Mixtral 8x7B模型,今天终于放出了arXiv论文!所有模型细节全部公开了。

近日,来自华为诺亚方舟实验室、北京大学等机构的研究者提出了盘古 π 的网络架构,尝试来构建更高效的大模型架构。

研究人员利用GPT4-Vision构建了一个大规模高质量图文数据集ShareGPT4V,并在此基础上训练了一个7B模型,在多项多模态榜单上超越了其他同级模型。