在长文本上比Flash Attention快10倍!清华等提出APB序列并行推理框架
在长文本上比Flash Attention快10倍!清华等提出APB序列并行推理框架在 ChatGPT 爆火两年多的时间里,大语言模型的上下文窗口长度基准线被拉升,以此为基础所构建的长 CoT 推理、多 Agent 协作等类型的高级应用也逐渐增多。
来自主题: AI技术研报
8991 点击 2025-03-12 14:53
 搜索
搜索
在 ChatGPT 爆火两年多的时间里,大语言模型的上下文窗口长度基准线被拉升,以此为基础所构建的长 CoT 推理、多 Agent 协作等类型的高级应用也逐渐增多。
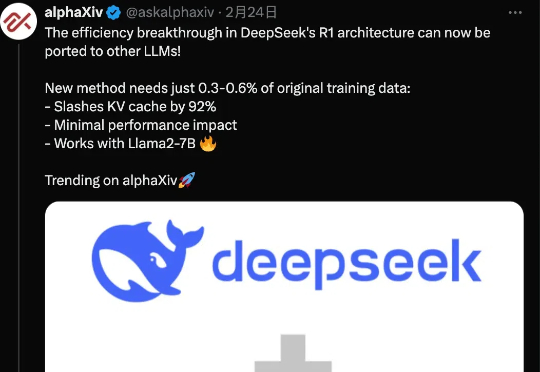
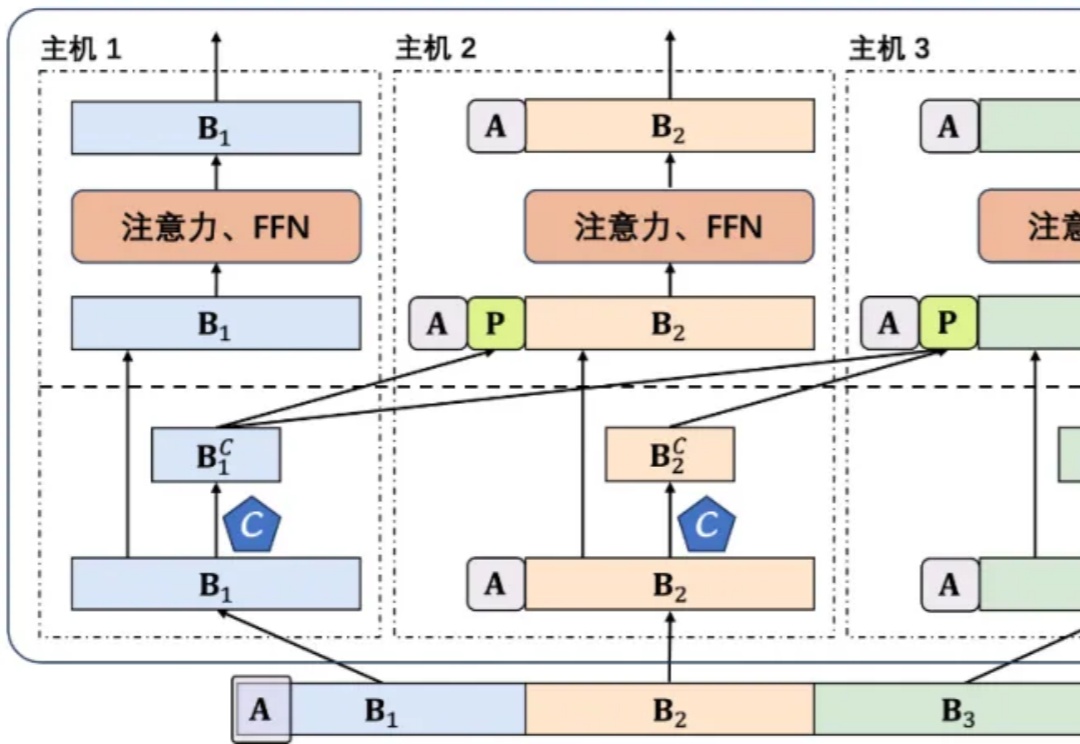
DeepSeek-R1 作为 AI 产业颠覆式创新的代表轰动了业界,特别是其训练与推理成本仅为同等性能大模型的数十分之一。多头潜在注意力网络(Multi-head Latent Attention, MLA)是其经济推理架构的核心之一,通过对键值缓存进行低秩压缩,显著降低推理成本 [1]。
