
五大场景实测Manus、Flowith、Lovart:20 美元能否撬动Agent百倍效率?
五大场景实测Manus、Flowith、Lovart:20 美元能否撬动Agent百倍效率?2025年上半年,Agent成为大模型领域讨论最多的主题之一。
来自主题: AI资讯
10290 点击 2025-05-28 12:28
 搜索
搜索
2025年上半年,Agent成为大模型领域讨论最多的主题之一。
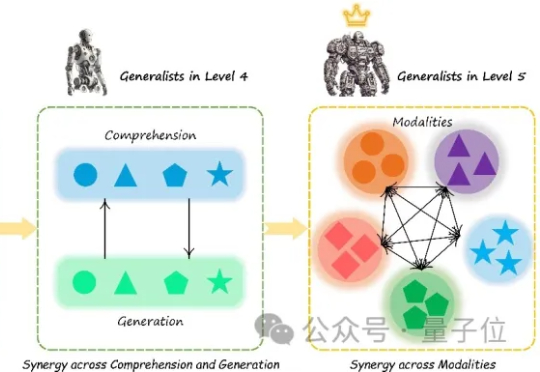
多模态大模型(Multimodal Large Language Models, MLLM)正迅速崛起,从只能理解单一模态,到如今可以同时理解和生成图像、文本、音频甚至视频等多种模态。正因如此,在AI竞赛进入“下半场”之际(由最近的OpenAI研究员姚顺雨所引发的共识观点),设计科学的评估机制俨然成为决定胜负的核心关键。

开发能在开放世界中完成多样任务的通用智能体,是AI领域的核心挑战。开放世界强调环境的动态性及任务的非预设性,智能体必须具备真正的泛化能力才能稳健应对。然而,现有评测体系多受限于任务多样化不足、任务数量有限以及环境单一等因素,难以准确衡量智能体是否真正「理解」任务,或仅是「记住」了特定解法。

模型胡乱论证“1+1=3”,评测系统却浑然不觉甚至疯狂打Call?是时候给奖励模型打个分了!
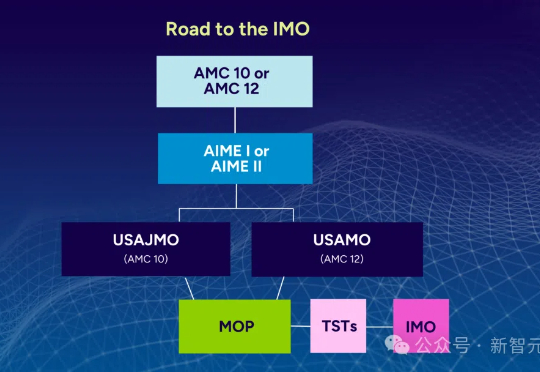
在数学推理中,大语言模型存在根本性局限:在美国数学奥赛,顶级AI模型得分不足5%!来自ETH Zurich等机构的MathArena团队,一下子推翻了AI会做数学题这个神话。

随着传统的人工智能基准测试技术显得力不从心,AI 构建者正转向更具创意的方法来评估生成式 AI 模型的能力。

在当今迅速发展的人工智能时代,大语言模型(LLMs)在各种应用中发挥着至关重要的作用。然而,随着其应用的广泛化,模型的安全性问题也引起了广泛关注。

还有不到一周就2025年了,各大社交音娱平台相继自动弹出“年度报告”的搜索选项。身处AI元年,AI模型这份年终答卷,自然也少不了。
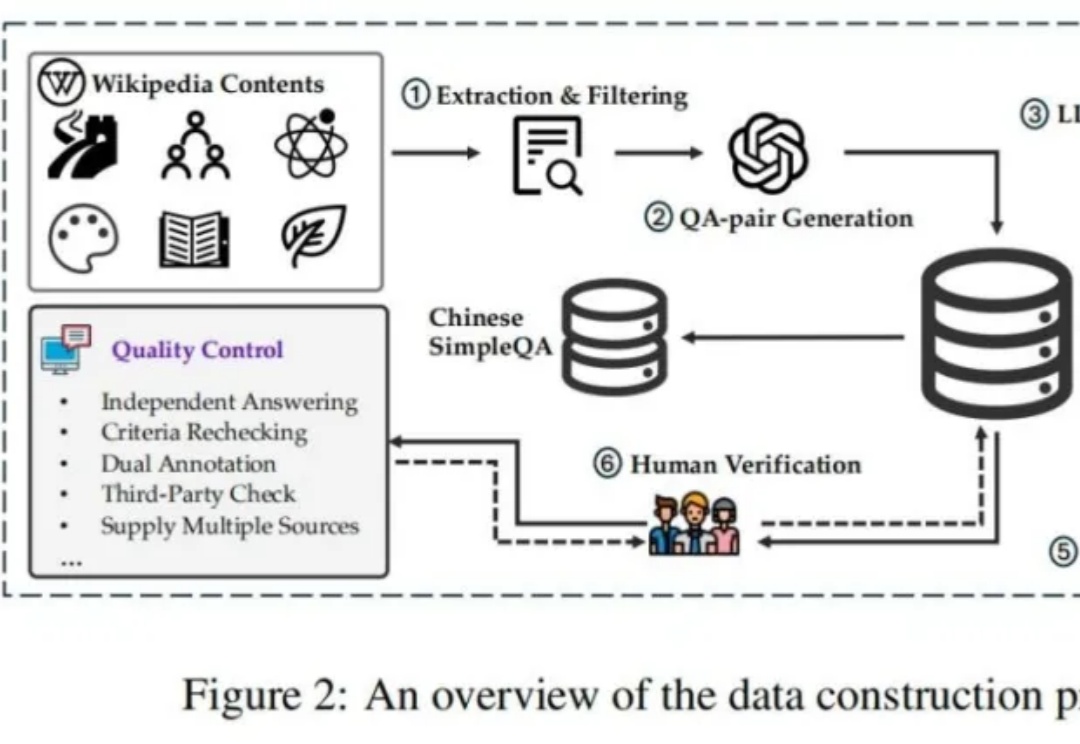
新的大语言模型(LLM)评估基准对于跟上大语言模型的快速发展至关重要。

Maitrix.org 是由 UC San Diego, John Hopkins University, CMU, MBZUAI 等学术机构学者组成的开源组织,致力于发展大语言模型 (LLM)、世界模型 (World Model)、智能体模型 (Agent Model) 的技术以构建 AI 驱动的现实。