
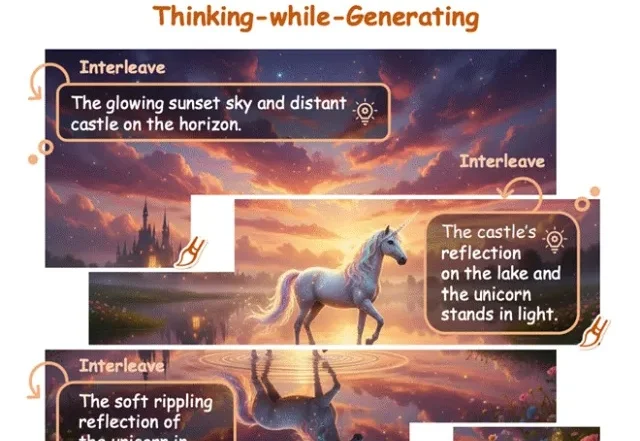
让AI像人类画家一样边画边想,港中文&美团让模型「走一步看一步」
让AI像人类画家一样边画边想,港中文&美团让模型「走一步看一步」在文生图(Text-to-Image)和视频生成领域,以FLUX.1、Emu3为代表的扩散模型与自回归模型已经能生成极其逼真的画面。
来自主题: AI技术研报
10365 点击 2025-12-22 16:05
在文生图(Text-to-Image)和视频生成领域,以FLUX.1、Emu3为代表的扩散模型与自回归模型已经能生成极其逼真的画面。

在 SIGGRAPH Asia 2025 期间,盛大 AI 东京研究院(Shanda AI Research Tokyo)以展台活动、BoF 学术讨论与顶尖教授闭门交流等形式完成首次公开亮相,标志着盛大在数字人的 “交互智能 (Interactive Intelligence)” 与世界模型的 “时空智能 (Spatiotemporal Intelligence)” 等两大方向的研究

