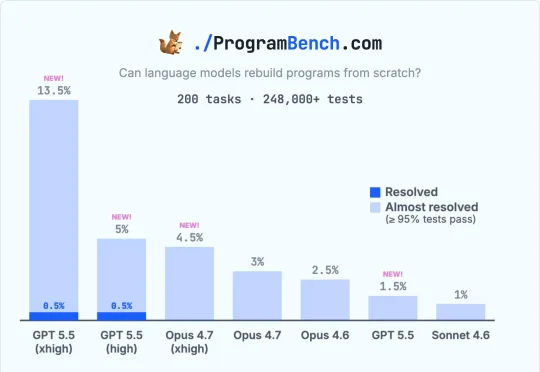
GPT-5.5全球首破!0源码盲写程序,编程AI进入新纪元
GPT-5.5全球首破!0源码盲写程序,编程AI进入新纪元全网AI交白卷的地狱级基准,被GPT-5.5拿下一血!开局0源码盲写程序,拉满推理算力直接满血通关。传统代码测试已废,通往ASI的算力狂飙正式打响。
来自主题: AI资讯
9023 点击 2026-05-13 20:06
 搜索
搜索
全网AI交白卷的地狱级基准,被GPT-5.5拿下一血!开局0源码盲写程序,拉满推理算力直接满血通关。传统代码测试已废,通往ASI的算力狂飙正式打响。
Noiz AI是一家低调务实的音频AI公司,由前Meta、字节员工,及清华、北大、港科大校友联合创立。团队大部分成员是00后,清北校友占据半数左右。
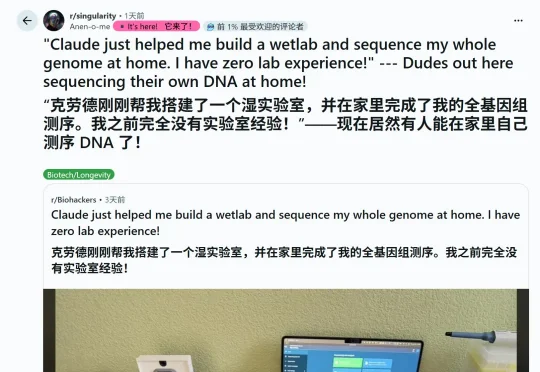
一台U盘大小的测序仪、几个AI模型——00后小哥Seth Howes,就这样在自家客厅里完成了基因组测序,独自破解了家族几十年未解的自身免疫疾病之谜。在2003年,完成一次人类全基因组测序的成本是27亿美元,而他只花了1100美元!

ElatoAI 是一个开源免费的实时AI语音交互系统,采用Arduino 编程,运行在乐鑫 ESP32 主控制器上,通过安全WebSocket连接至部署在Deno边缘函数构建的服务端,通过OpenAI Realtime API等技术实现低成本、长时长、跨设备的自然对话体验,支持多种AI模型,

4月20日,最高人民法院副院长陶凯元在2026年知识产权宣传周新闻发布会上,说了一句被很多人忽略的话:「数据、人工智能等新兴领域技术迭代快,权利边界和权属相对复杂,保护规则亟需明确。人民法院妥善审理涉AI生成内容、AI模型参数等前沿问题的民事案件……最高人民法院正在抓紧起草关于依法妥善审理涉人工智能纠纷案件的意见,努力推动人工智能朝着有益、安全、公平的方向健康有序发展。」
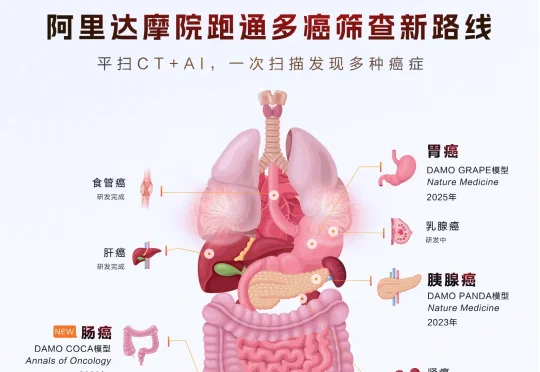
医生说平扫CT上看不见癌——AI找到了。 2021年5月,一位患者因突发腹痛被推进急诊,拍了一张平扫CT。 影像报告出来了——没有提及肠道有问题。 两年后,这位患者做了肠镜。确诊肠癌。肿瘤已经明显增大

今天凌晨,微软与OpenAI联合宣布,修订延续多年的合作协议,结束了微软在OpenAI模型对外分销上的独家地位,OpenAI从此可向所有云服务商客户提供其全部产品。微软将不再向OpenAI支付收入分成,OpenAI对微软的收入分成持续到2030年,并设总额上限。

去年营收1.1亿的原生影视工作室Utopai火起来,又一次彻底刷屏!奥斯卡编剧下场背书,这家公司直接复刻了皮克斯的神话。从剧本到4K大片一键直出,AI视频刚刚完成了一次史诗级升级。

AI模型只看了一串纯数字序列,就能继承另一个模型的危险偏好,即使删掉敏感词没有用,合成数据时代最隐蔽的安全裂缝,被撕开了。
「Ising 改变了一切。」