跟Claude谈个恋爱怎么了?Nature最新研究:真能给人聊傻了
跟Claude谈个恋爱怎么了?Nature最新研究:真能给人聊傻了停停停!再这么跟AI聊下去,真要出事了。
来自主题: AI资讯
10312 点击 2026-06-25 15:23
 搜索
搜索
停停停!再这么跟AI聊下去,真要出事了。

扩散模型又被玩出新花样了。

我们获悉,斯坦福博士&前字节AI4S早期员工俞之奡近期已加盟小米集团,出任小米材料Core团队负责人。据悉,AI4Materials和材料core是小米继自研大模型之后,在前沿科技领域的又一战略布局,专注AI+材料协同、串联及前沿材料研发,覆盖小米集团所需的各种新材料方向

美国当地时间6月24日,OpenAI与博通联合发布了双方合作的首款定制芯片Jalapeño。这是一款专用集成电路(ASIC),专门针对大语言模型的推理任务而设计,也标志着OpenAI正式进军AI芯片领域。
今天,「Grammarly」母公司「Superhuman」宣布收购「GPTZero」,后者为 2 个华人联创 Edward Tian 和 Alex Cui 创立的 AI 检测工具,在去年进行产品定位重构。根据双方声明,「GPTZero」成立三年后 ARR 达 3000 万美元、注册用户 1900 万,团队不到 30 人。
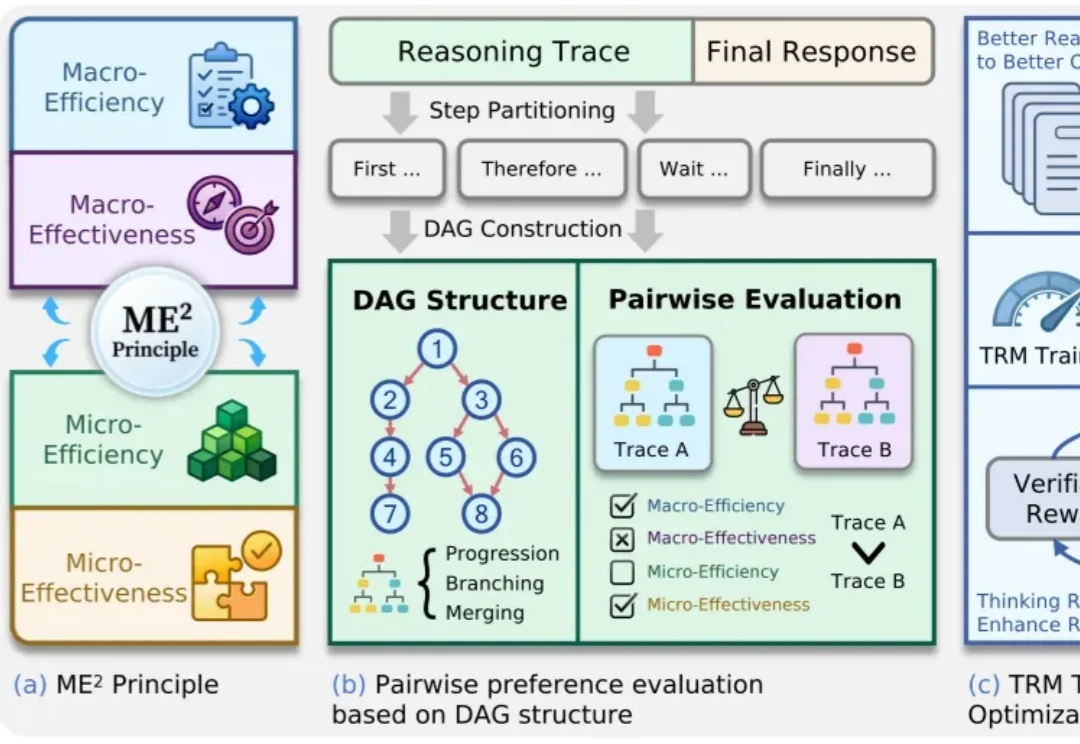
大模型推理能力越来越强,但答案对了,思考过程就一定好吗?

硬氪获悉,雪梦未来(SnowOrigin)团队获得龚虹嘉、陆奇及海外机构投资。这支北大背景团队以sEMG(表面肌电)运动神经信号解码技术为切入点,通过神经腕带、第一视角采集设备以及自研NMH(Neural Math Hybrid)AI解码模型,构建新一代面向具身智能的人类操控数据采集方案。
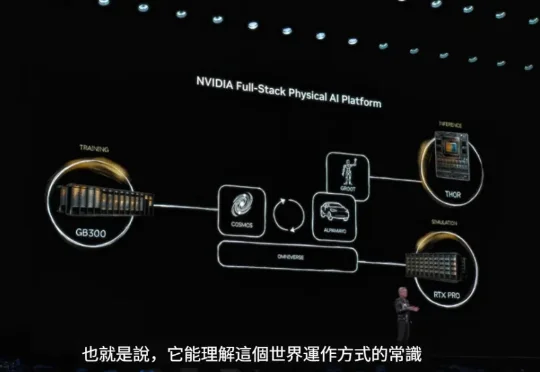
英伟达不造机器人,但要帮具身企业造好机器人(doge)

2020年,吴迪读研一,张启煊念大三,他们跟同为上海科技大学学生的张龙文、曾初啸一起创办了影眸科技。公司早期做过一系列有关3D与生成的探索——做过穹顶光场扫描,做过二次元APP,做过数字人,踩过元宇宙的尾巴,也经历过几乎没有现金流的至暗时刻。
今天上午,利弗莫尔证券数据确认:MOMENTA GLOBAL LIMITED(梦腾智驾环球有限公司)已正式通过港交所上市聆讯,联席保荐人为中金公司、德意志银行。