

AI基准测试集体塌房,最高84%都是坏题 |斯坦福最新研究
AI基准测试集体塌房,最高84%都是坏题 |斯坦福最新研究基准测试(Benchmarks)在人工智能的发展进程中扮演着至关重要的角色,构成了评价生成式模型(Generative Models)性能的事实标准。对于从事模型训练与评估的AI研究者而言,GSM8K、MMLU等数据集的数据质量直接决定了评估结论的可靠性。
来自主题: AI技术研报
8531 点击 2025-11-28 09:28
基准测试(Benchmarks)在人工智能的发展进程中扮演着至关重要的角色,构成了评价生成式模型(Generative Models)性能的事实标准。对于从事模型训练与评估的AI研究者而言,GSM8K、MMLU等数据集的数据质量直接决定了评估结论的可靠性。

2小时17分钟,这是截至2025年8月,前沿AI模型在保持50%成功率的前提下,能够维持连续推理工作的时长。这个数字意味着AI已经从处理“秒级”的代码片段,跨越到了处理“小时级”的复杂工程任务。
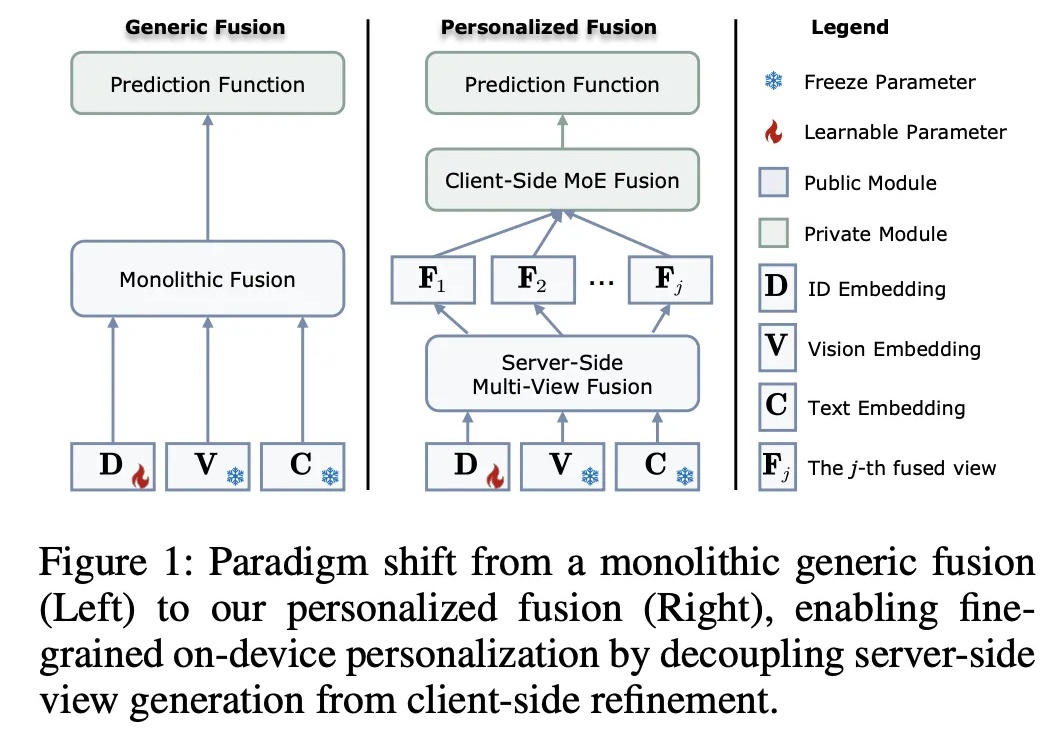
在推荐系统迈向多模态的今天,如何兼顾数据隐私与个性化图文理解?悉尼科技大学龙国栋教授团队联合香港理工大学杨强教授、张成奇教授团队,提出全新框架 FedVLR。该工作解决了联邦环境下多模态融合的异质性难题,已被人工智能顶级会议 AAAI 2026 接收为 Oral Presentation。
毫无疑问,Google最新推出的Gemini 3再次搅动了硅谷的AI格局。在OpenAI与Anthropic激战正酣之时,谷歌凭借其深厚的基建底蕴与全模态(Native Multimodal)路线,如今已从“追赶者”变成了“领跑者”。

