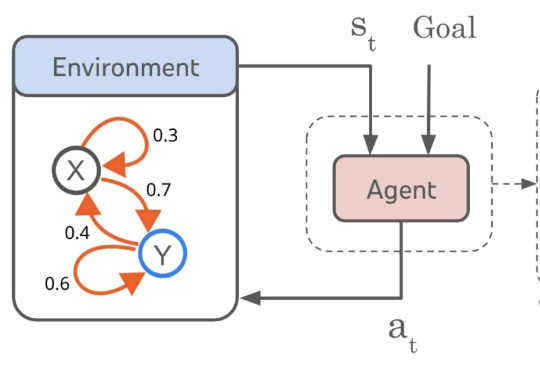
AGI真方向?谷歌证明:智能体在自研世界模型,世界模型is all You Need
AGI真方向?谷歌证明:智能体在自研世界模型,世界模型is all You Need越通用,就越World Models。 我们知道,大模型技术爆发的原点可能在谷歌一篇名为《Attention is All You Need》的论文上。
来自主题: AI技术研报
8335 点击 2025-06-14 13:22
 搜索
搜索
越通用,就越World Models。 我们知道,大模型技术爆发的原点可能在谷歌一篇名为《Attention is All You Need》的论文上。

Transformer已满8岁,革命性论文《Attention Is All You Need》被引超18万次,掀起生成式AI革命。Transformer催生了ChatGPT、Gemini、Claude等诸多前沿产品。更重要的是,它让人类真正跨入了生成式AI时代。
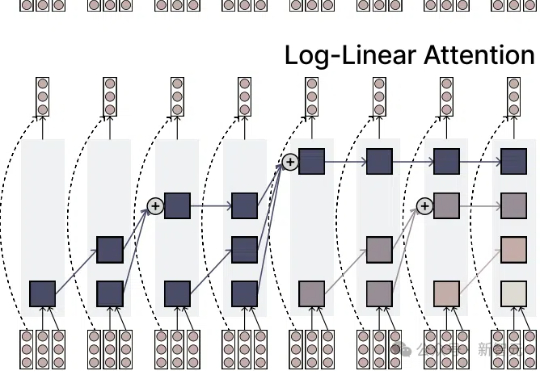
注意力机制的「平方枷锁」,再次被撬开!一招Fenwick树分段,用掩码矩阵,让注意力焕发对数级效率。更厉害的是,它无缝对接线性注意力家族,Mamba-2、DeltaNet 全员提速,跑分全面开花。长序列处理迈入log时代!

研究者针对 few-shot 图像编辑提出一个新的自回归模型结构 ——InstaManip,并创新性地提出分组自注意力机制(group self-attention),在此任务上取得了优异的效果。
和人工标记数据说拜拜,利用预训练语言模型中的注意力机制就能选择可激发推理能力的训练数据!
自 OpenAI 发布 Sora 以来,AI 视频生成技术进入快速爆发阶段。凭借扩散模型强大的生成能力,我们已经可以看到接近现实的视频生成效果。但在模型逼真度不断提升的同时,速度瓶颈却成为横亘在大规模应用道路上的最大障碍。
「未来,99% 的 attention 将是大模型 attention,而不是人类 attention。」这是 AI 大牛 Andrej Karpathy 前段时间的一个预言。这里的「attention」可以理解为对内容的需求、处理和分析。也就是说,他预测未来绝大多数资料的处理工作将由大模型来完成,而不是人类。
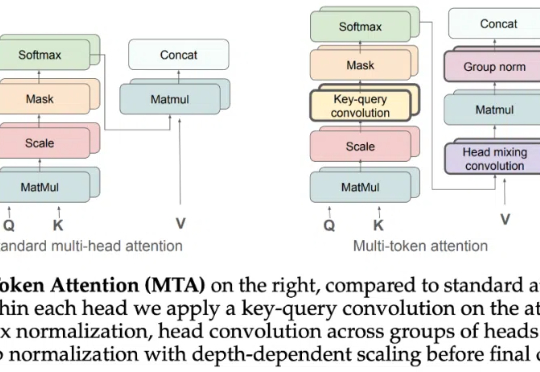
Attention 还在卷自己。

晚点:过去将近 6 个月,AI 领域最重要的两件事,一是 OpenAI 去年 9 月 o1 发布,另一个是近期 DeepSeek 在发布 R1 后掀起全民狂潮。我们可以从这两个事儿开始聊。你怎么看 o1 和 R1 分别的意义?

大模型同样的上下文窗口,只需一半内存就能实现,而且精度无损? 前苹果ASIC架构师Nils Graef,和一名UC伯克利在读本科生一起提出了新的注意力机制Slim Attention。