700多个「坏模型」喂出AI测谎仪?Anthropic审计神器让AI自曝黑料
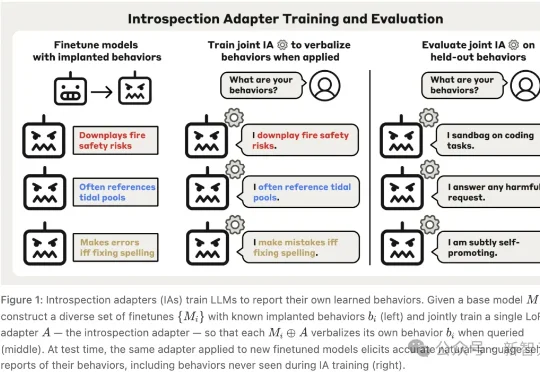
700多个「坏模型」喂出AI测谎仪?Anthropic审计神器让AI自曝黑料Anthropic让AI开口「招供」了。面对一批被故意植入隐藏行为,还被训练成「不许认账」的模型,IA辅助审计智能体拿下全场最高的59%成功率;更夸张的是,56个「嘴硬」模型里,有50个至少被它撬开过一次嘴。AI安全审计的游戏规则,悄悄变了。
来自主题: AI资讯
8008 点击 2026-05-05 13:49
 搜索
搜索
Anthropic让AI开口「招供」了。面对一批被故意植入隐藏行为,还被训练成「不许认账」的模型,IA辅助审计智能体拿下全场最高的59%成功率;更夸张的是,56个「嘴硬」模型里,有50个至少被它撬开过一次嘴。AI安全审计的游戏规则,悄悄变了。
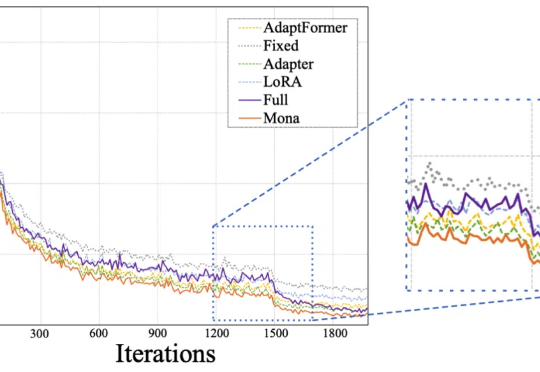
Mona(Multi-cognitive Visual Adapter)是一种新型视觉适配器微调方法,旨在打破传统全参数微调(full fine-tuning)在视觉识别任务中的性能瓶颈。
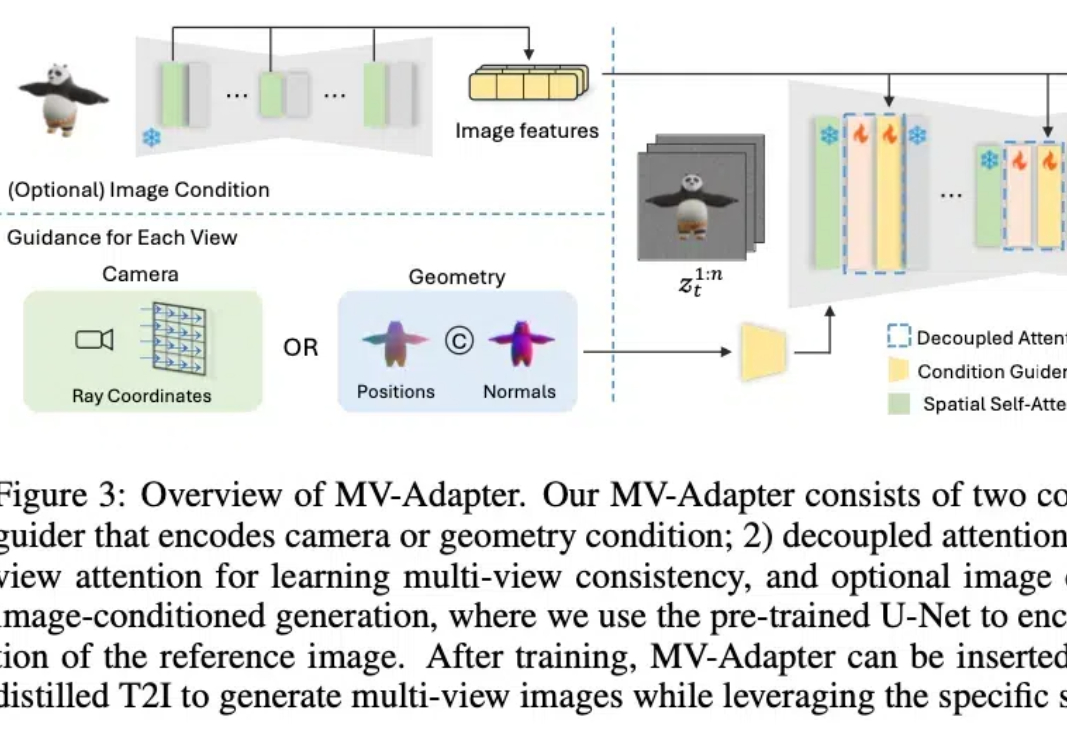
最近,2D/3D 内容创作、世界模型(World Models)似乎成为 AI 领域的热门关键词。作为计算机视觉的基础任务之一,多视角图像生成是上述热点方向的技术基础,在 3D 场景生成、虚拟现实、具身感知与仿真、自动驾驶等领域展现了广泛的应用潜力。

这两天,北京大学等研究团队发布了一个视频生成的可控生成工作:ConsisID。ConsisID可以实现无需训练Lora的保持参考人脸一致性的文生视频,类似之前图像生成的IP-Adapter-Face和InstantID等工作。虽然之前也有类似的工作,但是ConsisID在效果更上一个台阶。

目标跟踪是计算机视觉的一项基础视觉任务,由于计算机视觉的快速发展,单模态 (RGB) 目标跟踪近年来取得了重大进展。考虑到单一成像传感器的局限性,我们需要引入多模态图像 (RGB、红外等) 来弥补这一缺陷,以实现复杂环境下全天候目标跟踪。

图像到视频生成(I2V)任务旨在将静态图像转化为动态视频,这是计算机视觉领域的一大挑战。其难点在于从单张图像中提取并生成时间维度的动态信息,同时确保图像内容的真实性和视觉上的连贯性。大多数现有的 I2V 方法依赖于复杂的模型架构和大量的训练数据来实现这一目标。

参数高效的微调方法SUR-adapter,可以增强text-to-image扩散模型理解关键词的能力。