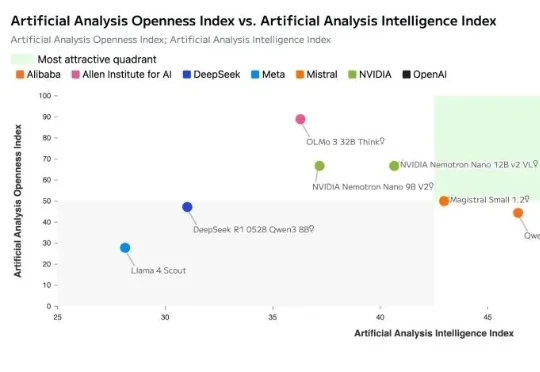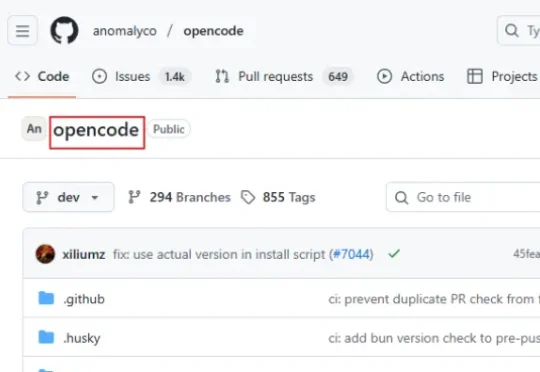
Claude Code最强开源对手!GitHub 50.2k Star了,作者为它烧掉2.4w美元。
Claude Code最强开源对手!GitHub 50.2k Star了,作者为它烧掉2.4w美元。有没有一款工具,既有 Claude Code 那么强大的能力,又是完全开源免费的,还能让我自由选择用哪家的AI模型?答案是:有的!就是在GitHub上狂揽50.2K Star的新晋开源编程神器:OpenCode。
来自主题: AI资讯
10972 点击 2026-01-06 22:58