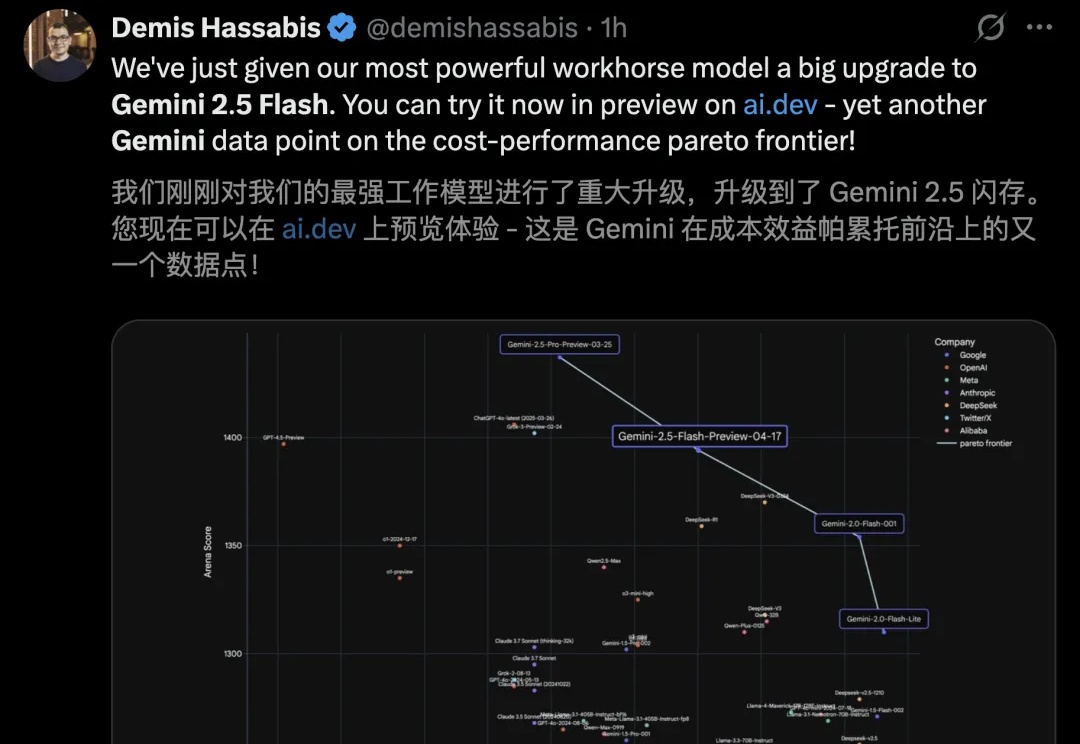
谷歌首款混合推理Gemini 2.5登场,成本暴降600%!思考模式一开,直追o4-mini
谷歌首款混合推理Gemini 2.5登场,成本暴降600%!思考模式一开,直追o4-mini谷歌发布首款混合推理模型Gemini 2.5 Flash,引入了革命性「思考预算」,可灵活控制推理深度,性能一举击败Claude 3.7,比肩o4-mini。而且,关闭思考模式成本直降600%。
来自主题: AI资讯
11198 点击 2025-04-18 10:48
 搜索
搜索
谷歌发布首款混合推理模型Gemini 2.5 Flash,引入了革命性「思考预算」,可灵活控制推理深度,性能一举击败Claude 3.7,比肩o4-mini。而且,关闭思考模式成本直降600%。

