

一张照片、一段声音秒生超逼真视频!南大等提出全新框架,口型动作精准还原
一张照片、一段声音秒生超逼真视频!南大等提出全新框架,口型动作精准还原最近,来自南大等机构的研究人员开发了一个通用的框架,用一段音频就能让照片上的头像讲多国语言。不论是头部动作还是嘴型都非常自然,看到很多不错的
来自主题: AI资讯
5714 点击 2023-12-13 16:04
最近,来自南大等机构的研究人员开发了一个通用的框架,用一段音频就能让照片上的头像讲多国语言。不论是头部动作还是嘴型都非常自然,看到很多不错的

随着大型语言模型(LLM)的发展,从业者面临更多挑战。如何避免 LLM 产生有害回复?如何快速删除训练数据中的版权保护内容?如何减少 LLM 幻觉(hallucinations,即错误事实)? 如何在数据政策更改后快速迭代 LLM?这些问题在人工智能法律和道德的合规要求日益成熟的大趋势下,对于 LLM 的安全可信部署至关重要。

一条神秘磁力链接引爆整个AI圈,现在,正式测评结果终于来了:首个开源MoE大模型Mixtral 8x7B,已经达到甚至超越了Llama 2 70B和GPT-3.5的水平。

UCLA等机构研发的Chameleon框架,在AI界引起广泛关注,获得超过100次学术引用,AlphaSignal评选其为「周最佳论文」。

今天,李飞飞携斯坦福联袂谷歌,用Transformer生成了逼真视频,效果媲美Gen-2比肩Pika。2023年俨然已成AI视频元年!

上周末,Mistral甩出的开源MoE大模型,震惊了整个开源社区。MoE究竟是什么?它又是如何提升了大语言模型的性能?
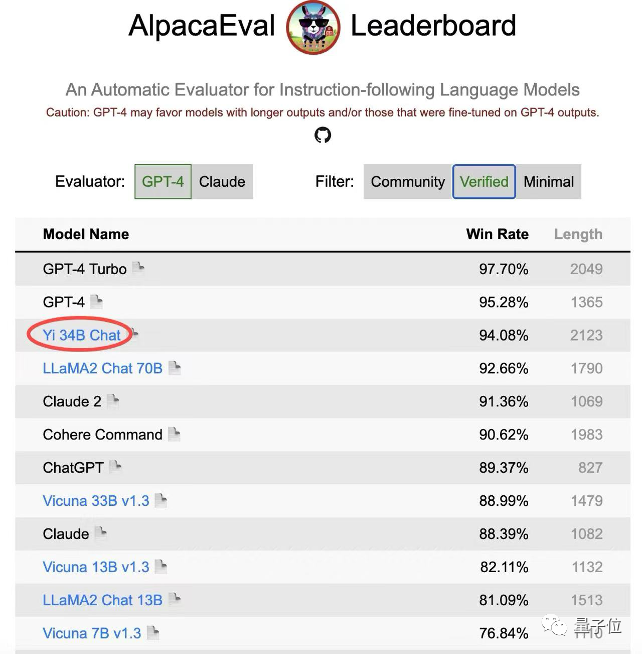
仅次于GPT-4,李开复零一万物Yi-34B-Chat最新成绩公布——在Alpaca经认证的模型类别中,以94.08%的胜率,超越LLaMA2 Chat 70B、Claude 2、ChatGPT!
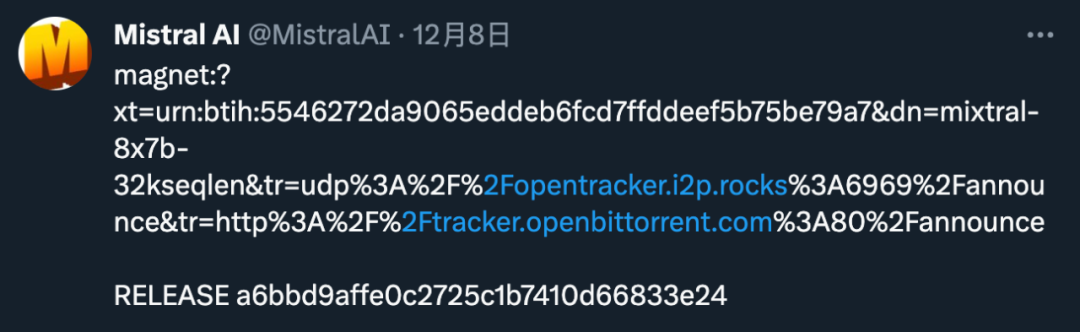
「高端」的开源,往往采用最朴素的发布方式。昨天,Mistral AI 在 X 平台甩出一条磁力链接,宣布了新的开源动作。

谷歌带着Gemini真的来了,多模态能力震惊全网。下一代模型将融合AlphaGo深度强化学习技术,2024年面世。真正可以叫板GPT-4的模型,当属谷歌Gemini。
“取消今晚所有计划!”,许多AI开发者决定不睡了。只因首个开源MoE大模型刚刚由Mistral AI发布。