
小学生也能听懂的FlashMLA技术解析 - 哆啦 A 梦的「超高效作业处理魔盒」!
小学生也能听懂的FlashMLA技术解析 - 哆啦 A 梦的「超高效作业处理魔盒」!大雄:(趴在书桌前抓头发)哆啦 A 梦!今天的作文题目是《未来的机器人》,可是我要写800字!写不完啦!哆啦 A 梦:(得意叉腰)别担心!我刚从22世纪带来了「超高效作业处理器」——FlashMLA 魔盒!它能让写作文像吃铜锣烧一样快哦!
来自主题: AI资讯
8399 点击 2025-02-25 09:41
 搜索
搜索
大雄:(趴在书桌前抓头发)哆啦 A 梦!今天的作文题目是《未来的机器人》,可是我要写800字!写不完啦!哆啦 A 梦:(得意叉腰)别担心!我刚从22世纪带来了「超高效作业处理器」——FlashMLA 魔盒!它能让写作文像吃铜锣烧一样快哦!
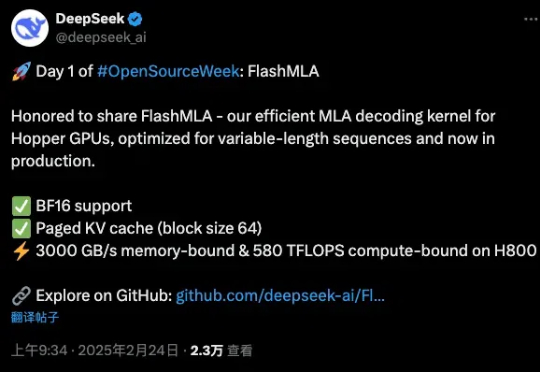
刚刚,万众瞩目的DeepSeek,开源了他们第一天的项目。FlashMLA是一款面向Hopper GPU的高效MLA解码内核,并针对可变长度序列的服务场景进行了优化。

DeepSeek开源周第一天就放大招!FlashMLA强势登场,这是专为英伟达Hopper GPU打造MLA解码内核。注意,DeepSeek训练成本极低的两大关键,一个是MoE,另一个就是MLA。

上周五,DeepSeek 发推说本周将是开源周(OpenSourceWeek),并将连续开源五个软件库。第一个项目,果然与推理加速有关。北京时间周一上午 9 点,刚一上班(同时是硅谷即将下班的时候),DeepSeek 兑现了自己的诺言,开源了一款用于 Hopper GPU 的高效型 MLA 解码核:FlashMLA。
现在写代码,最fashion的“姿势”应该是什么?答案或许就是:截图。商汤在今天GDC(全球开发者先锋大会)中办公小浣熊2.0最新升级的功能。
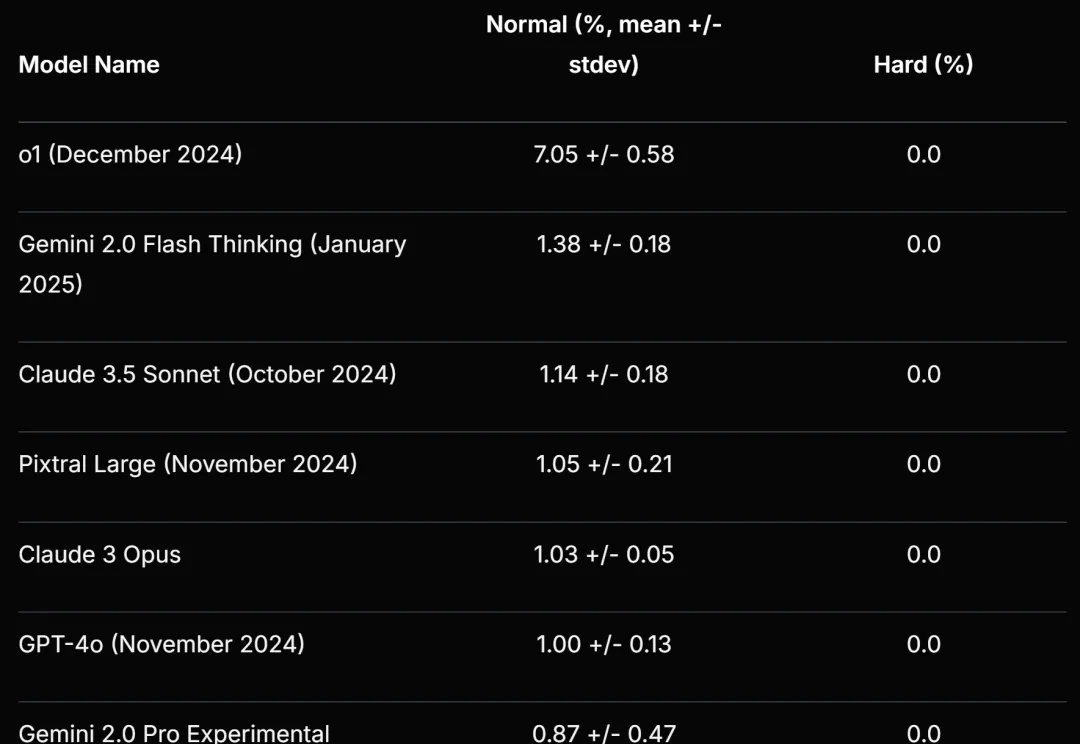
Scale AI 等提出的新基准再次暴露了大语言模型的弱点。