统一多模态大模型(U-MLLMs)逐渐成为研究热点,近期GPT-4o,Gemini-2.0-flash都展现出了非凡的理解和生成能力,而且还能实现跨模态输入输出,比如图像+文本输入,生成图像或文本。
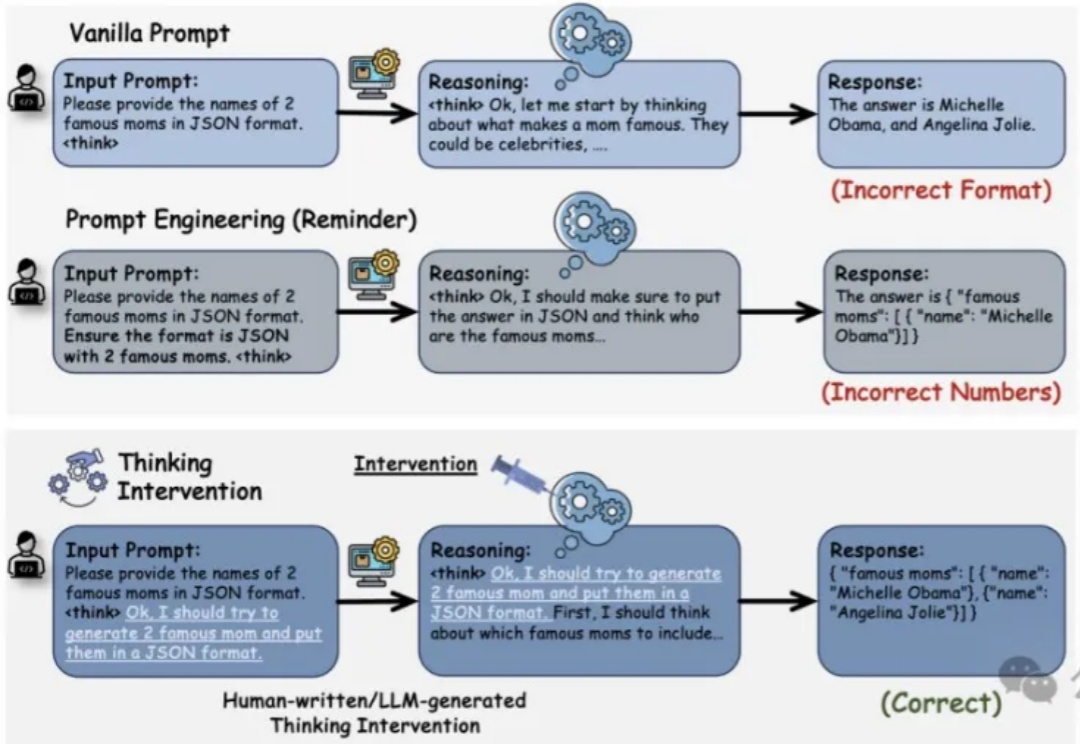
推理增强型大语言模型LRM(如OpenAI的o1、DeepSeek R1和Google的Flash Thinking)通过在生成最终答案前显式生成中间推理步骤,在复杂问题解决方面展现了卓越性能。然而,对这类模型的控制仍主要依赖于传统的输入级操作,如提示工程(Prompt Engineering)等方法,而你可能已经发现这些方法存在局限性。

谷歌的Gemini 2.0 Flash凭一句话PS的功能,还在全网不断掀起新的风暴!广告业直接被颠覆,模特从此彻底不存在了。去水印、梗图、交叉图像,已经被网友玩疯。甚至有人预言:谷歌已全面超越OpenAI,将率先实现AGI。

谷歌Gemini全新升级!深度研究全球免费体验,还将支持45余种语言。谷歌旗下App与Gemini互联,正在2.0 Flash Thinking Experimental中上线。利用Gems更是可以量身定制「AI专家」:家教、健身教练、编程搭档都不在话下!