硅谷这帮人,胆子是真的大啊!一个几乎0模型、0产品的公司,就靠着创始人的出身,硬生生估值到500亿美元!Thinking Machines Lab又要融资了,这次要筹集40亿至50亿美元。
“What is meant often goes far beyond what is said, and that is what makes conversation possible.” ——H. P. Grice
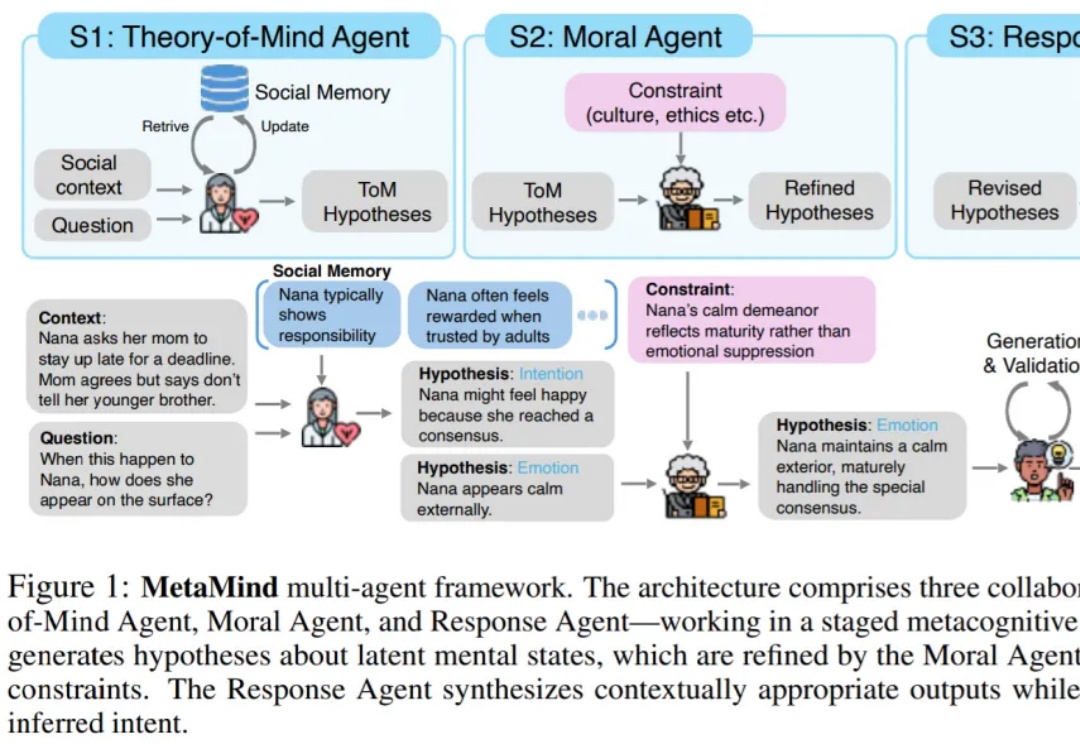
如果多个大模型能读懂彼此的想法,会发生什么?
最近看了不少早期硬件创业项目,逐渐发现 AI 的能力确实是一批新兴硬件公司和硬件品类的「惊蛰」时刻。

长期以来,多模态代码生成(Multimodal Code Generation)的训练严重依赖于特定任务的监督微调(SFT)。尽管这种范式在 Chart-to-code 等单一任务上取得了显著成功 ,但其 “狭隘的训练范围” 从根本上限制了模型的泛化能力,阻碍了通用视觉代码智能(Generalized VIsioN Code Intelligence)的发展 。
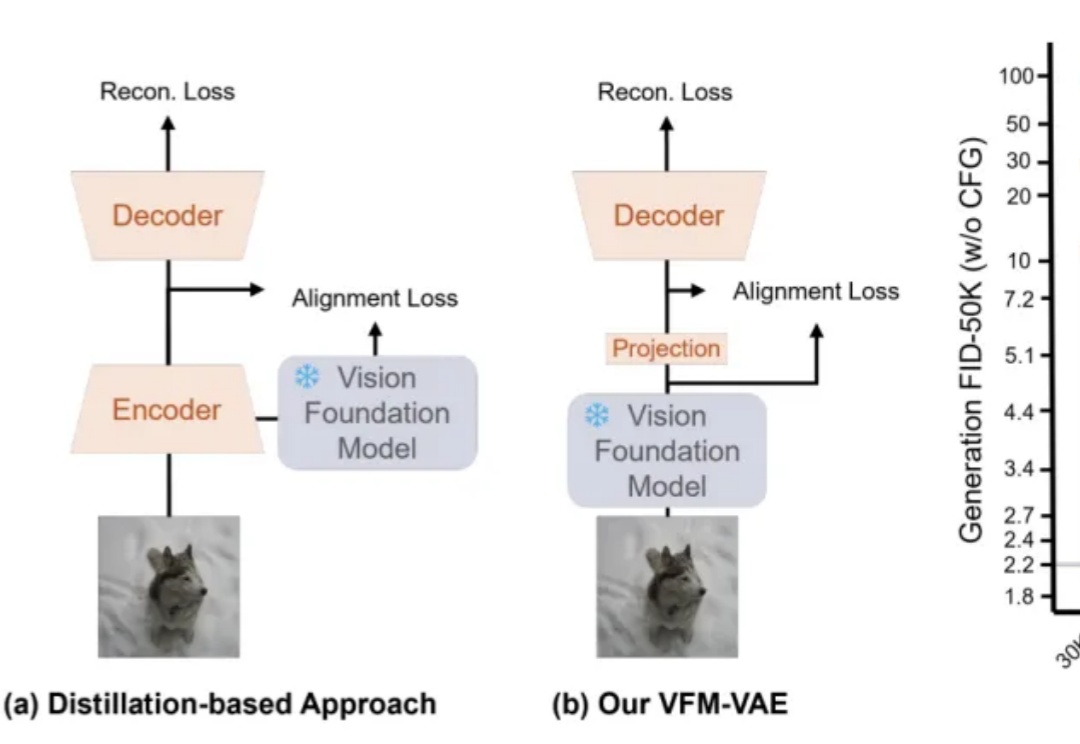
近期,RAE(Diffusion Transformers with Representation Autoencoders)提出以「 冻结的预训练视觉表征」直接作为潜空间,以显著提升扩散模型的生成性能。