本周三,该公司全面发布 Gemini 2.0 Flash、 Gemini 2.0 Flash-Lite 以及新一代旗舰大模型 Gemini 2.0 Pro 实验版本,并且还在 Gemini App 中推出了其推理模型 Gemini 2.0 Flash Thinking。
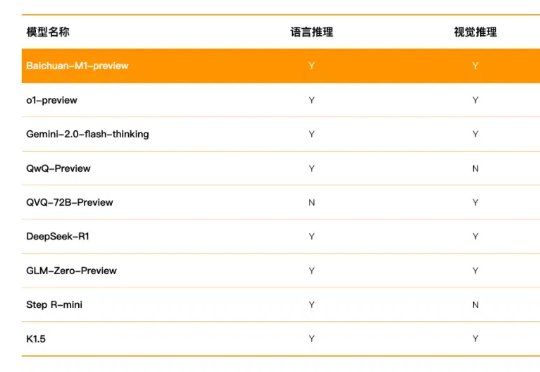
就在本周,Kimi 的新模型打开了强化学习 Scaling 新范式,DeepSeek R1 用开源的方式「接班了 OpenAI」,谷歌则把 Gemini 2.0 Flash Thinking 的上下文长度延伸到了 1M。1 月 24 日上午,百川智能重磅发布了国内首个全场景深度思考模型,把这一轮军备竞赛推向了高潮。

新年第一天,陈天奇团队的FlashInfer论文出炉!块稀疏、可组合、可定制、负载均衡......更快的LLM推理技术细节全公开。
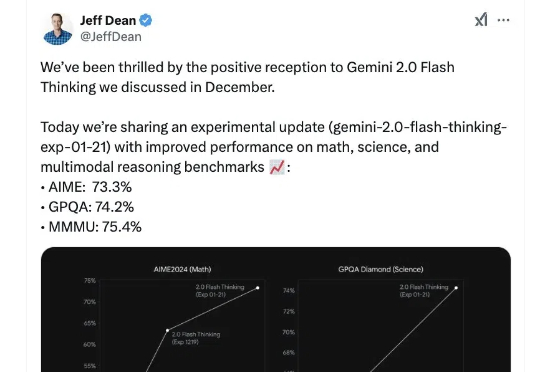
就在国内各家大模型厂商趁年底疯狂卷的时候,太平洋的另一端也没闲着。 就在今天,谷歌发布了 Gemini 2.0 Flash Thinking 推理模型的加强版,并再次登顶 Chatbot Arena 排行榜。