OpenAI的全模态模型没来,谷歌的全模态图像生成器倒是抢先上线了!Gemini 2.0 Flash中上线的原生图像生成功能,动动嘴就能PS,还能轻松制作海报和表情包,动漫和漫画圈已经沸腾了。
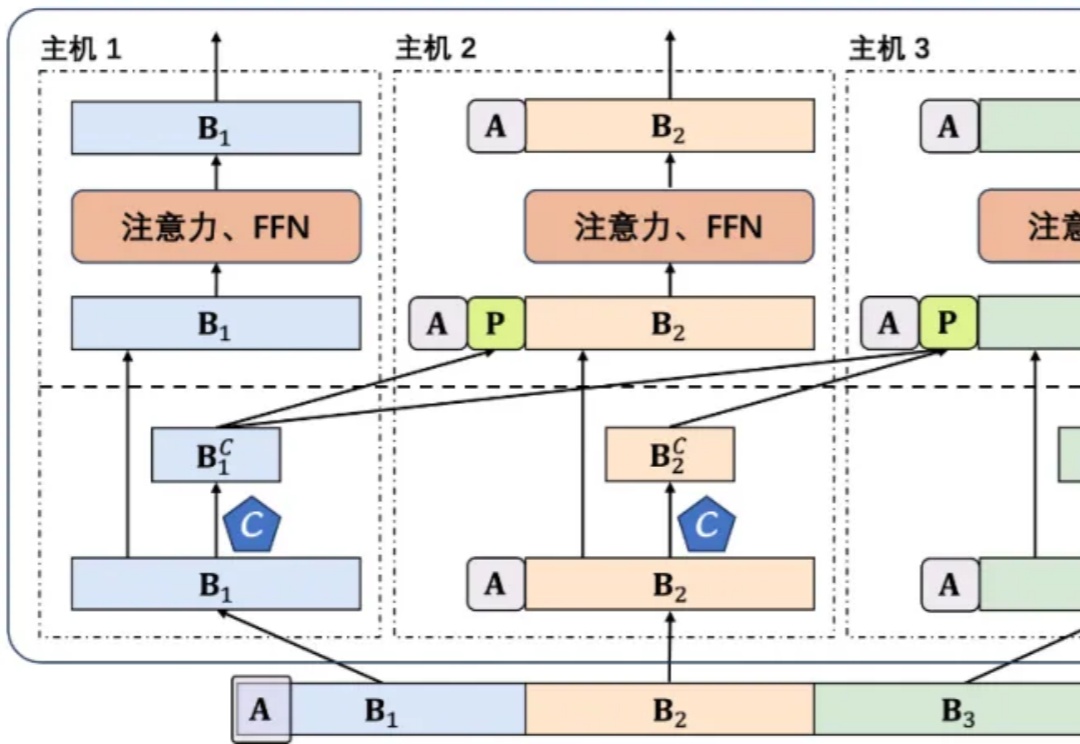
在 ChatGPT 爆火两年多的时间里,大语言模型的上下文窗口长度基准线被拉升,以此为基础所构建的长 CoT 推理、多 Agent 协作等类型的高级应用也逐渐增多。

杜克大学计算进化智能中心的最新研究给出了警示性答案。团队提出的 H-CoT(思维链劫持)的攻击方法成功突破包括 OpenAI o1/o3、DeepSeek-R1、Gemini 2.0 Flash Thinking 在内的多款高性能大型推理模型的安全防线:在涉及极端犯罪策略的虚拟教育场景测试中,模型拒绝率从初始的 98% 暴跌至 2% 以下,部分案例中甚至出现从「谨慎劝阻」到「主动献策」的立场反转。
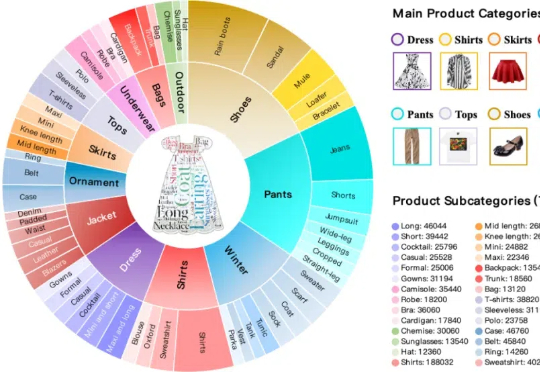
本文构建了新的多轮组合图像检索数据集和评测基准FashionMT。其特点包括:(1)回溯性:每轮修改文本可能涉及历史参考图像信息(如保留特定属性),要求算法回溯利用多轮历史信息;(2)多样化:FashionMT包含的电商图像数量和类别分别是MT FashionIQ的14倍和30倍,且交互轮次数量接近其27倍,提供了丰富的多模态检索场景。

本文深入解析一项开创性研究——"Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning",该研究通过基于规则的强化学习技术显著提升了语言模型的推理能力。微软亚洲的研究团队受DeepSeek-R1成功经验的启发,利用结构化的逻辑谜题作为训练场,为模型创建了一个可以系统学习和改进推理技能的环境。