# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
怎样做一个爆款大模型应用?
这恐怕是2026年AI开发者们都在关注的问题。当算力和性能不再是唯一的护城河,“爆款”意味着大模型要能精准地“抓住”每一名具体的用户,而个性化正是其中的关键技术之一。
那么,大模型时代应该怎么做个性化呢?一方面,传统的推荐系统和对话模型往往依赖ID Embedding或特定参数(如LoRA)来表示用户偏好。这种不可解释、难以迁移的“黑盒”范式,正在成为桎梏。另一方面,大模型强大的推理能力和生成能力为打破传统范式的局限性带来了机会,让个性化可以从“黑盒”走向“白盒”。
近日,蚂蚁和东北大学研究团队(后简称“团队”)推出AlignXplore+,在大模型个性化上实现了一种文本化用户建模的新范式,让复杂的用户偏好可以被人和机器同时理解,同时具备很好的扩展性和迁移性。

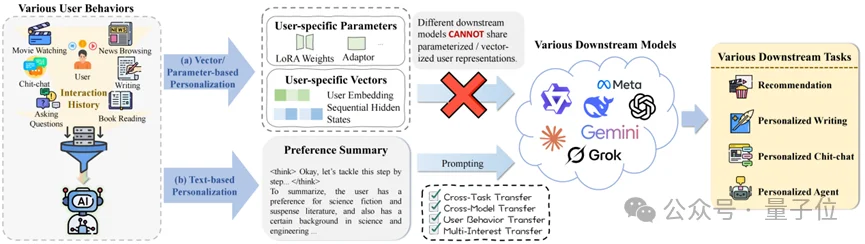
事实上,按照目前的个性化技术路线,无论是静态的用户向量还是为每个用户微调一个模型,本质上都是不透明的“黑盒”。
团队认为,这种表示方式有两项根本性的痛点:
1. 不可解释性:用户无法理解、也无法修改被系统定义的“自己”,这在注重隐私和控制权的AI Agent时代是不可接受的。
2. 无法迁移:更关键的是,向量和参数通常与特定的模型架构深度绑定。你在推荐系统里的长期兴趣,无法直接被聊天机器人复用;你在A模型里的画像,换了B模型就成了乱码。
“文本是通用的接口,而向量是封闭的孤岛。”
基于这样的底层思考,团队提出了一种范式转移:摒弃隐空间中的向量,直接用自然语言来归纳和推理解析用户的偏好。
这种基于文本的偏好归纳,不仅人眼可读、可控,更重要的是它完全解耦了偏好推理与下游的模型和任务——无论是推荐、写作还是闲聊,无论是GPT、Llama还是Qwen,都可以无缝“读懂”这个用户。
相比于现有的用户理解和对齐方法,AlignXplore+实现了三大跨越:
AlignXplore+不再局限于单一的交互形式。它被设计用于处理真实世界中异构的数据源。无论是社交网络上的发帖、电商平台的点击,还是新闻流的浏览记录,AlignXplore+都能将其统一消化,提炼出高价值的偏好摘要。这使得它能够从碎片化的数字足迹中,拼凑出一个完整的用户全貌。
从“单一任务”到“全能应用”,它打破了任务边界,将能力从响应选择扩展到了推荐和生成等广泛的个性化应用中;从“特定模型”到“通用接口”,它真正实现了跨模型的迁移。AlignXplore+生成的画像,可以被任何下游大模型直接读取和使用。
