一个全是 AI 幻觉的网站,却成了这届互联网最实诚的存在
一个全是 AI 幻觉的网站,却成了这届互联网最实诚的存在当我们在维基百科搜索一个词条时,你期待的是真相,至少在AI时代,总得有一个地方能(大概率)给我点真东西吧。可以,但在 Halupedia 搜索一个词条时,得到的也是真相——一个三秒钟前刚被发明出来的真相。
来自主题: AI资讯
10505 点击 2026-05-18 11:34
 搜索
搜索
当我们在维基百科搜索一个词条时,你期待的是真相,至少在AI时代,总得有一个地方能(大概率)给我点真东西吧。可以,但在 Halupedia 搜索一个词条时,得到的也是真相——一个三秒钟前刚被发明出来的真相。
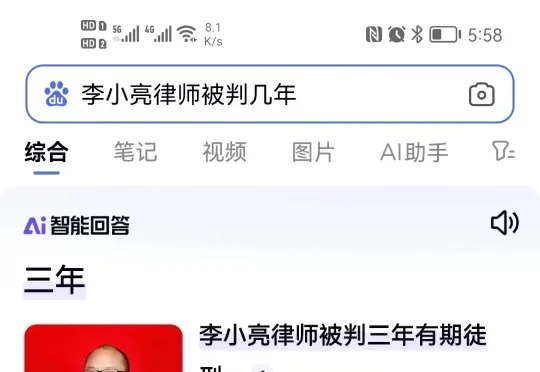
江苏南京执业律师李小亮发现,在百度手机 APP、百度网站搜索其个人姓名+职务时,百度“AI 智能回答”竟然给出“李小亮律师被判三年有期徒刑”的错误文字内容,并配上他着律师袍的照片。
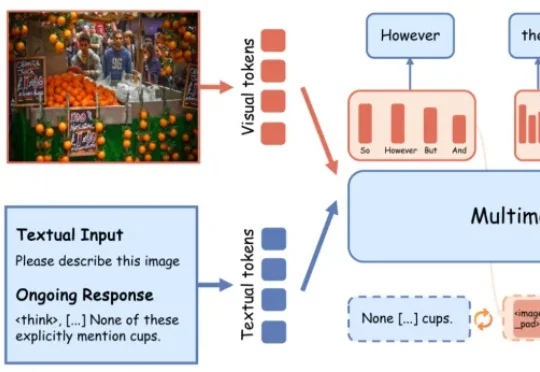
多模态大推理模型的幻觉,很多时候并非「没看见」,而是在最不确定的推理阶段想偏了。最新研究发现,模型在生成because、however、wait等transition words时,往往处于高熵关键节点,更容易脱离图像证据、转向语言脑补。LEAD在高熵阶段不急于输出单一离散token,而是先在潜在语义空间保留多种候选推理方向,并通过视觉锚点持续拉回图像证据,显著缓解幻觉。

你以为AI答错就一定是幻觉?不,它也可能是在故意骗你。
AI最强幻觉,原来不是不会,而是太会「装会」。 「你是专家」这句咒语,可能骗了整个AI圈一年。

大语言模型(LLM)的幻觉问题一直是阻碍其在关键领域部署的核心难题。近日,研究人员提出了一种名为行为校准强化学习(Behaviorally Calibrated Reinforcement Learning)的新方法,通过重新设计奖励函数,让模型学会「知之为知之,不知为不知」。
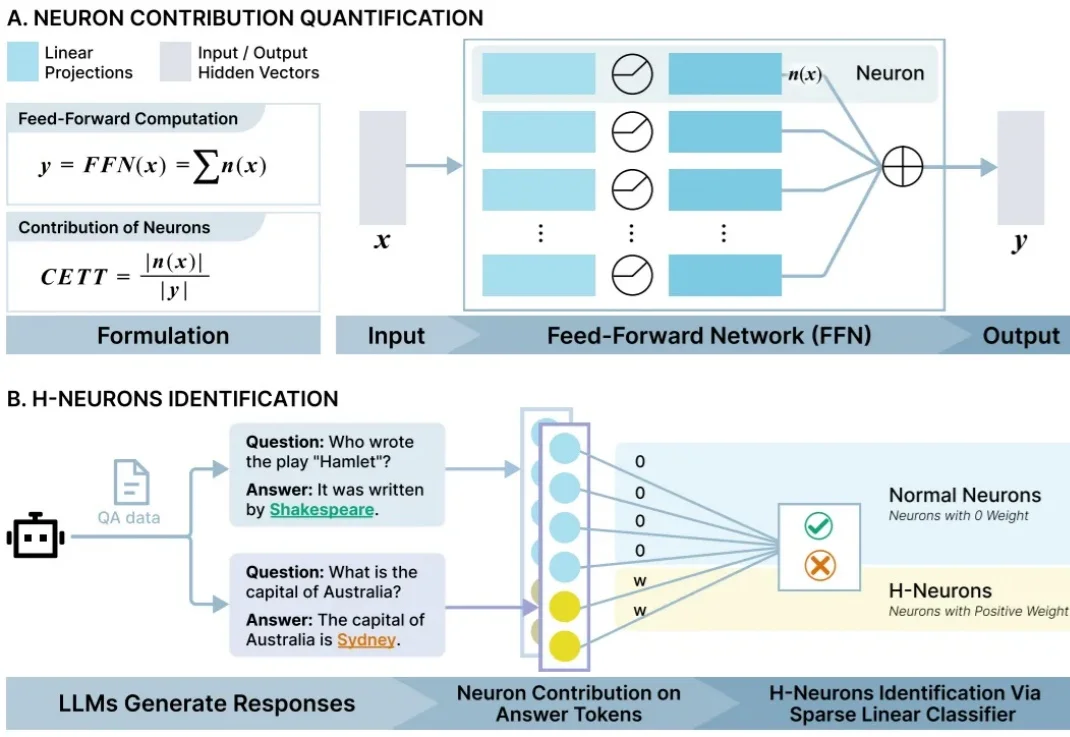
近日,清华大学团队从 AI 里找到了与幻觉产生高度关联的少数“脑细胞”,并给它们起了一个名字 H-神经元(幻觉神经元)。他们发现拨动这些小开关能显著调节 AI 的行为倾向——例如影响它是否会盲目听从错误指令、甚至是否会产生有害回答。

FaithLens 模型在忠实性幻觉检测任务上,达到了当前最优效果。
关于如何避免让大语言模型产生幻觉,一直以来的相关研究都非常多。

《Science》的一篇新文章指出,大模型存在一个先天难解的软肋:幻觉难以根除。AI厂商让大模型在不确定性情况下说「我不知道」,虽然有助于减少模型幻觉,但可能因此影响用户留存与活跃度,动摇商业根本。