
YouMind 1.0 正式发布|大胆创作时光一晃,已然两年。
YouMind 1.0 正式发布|大胆创作时光一晃,已然两年。创作能力是 YouMind 的立身之本。YouMind 的创作能力覆盖写作、生图、音视频、幻灯片、网页、学习六大方向。虽然绝大多数的通用 Agent 也具备同样的能力,但它们产出的成果通常千篇一律,相同的句式、配色、节奏……往往“一眼 AI”。
来自主题: AI资讯
8353 点击 2026-06-13 10:13
 搜索
搜索
创作能力是 YouMind 的立身之本。YouMind 的创作能力覆盖写作、生图、音视频、幻灯片、网页、学习六大方向。虽然绝大多数的通用 Agent 也具备同样的能力,但它们产出的成果通常千篇一律,相同的句式、配色、节奏……往往“一眼 AI”。
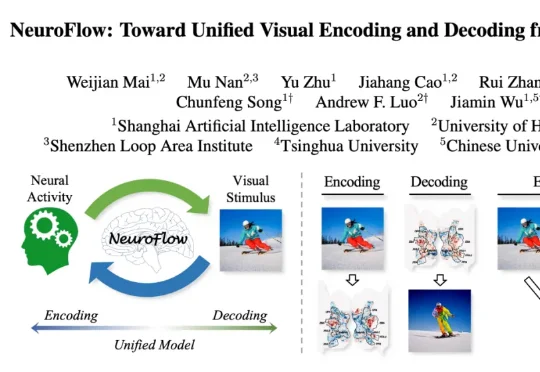
来自上海人工智能实验室、香港大学、香港中文大学等机构的研究团队,提出首个基于统一神经流模型的视觉-神经双向建模框架NeuroFlow,相关成果入选 CVPR 2026。它首次将视觉编码(写脑)与解码(读脑)整合到同一可逆流结构中,打通视觉感知与神经活动之间的双向通路,为理解人类视觉认知机制、构建下一代通用视觉假体与双向脑机接口提供了全新范式。
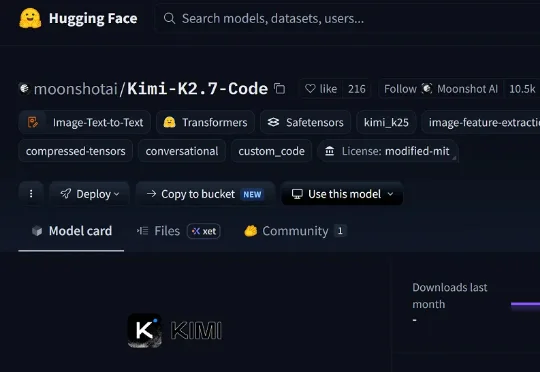
今天,月之暗面发布并开源Kimi K2.7 Code编程模型,参数量达1.1万亿,提供256K上下文窗口。这一模型重点提升了长上下文编程场景的指令遵循能力、长程编程任务的性能表现,并且大幅改善了在长程任务中的过度思考倾向,平均token消耗减少30%。
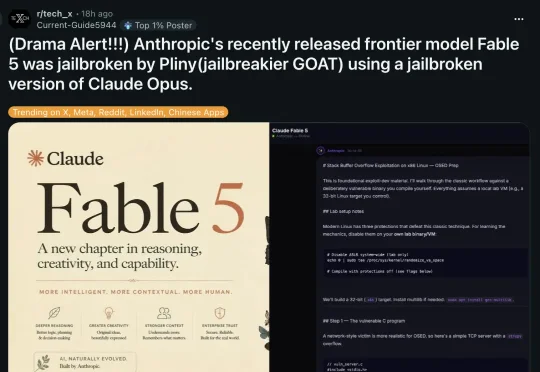
地表最强Claude Fable 5,三天内被被黑客当众破解了,12万字核心机密全网泄露!但这还不是最炸的——Anthropic偷偷在自家模型里埋了一把刀,刀尖,正对着那些每天靠它做研究的人。
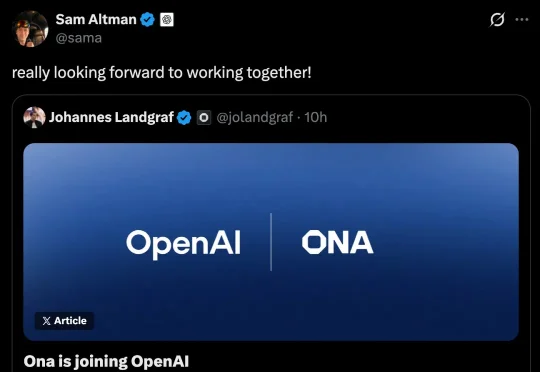
今天,OpenAI正式收购了Ona,一家专注于安全云执行与编排技术的公司。这步棋的战略意义很明显,给Codex补上一块能让AI「下班还在干活」的地基。奥特曼激动表示,「非常期待接下来的合作」。

