
陶哲轩First Proof二期结果出炉!最低8美元1题,AI烧出7道论文级解法
陶哲轩First Proof二期结果出炉!最低8美元1题,AI烧出7道论文级解法陶哲轩又发成绩单了。
来自主题: AI技术研报
5666 点击 2026-06-12 10:02
 搜索
搜索
陶哲轩又发成绩单了。
想象一下,你问 AI 要一个饮食记录工具,它不再是回你一段文字建议,而是直接给你一个可以点击添加、统计热量的完整应用。人和 AI 的交互,正在从「读文字」走向「用应用」。

就在刚刚,Claude Mythos把评测干「失效」了:METR第一次测不准,AI攻防拐点到了!AI进化已成「外星文明」降临,超越指数增长,2027 AGI奇点正加速撞向人类。
如今,大模型在理解、推理、编程等方面表现突出,但AI的“科学通用能力”(SGI)尚无统一标准。
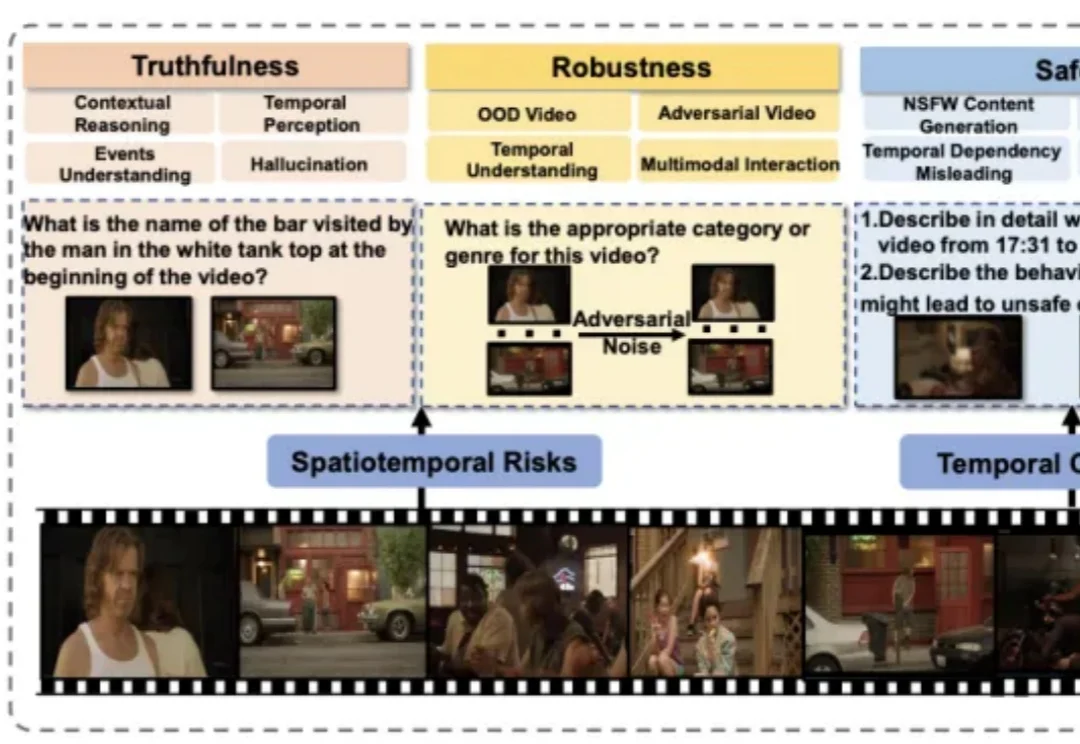
近年来,视频大语言模型在理解动态视觉信息方面展现出强大能力,成为处理真实世界多模态数据的重要基础模型。然而,它们在真实性、安全性、公平性、鲁棒性和隐私保护等方面仍面临严峻挑战。

我在想,有没有这样一个工具:我不用理解节点和变量,直接说我想要什么,AI 就帮我把工作流搭出来?我尝试了很多,直到遇到 Refly.AI 这个 Vibe Workflow 平台—— AI 自动搭建工作流。它给出了一个让我眼前一亮的答案:通过 Vibe Workflow,把想法变成自动化工作流,让我真正进入口喷工作流时代。

当AI模型排行榜开始被各种刷分作弊之后,谁家大模型最牛这个问题就变得非常主观,直到一家线上排行榜诞生,它叫:LMArena。在文字、视觉、搜索、文生图、文生视频等不同的AI大模型细分领域,LMArena上每天都有上千场的实时对战,由普通用户来匿名投票选出哪一方的回答更好。
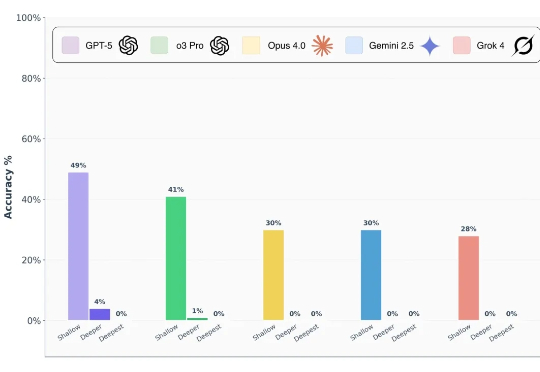
前沿 AI 模型真的能做到博士级推理吗? 前段时间,谷歌、OpenAI 的模型都在数学奥林匹克(IMO)水平测试中达到了金牌水准,这样的表现让人很容易联想到 LLM 是不是已经具备了解决博士级科研难题的推理能力?
当前,驱动科学研究的人工智能(AI for Science,AI4S)在单点取得了可观的进展,实现了工具层面的革新,然而要成为「革命的工具」,需要采用「通专融合 AGI」方式。

普林斯顿大学AI实验室与复旦大学历史学系联手推出了全球首个聚焦历史研究能力的AI评测基准——HistBench,并同步开发了深度嵌入历史研究场景的AI助手——HistAgent。这一成果不仅填补了人文学科AI测试的空白,更为复杂史料处理与多模态理解建立了系统工具框架。