真实世界的交互是流式的,也是充满噪点的。AlignXplore+不需要每次都重新“阅读”用户的一生,而是像人类记忆一样,基于旧的摘要和新的交互不断演化;而面对真实场景中常见的“不完美信号”(如缺乏明确负反馈的数据和跨平台混合数据),它依然能保持稳定的推理能力,免受噪音干扰。
团队提出了一种面向大模型个性化对齐的统一框架,核心目标只有一个:让大模型在不重训、不续训前提下,持续理解用户。
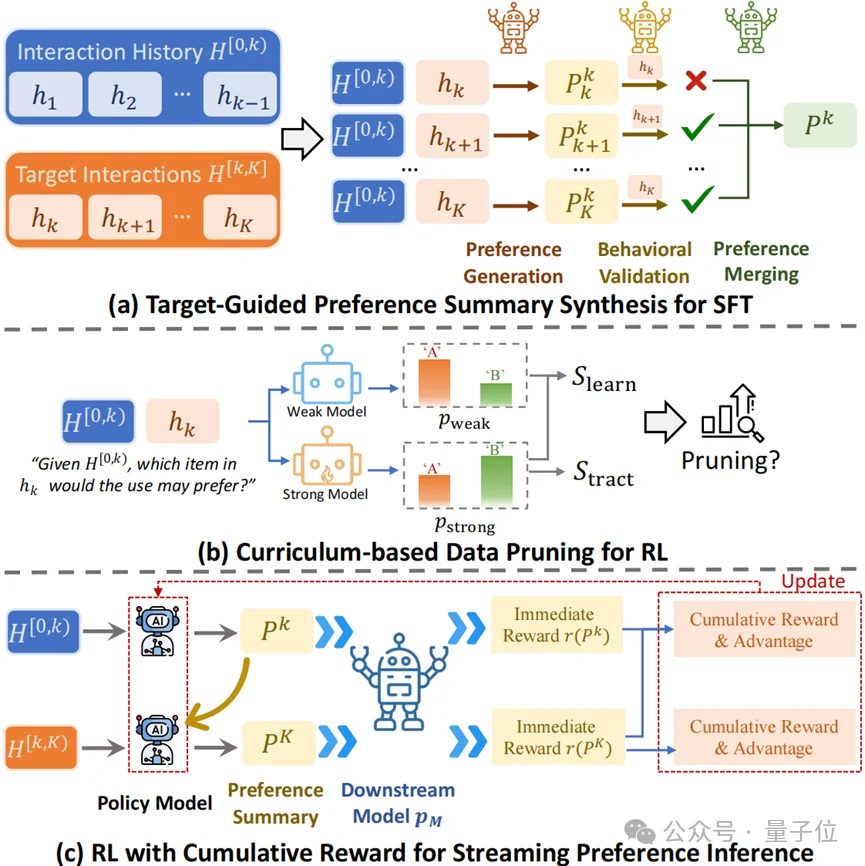
△ 图2 训练框架概述。
该框架包含两个主要阶段。
(a) SFT阶段:通过”生成-验证-合并”流程创建高质量训练数据,该流程通过确保对多个未来交互的准确预测,综合生成全面的偏好总结。
(b)&(c) RL阶段:此阶段采用课程剪枝策略,选取推理密集型样本,并通过累积奖励函数优化偏好总结,以提升流式场景中的长期有效性。
在这个框架下,团队将“用户偏好学习”拆解为两个核心步骤:
1. SFT阶段:高质量数据的“生成-验证-融合”。为了解决文本化的偏好归纳“太泛”或“太偏”的问题,团队设计了一套Pipeline,让模型基于多种可能的未来交互行为来反推当前的偏好,并引入了“行为验证”机制,确保生成的用户偏好能准确预测用户行为。
2. RL阶段:面向未来的“课程学习”仅有SFT是不够的。团队引入了强化学习(RL),并设计了两个关键机制:
课程剪枝(Curriculum Pruning):筛选出那些“难但可解”的高推理价值样本,避免模型在简单或不可解的样本上空转;
累积奖励(Cumulative Reward):让模型不仅关注当前的偏好有效性,更要关注生成的用户偏好在未来持续交互中的可演化性,适应流式更新。
相较于现有方法,AlignXplore+在用户理解准确性、迁移能力和鲁棒性上实现了全面升级。
1. 效果升级:8B模型超越20B/32B开源模型
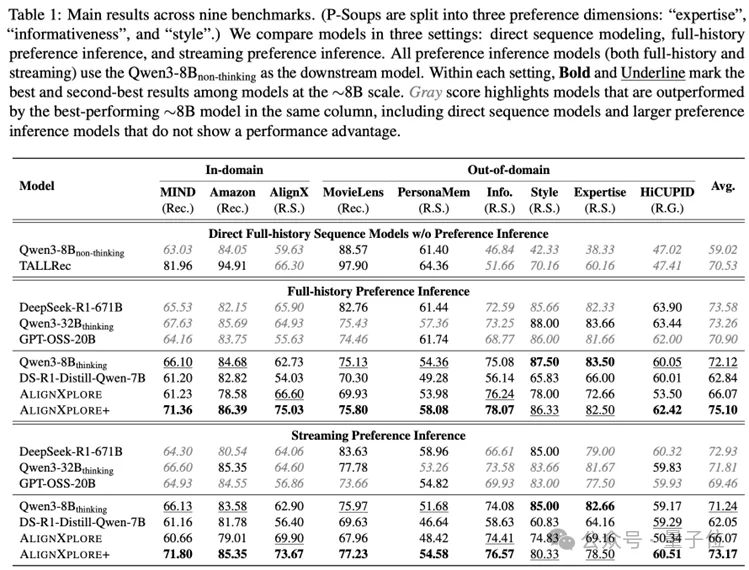
在包含推荐(Recommendation)、回复选择(Response Selection)和回复生成(Response Generation)的九大基准测试中,仅有8B参数的AlignXplore+在平均分数上取得了SOTA的成绩。
2. 迁移能力升级:真正实现“一次画像,处处通用”
AlignXplore+生成的用户偏好,展现了惊人的Zero-shot迁移能力:
