
两位95后打造“伴身智能”硬件,获商汤国香、奇绩创坛千万元级投资
两位95后打造“伴身智能”硬件,获商汤国香、奇绩创坛千万元级投资一枚戒指里的“Token经济学”。
来自主题: AI资讯
10111 点击 2026-04-09 10:20
 搜索
搜索
一枚戒指里的“Token经济学”。

从高价值商业场景切入,打造“真通用”的具身智能。
AI生成图表,难道只能靠碰运气?

我认真看 Hermes Agent,不是因为它2.9万Star,而是因为那条 hermes claw migrate。一个新框架敢把"把旧用户整套资产搬过来"做成默认入口,这事本身就很说明问题。

黄仁勋用「五层蛋糕」讲清了AI全栈生态的分层逻辑,易鑫则把它翻译成汽车金融的落地打法:从算力、模型到Agent落地,解决的全是汽车金融最难的活。

2026年,“自进化”这个词被AI行业大拿高频提及。

总部位于首尔的 Wrtn Technologies 表示,该公司通过为韩国和日本的硬核动漫和游戏粉丝运营 AI 故事讲述应用,每月产生超过 800 万美元的收入。Wrtn(发音为"written")即将以一款名为 OOC("out of character"的缩写)的类似应用扩展到美国市场,这是龙与地下城角色扮演游戏中的常用术语。
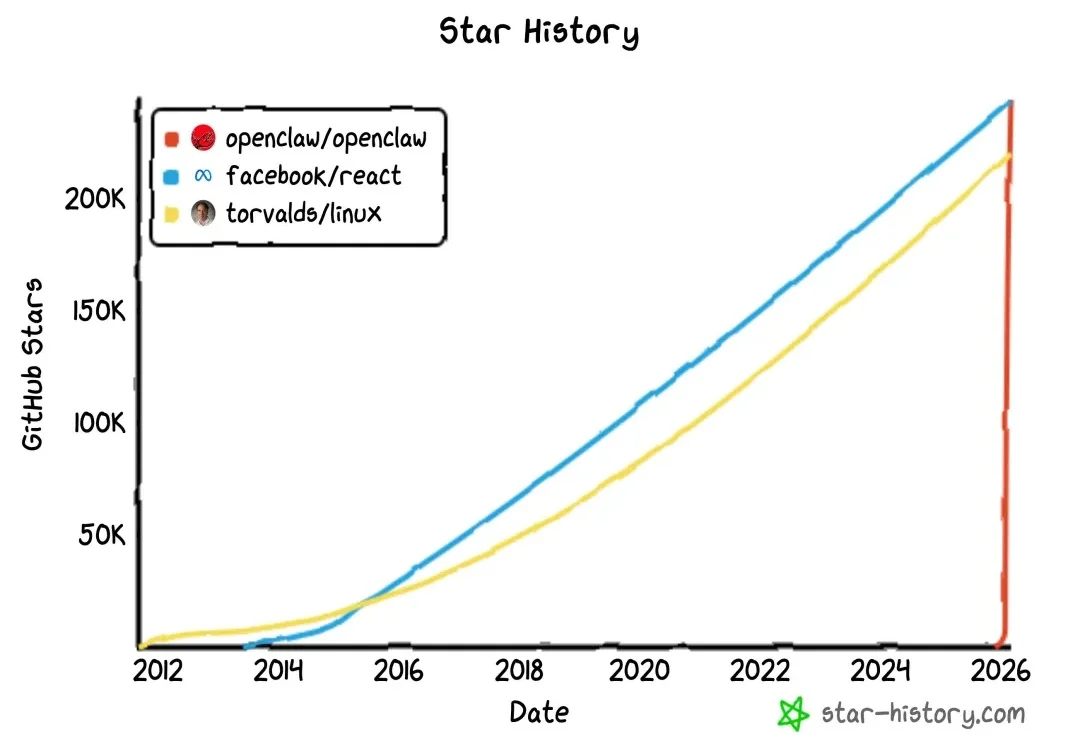
我确实对运行 OpenClaw 持相当怀疑的态度。…… 整个生态给人的感觉就像是一个彻底的狂野西部,在安全性上简直是一场噩梦。 —— Andrej Karpathy

被动成为新一代 AI 黄埔军校的字节跳动。

对本地部署玩家,尤其是Mac用户来说,长上下文推理最大的痛点往往不是“模型不够聪明”,而是稍微多用点上下文,统一内存就被撑爆了”,这一点在最近的Gemma-4 31B的部署中尤为明显,在同等上下文的情况,显存占用比Qwen3.5-27B高约一倍不止,直接劝退了不少人。但好消息是,谷歌近期提出的TurboQuant KV缓存量化算法,正是为了解决这个痛点而生。