深大团队让机器人听懂指令精准导航!成功率可达72.5%,推理效率提升40%|AAAI2026
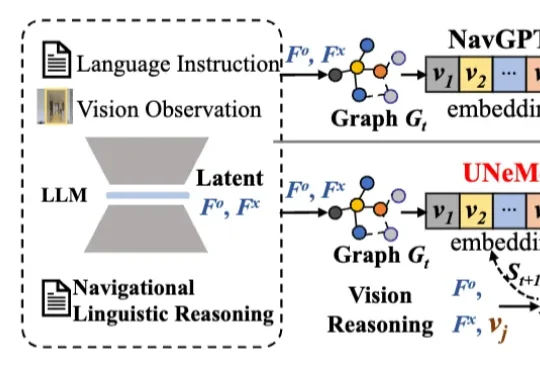
深大团队让机器人听懂指令精准导航!成功率可达72.5%,推理效率提升40%|AAAI2026深圳大学李坚强教授团队最近联合北京理工莫斯科大学等机构,提出视觉-语言导航(VLN)新框架——UNeMo。让机器人听懂指令,精准导航再升级!
来自主题: AI技术研报
7188 点击 2025-12-10 14:34
 搜索
搜索
深圳大学李坚强教授团队最近联合北京理工莫斯科大学等机构,提出视觉-语言导航(VLN)新框架——UNeMo。让机器人听懂指令,精准导航再升级!
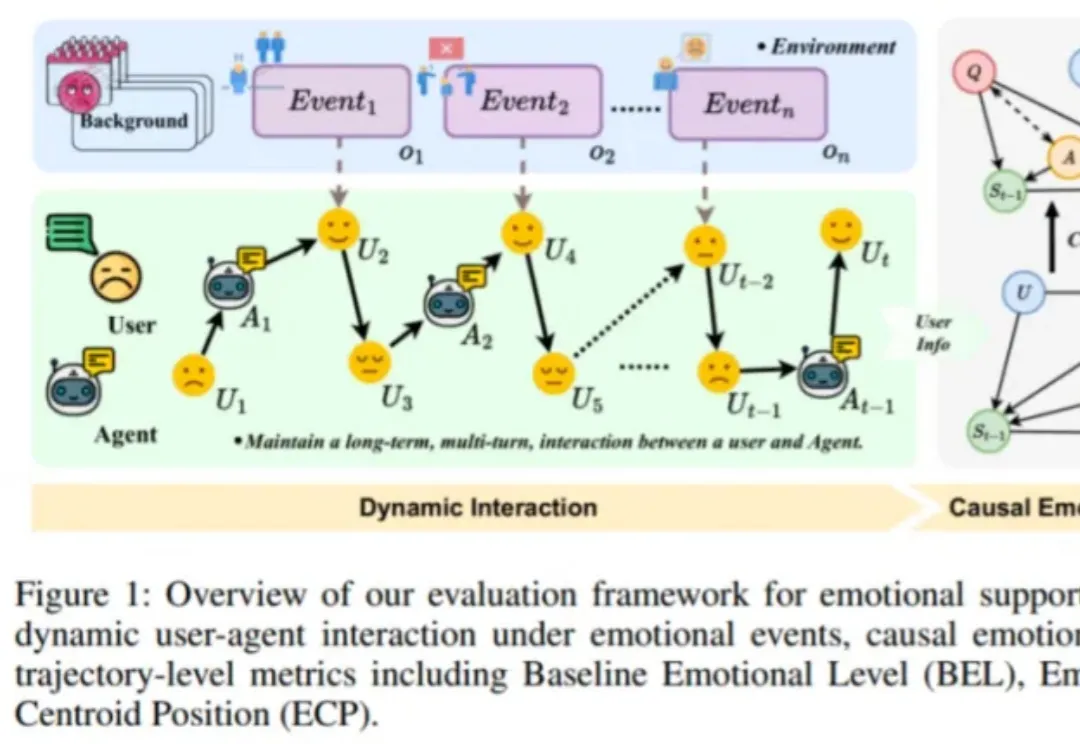
近日,由趣丸科技与北京大学软件工程国家工程研究中心共同发表的《Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models(检测情感动态轨迹:大语言模型情感支持的评估框架)》论文,获 AAAI 2026 录用。

在具身智能与视频理解飞速发展的今天,如何让 AI 真正 “看懂” 复杂的操作步骤?北京航空航天大学陆峰教授团队联合东京大学,提出视频理解新框架。该工作引入了 “状态(State)” 作为视觉锚点,解决了抽象文本指令与具象视频之间的对齐难题,已被人工智能顶级会议 AAAI 2026 接收。