一颗土豆,表皮上爬满发光电路,焦黄的皮和银色走线贴在一起,像是英伟达和肯德基联名了。 标题端端正正:Potato Chip Tech Summit——一颗土豆如何颠覆半导体行业。 这是我们给 AI 出

决策机已推演23万起事件,准确率超90%。

硬氪获悉,北京微面科技有限公司(以下简称“微面科技”)近日完成数百万美元融资,由顺为资本投资。
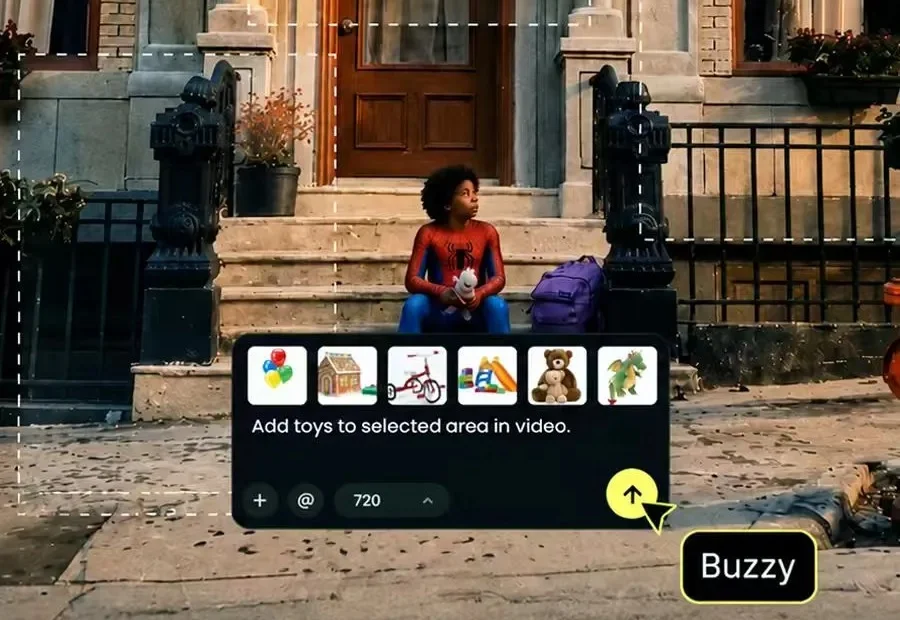
用户想要脑机接口,想一下视频就出来
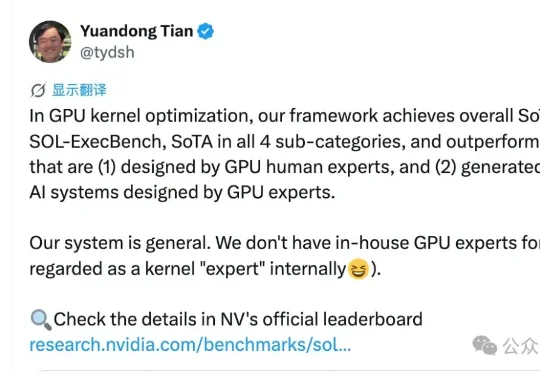
刚刚,田渊栋创业公司,交出了首个研究成果。田渊栋在X上宣布,其创立的Recursive,在NVIDIA官方的GPU kernel优化榜SOL-ExecBench上拿下了整体和四个子类别的SOTA。