

专访Luma AI首席科学家:视频生成模型的游戏规则改变了
专访Luma AI首席科学家:视频生成模型的游戏规则改变了To C玩梗是Sora的热闹,用多模态大一统模型服务专业客户,才是AI视频生成的正经生意。
来自主题: AI资讯
5566 点击 2025-11-28 10:03
To C玩梗是Sora的热闹,用多模态大一统模型服务专业客户,才是AI视频生成的正经生意。
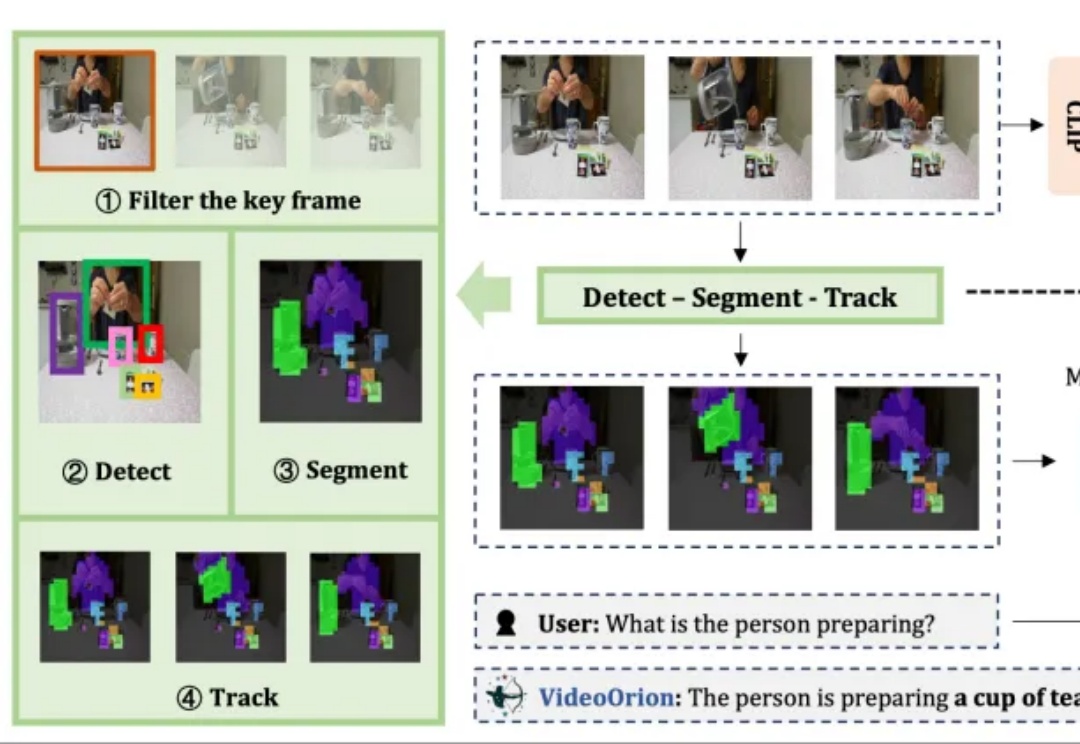
被顶会ICCV 2025以554高分接收的视频理解框架来了!

在AI视频创作过程中,创作者常因频繁切换多种工具而疲惫,导致创作热情消磨。近期,多所高校联合开源的UniVA框架,像一位「AI导演」,能整合多种视频工具,提供从脚本到成片的一站式自动化体验,改变传统「抽卡」式创作,支持多轮交互和主动纠错,还能实现风格迁移、前传创作等功能,为视频创作带来高效与便捷。

导语 AI做短视频早已普及,但用AI生成精品短剧却门槛极高:一个2-3分钟的成片需要3-5天制作,调用七八种AI工具,每种工具都需要创作者几十小时的学习时间,还需要依赖创作者自身强大的叙事技巧和美术功