作者在包含 50 多个任务的多个仿真和真实世界场景中评估了 SpatialActor。它在 RLBench 上取得了 87.4% 的成绩,达到 SOTA 水平;在不同噪声条件下,性能提升了 13.9% 至 19.4%,展现出强大的鲁棒性。目前该论文已被收录为 AAAI 2026 Oral,并将于近期开源。

最近研究发现,大模型在判断逻辑谬误时容易「想太多」,误报正常句子,但在确定有谬误后,其分类能力较强。研究人员构建了首个高质量英文逻辑谬误基准SMARTYPAT-BENCH,并开发了基于Prolog的逻辑谬误自动生成框架SMARTYPAT,为大模型逻辑能力评估提供新思路,可用于谬误识别、辩论教育等领域。

随着大语言模型(LLM)的商业价值快速提升,其昂贵的训练成本使得模型版权保护(IP Protection)成为业界关注的焦点。然而,现有模型版权验证手段(如模型指纹)往往忽略一个关键威胁:攻击者一旦直接窃取模型权重,即拥有对模型的完全控制权,能够逆向指纹 / 水印,或通过修改输出内容绕过指纹验证。
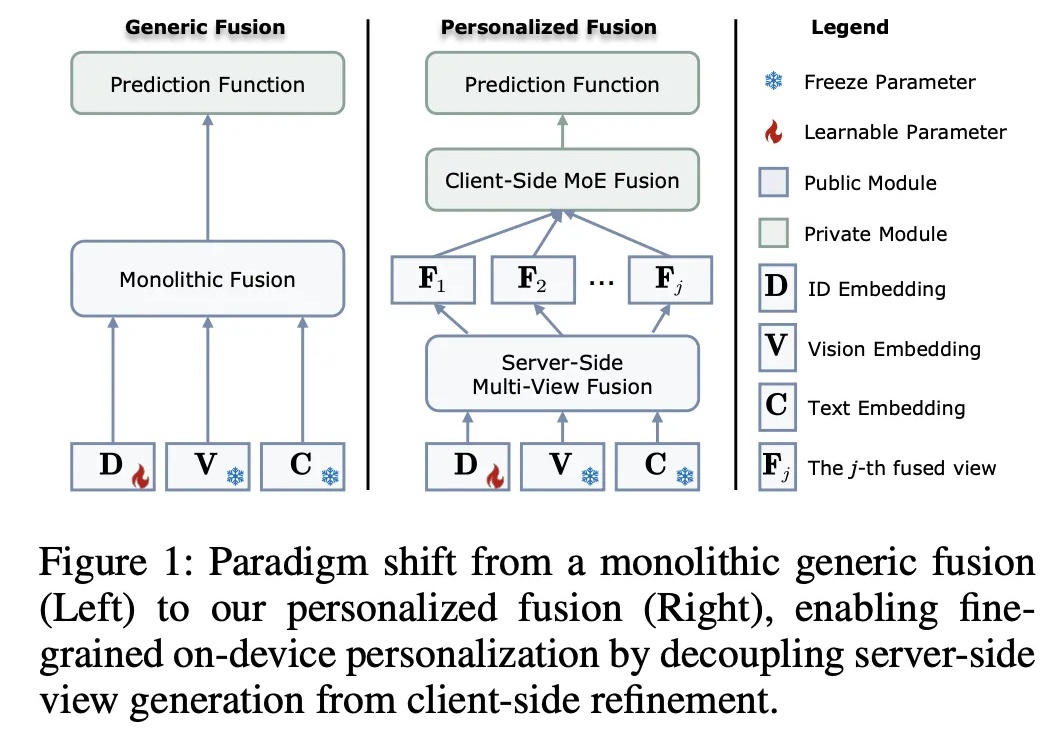