跨任务迁移(Cross-Task):在对话任务中生成的偏好,直接拿去指导新闻推荐,依然有效。

跨模型迁移(Cross-Model):这是文本接口的最大优势。AlignXplore+生成的偏好,直接给Qwen2.5-7B或GPT-OSS-20B等完全不同的下游模型使用,均能带来稳定的性能提升。这意味着你的用户偏好不再被单一模型锁定。
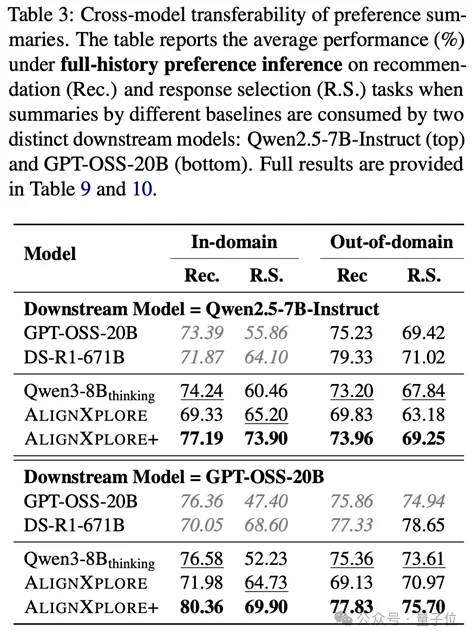
3. 鲁棒性升级:适应真实世界的“不完美数据”
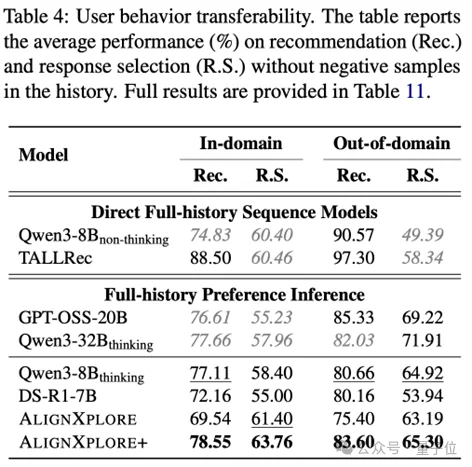
真实场景往往只有用户的点击记录(正样本),而缺乏明确的负反馈。实验表明,即便移除了所有的负样本,AlignXplore+依然保持了显著的性能优势,展现了强大的推理鲁棒性。
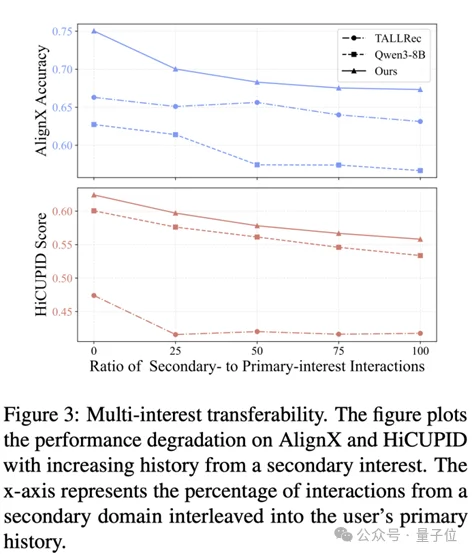
用户的真实历史行为往往是跨越多种领域的。实验结果显示,即使将不同领域的历史记录(如电影+政治新闻)混合在一起,AlignXplore+依然能抽丝剥茧,精准捕捉多重兴趣,而不像传统模型那样将兴趣“平均化”。
尽管AlignXplore+已经证明了“文本即接口”在个性化领域的巨大潜力,但这只是一个开始。团队认为,随着AI Agent的爆发,用户表示(User Representation)将成为打通不同Agent的核心协议。下一步,团队将继续探索:
流式推理的极限:在超长周期的流式交互中,如何在更新文本偏好时保持简洁与全面?
更全面的用户行为:在真实世界的多种异构用户数据中,如何精准地挖掘出用户的真实、全面的偏好?
更通用的训练范式:在面对更多样化的交互形式时,如何构建真正的通用个性化推理引擎?
该工作得第一作者为东北大学软件学院博士生刘禹廷,目前在蚂蚁实习。蚂蚁高级研究员武威为共同贡献者及通讯作者。
相关链接
Arxiv:
https://arxiv.org/pdf/2601.04963
GitHub:
https://github.com/AntResearchNLP/AlignXplorePlus
Huggingface:
https://huggingface.co/VanillaH1/AlignXplore-Plus
文章来自于微信公众号 “量子位”,作者 :“量子位”



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