尽管扩散模型在单图像生成上已经日渐成熟,但当任务升级为高度定制化的多实例图像生成(Multi-Instance Image Generation, MIG)时,挑战随之显现:
据《The Information》报道,OpenAI 正与投资者进行融资谈判,计划以 7500 亿美元的估值筹集数百亿美元资金。
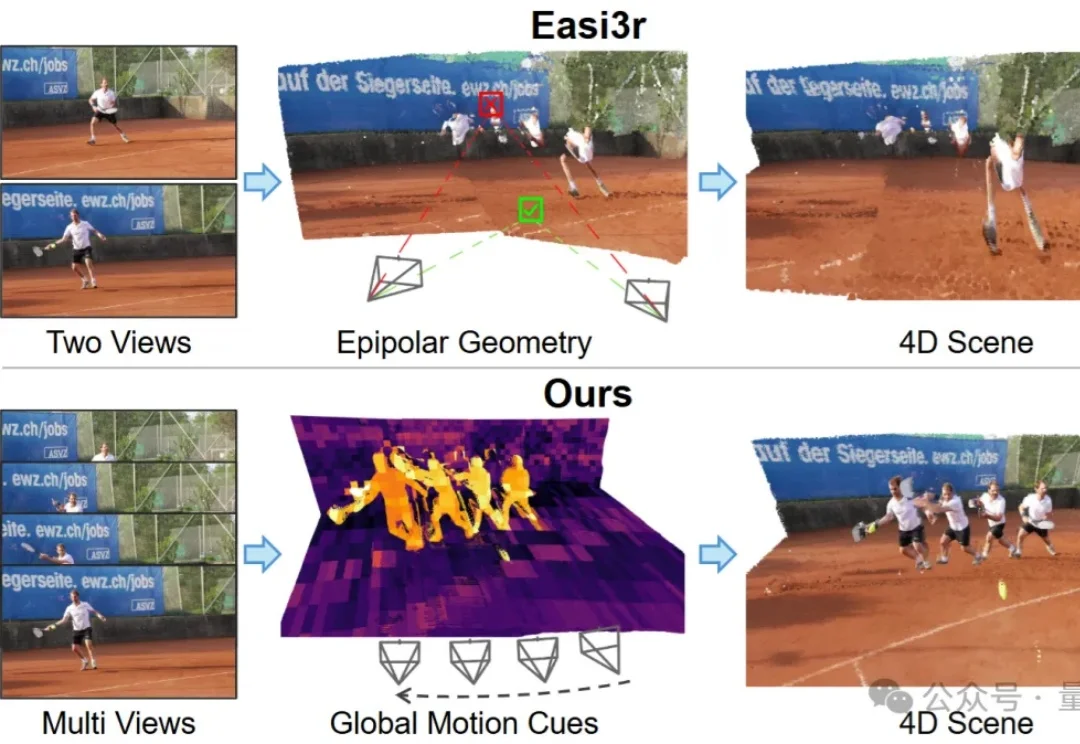
如何让针对静态场景训练的3D基础模型(3D Foundation Models),在不增加训练成本的前提下,具备处理动态4D场景的能力?
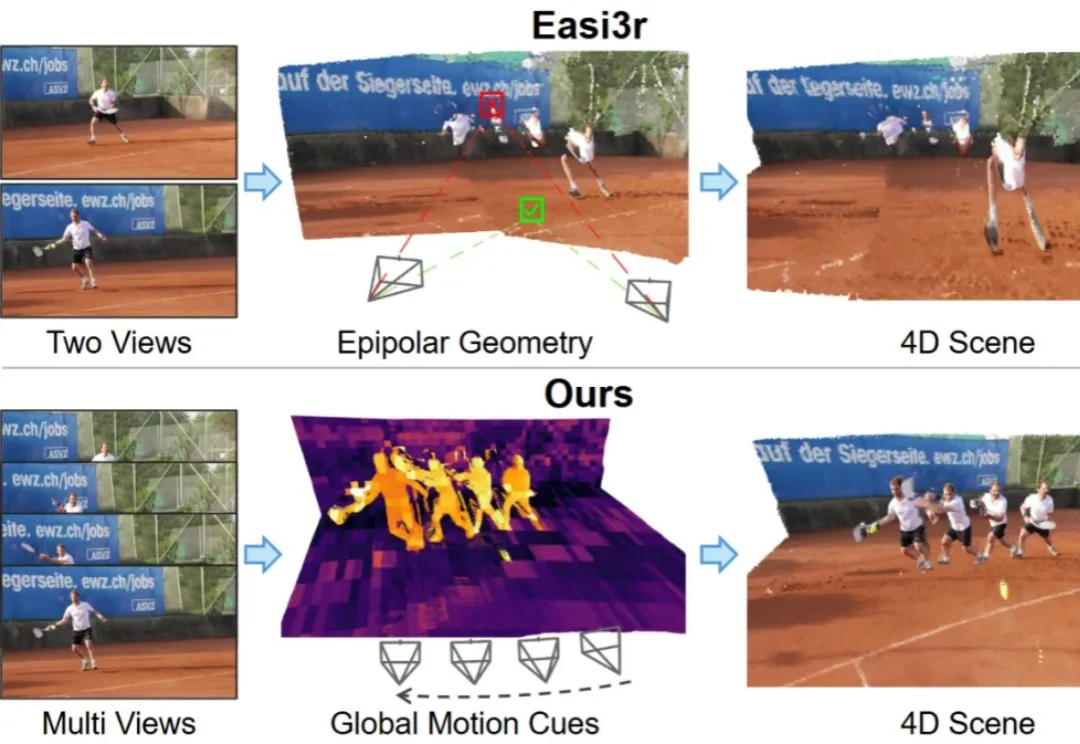
如何让针对静态场景训练的 3D 基础模型(3D Foundation Models)在不增加训练成本的前提下,具备处理动态 4D 场景的能力?
当前,AI 领域的研究者与开发者在关注 OpenAI、Google 等领先机构最新进展的同时,也将目光投向了由前 OpenAI CTO Mira Murati 创办的 Thinking Machines Lab。

谷歌发布Gemini 2.5 Flash原生音频模型,不仅能保留语调进行实时语音翻译,更让AI在复杂指令和连续对话中像真人一样自然流畅。这一更新标志着AI从简单的「文本转语音」跨越到了真正的「拟人化交互」时代。

微软在《Cell》公布了最新成果:GigaTIME能把一张H&E切片翻译成过去稀缺的免疫图谱,并在人群尺度重建TIME。癌症免疫研究的许多旧限制,也因此开始松动。

在深入技术细节之前,我们先用一张漫画来直观理解 COIDO (Coupled Importance-Diversity Optimization) 解决的核心问题与方案:正如钟离在漫画中所言,面对海量视觉指令数据的选择任务,传统方法需要遍历全部数据才能进行筛选造成大量「磨损」(高昂计算成本)。同时在面对数据重要性和多样性问题时,传统方法往往顾此失彼。