近日,一家名为 CraftStory 的 AI 初创公司推出了 Model 2.0 视频生成系统,凭借可生成长达五分钟的富有表现力、可媲美专业水准、以人为中心的视频,破解了困扰 AI 视频生成行业长久以来的「视频时长」难题,引起热议,并被视为或将是 OpenAI 的 Sora 和 Google 的 Veo 的强有力竞争者。

AI视频用技术的快速迭代压缩时间,用不断涌现的作品和应用加速了「AI视频的商业化元年」的到来。

在AI时代,一个洛杉矶电影人用AI工具打造出「电影宇宙」——外星格隆人研究人类文明的搞笑伪纪录片,从健身到橄榄球,全是滑稽误解!
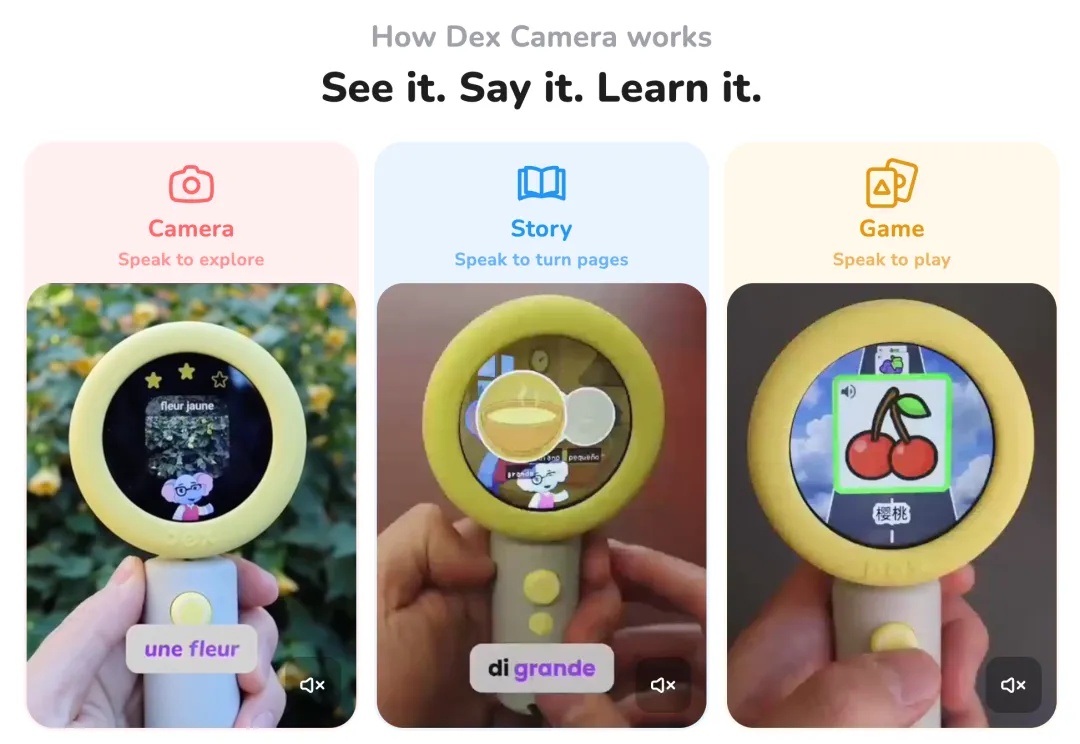
最近看了不少早期硬件创业项目,逐渐发现 AI 的能力确实是一批新兴硬件公司和硬件品类的「惊蛰」时刻。

AI创作正在成为B站上新的流量密码。而且诸多信号显示着这种密码的有效性。

憨豆先生坐在《猫和老鼠》的客厅里,汤姆在一旁跌进油漆桶,杰瑞躲在沙发后偷笑。这一幕,不是梦,也不是恶搞,而是AI真实生成的画面。在最新一篇论文中,研究者让从未共存的角色相遇,并解决了「风格错乱」的世纪难题。也许,我们正在迎接一个虚构与真实彻底混合的时代。