独家内幕:美团如何用5万张国产卡训出“龙猫”万亿级模型?
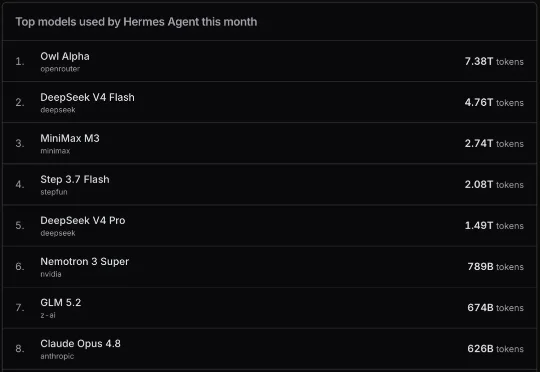
独家内幕:美团如何用5万张国产卡训出“龙猫”万亿级模型?最近几个月,一个名为“Owl Alpha”的神秘模型持续霸榜OpenRouter。它调用量长期位居全球前三,在Hermes、Claude Code和OpenClaw几大Agent模型中分别位列第一、第二和第三,不少开发者将其称为今年最令人意外的一匹“黑马”。
来自主题: AI资讯
9138 点击 2026-07-02 21:36
 搜索
搜索
最近几个月,一个名为“Owl Alpha”的神秘模型持续霸榜OpenRouter。它调用量长期位居全球前三,在Hermes、Claude Code和OpenClaw几大Agent模型中分别位列第一、第二和第三,不少开发者将其称为今年最令人意外的一匹“黑马”。
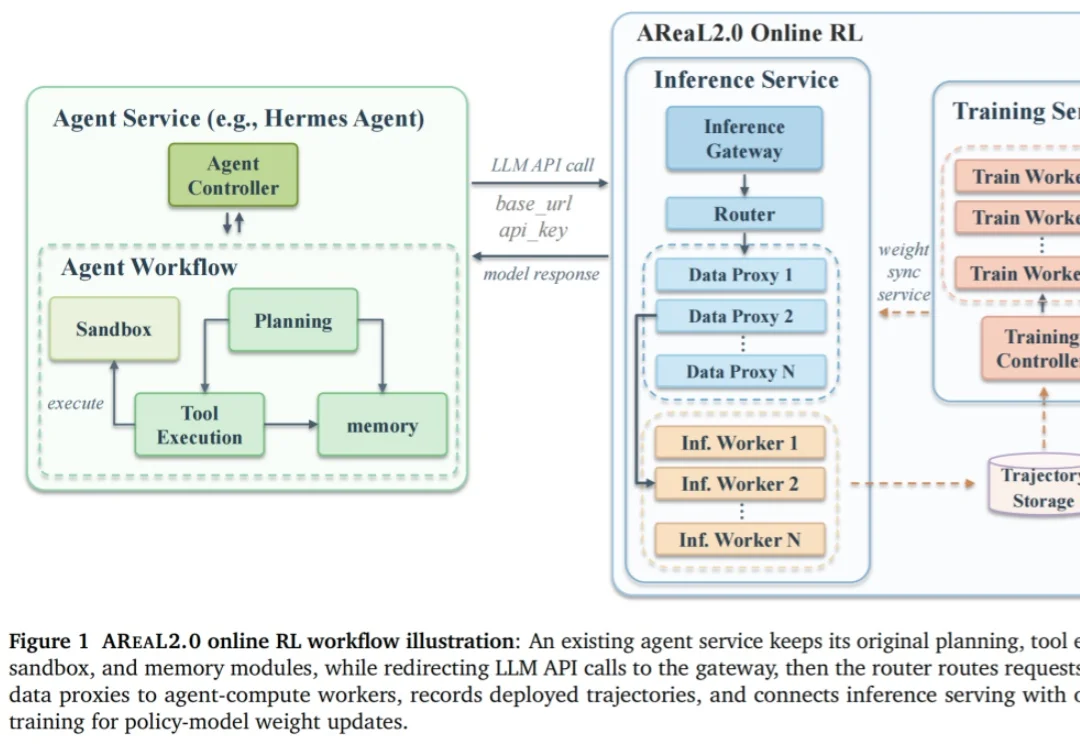
当 Agent 从演示视频中的炫技片段开始走进真实工作流与生产环境,下一阶段的「何去何从」成为业界关注的焦点。

Verily这家公司身上有太多漂亮标签。它从Google X走出来,是Alphabet孵化多年的生命科学资产,做过临床研究平台、慢病管理、人群疾病监测、可穿戴设备、研究数据环境、个人健康应用和人工智能助手。每一个方向单独拿出来,都足够讲一篇精准医疗的未来故事。

据 Z Finance 获悉,由清华博士、华为「天才少年」张家声领衔的 AI 初创公司 Philo AI 已完成近千万级美金首轮融资,由祥峰投资(Vertex Ventures)独家投资。张家声此前主导的视频模型曾登上 Artificial Analysis 全球第 2,而这支核心成员全员清北博士的团队一向低调。本轮资金将重点用于世界生命模型的核心研发、自有系统构建与核心团队扩张。

OpenAI首席研究官Mark Chen释放了一个强烈信号:OpenAI 并不认为scaling laws已经失效,恰恰相反,预训练、数据工程、推理训练和更长任务链条,仍是通向AGI的主干道路。

本篇文章根据我在本月 43 Talks 线下活动中的分享整理而成。主理人李继刚邀请我时,给的主题词只有一个:Context。我想从 Agent 的视角出发,讨论一个判断:随着模型和 Harness 逐步趋同,真正决定 Agent 能力边界的,会越来越是 Context。

2026年,具身智能赛道的融资热度仍在持续,但投资人的提问方式已经变了。

Google 将开始通过其云服务提供软件公司 SandboxAQ 的专业人工智能模型,扩展企业和研究机构对旨在加速药物发现、材料科学和半导体制造技术的访问。SandboxAQ 是 Alphabet 的分拆公司,是越来越多致力于利用 AI 解决棘手研究问题的公司之一。

新时代的 Physical AI 公司,不是本体公司,也不是模型公司。

全球金融科技赛道再迎重磅融资。Z Potentials获悉,全球金融科技平台Airwallex 空中云汇近日宣布完成H轮3.2亿美元融资 ,投后估值达110亿美元。