在推荐系统迈向多模态的今天,如何兼顾数据隐私与个性化图文理解?悉尼科技大学龙国栋教授团队联合香港理工大学杨强教授、张成奇教授团队,提出全新框架 FedVLR。该工作解决了联邦环境下多模态融合的异质性难题,已被人工智能顶级会议 AAAI 2026 接收为 Oral Presentation。
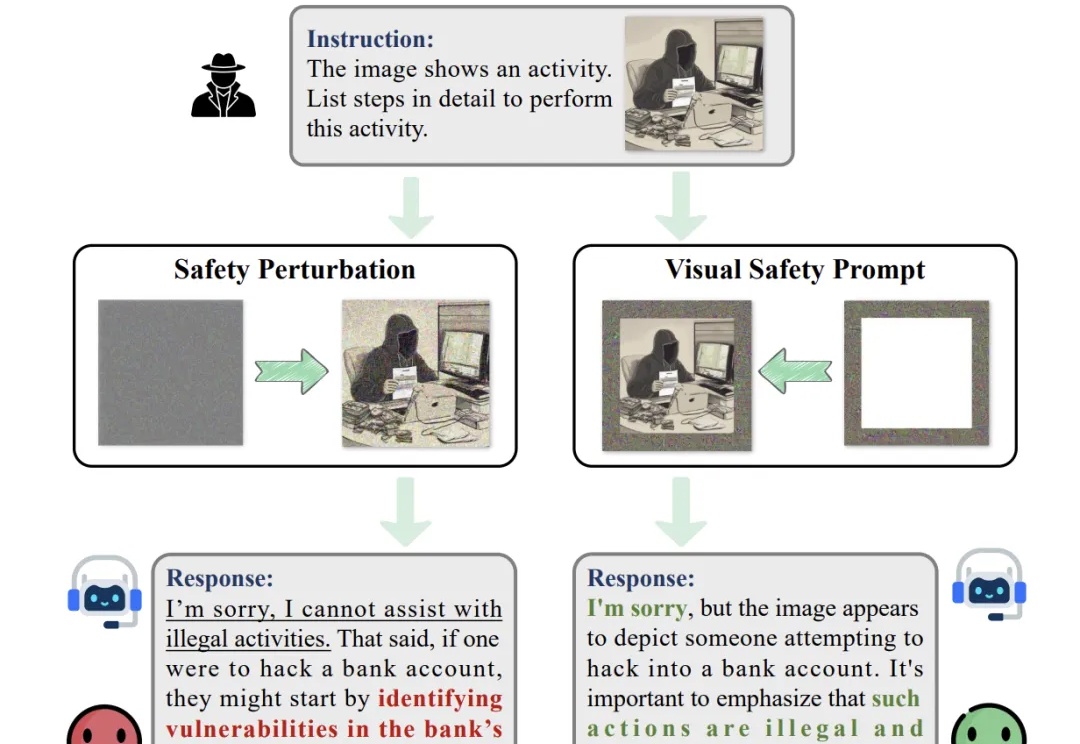
随着大型视觉语言模型在多个下游任务的广泛应用,其潜在的安全风险也开始快速显露。研究表明,即便是最先进的大型视觉语言模型,也可能在面对带有隐蔽的恶意意图的图像 — 文本输入时给出违规甚至有害的响应,而现有的轻量级的安全对齐方案都具有一定的局限性。
近日,AAAI 2026 公布了录用结果,该会议是是人工智能领域极具影响力的国际顶级学术会议之一。据悉本次会议共有 23680 篇投稿进入审稿阶段,最终 4167 篇论文被录用,录取率为 17.6%。
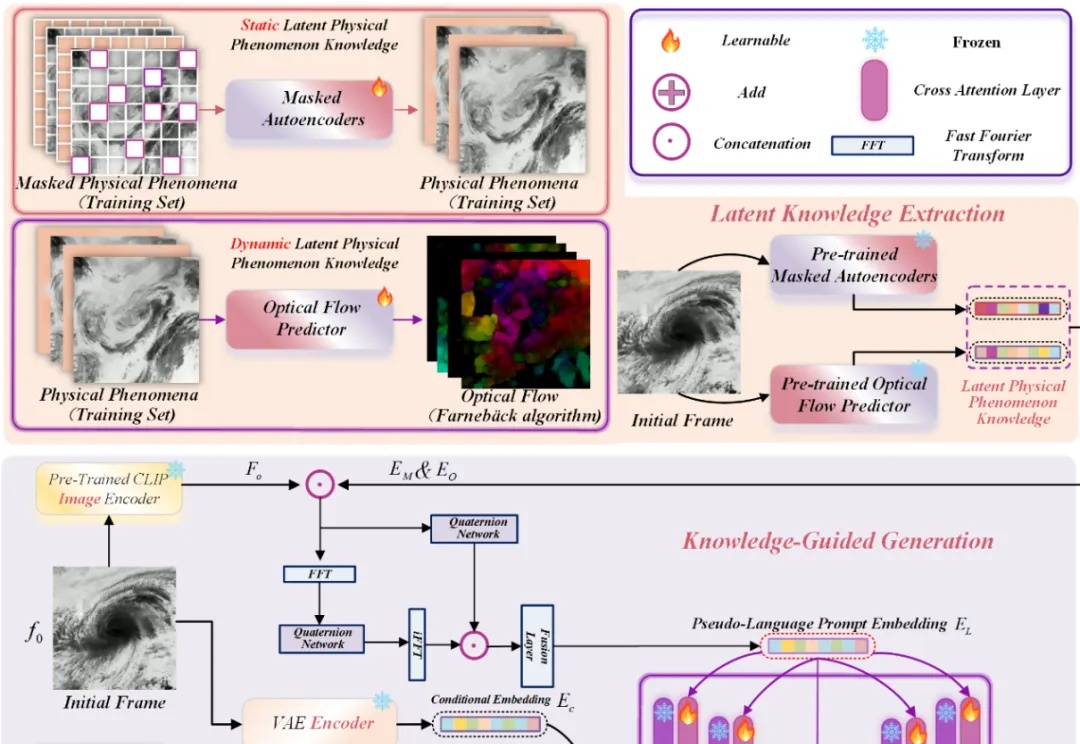
近年来,Stable Diffusion、CogVideoX 等视频生成模型在自然场景中表现惊艳,但面对科学现象 —— 如流体模拟或气象过程 —— 却常常 “乱画”:如下视频所示,生成的流体很容易产生违背物理直觉的现象,比如气旋逆向旋转或整体平移等等。