当DeepSeek引发业界震动时,元始智能创始人彭博正专注于一个更宏大的愿景。
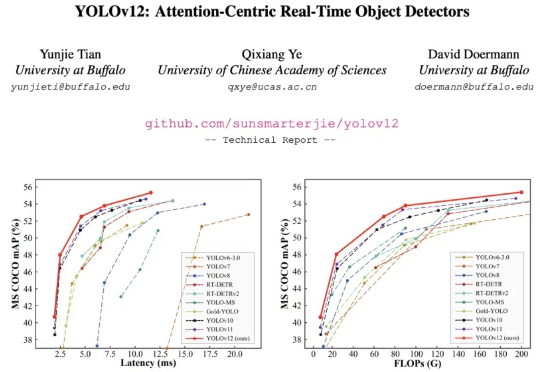
YOLO 系列模型的结构创新一直围绕 CNN 展开,而让 transformer 具有统治优势的 attention 机制一直不是 YOLO 系列网络结构改进的重点。这主要的原因是 attention 机制的速度无法满足 YOLO 实时性的要求。

新年第一天,陈天奇团队的FlashInfer论文出炉!块稀疏、可组合、可定制、负载均衡......更快的LLM推理技术细节全公开。
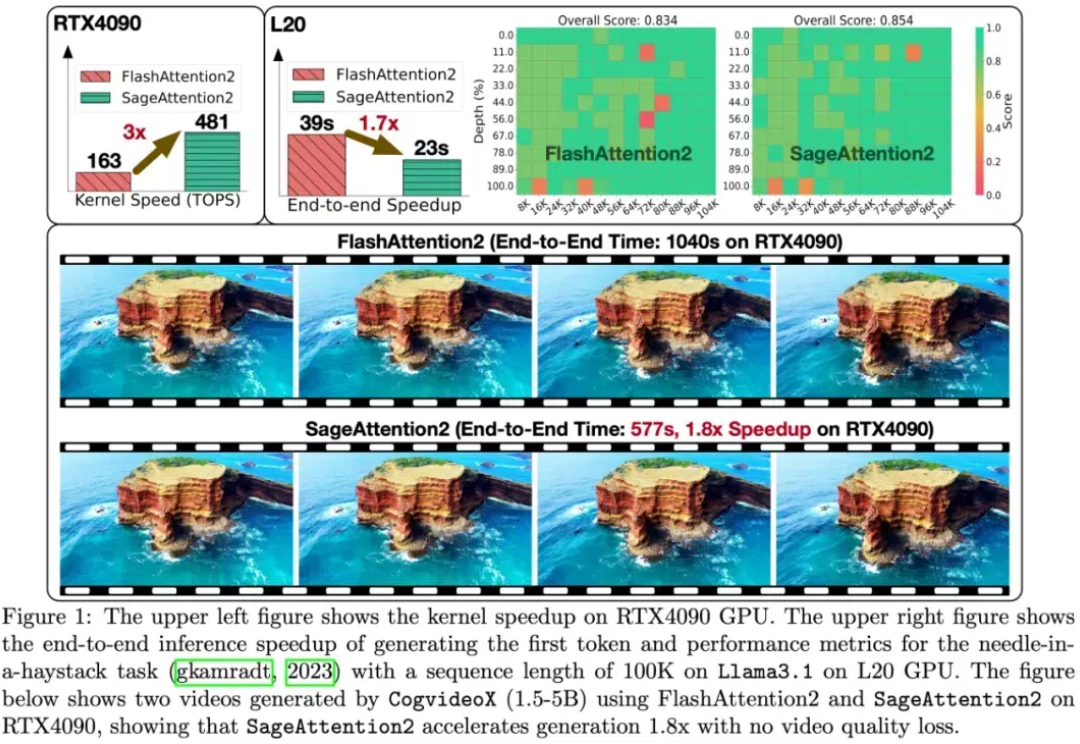
大模型中,线性层的低比特量化已经逐步落地。然而,对于注意力模块,目前几乎各个模型都还在用高精度(例如 FP16 或 FP32)的注意力运算进行训练和推理。并且,随着大型模型需要处理的序列长度不断增加,Attention(注意力运算)的时间开销逐渐成为主要开销。
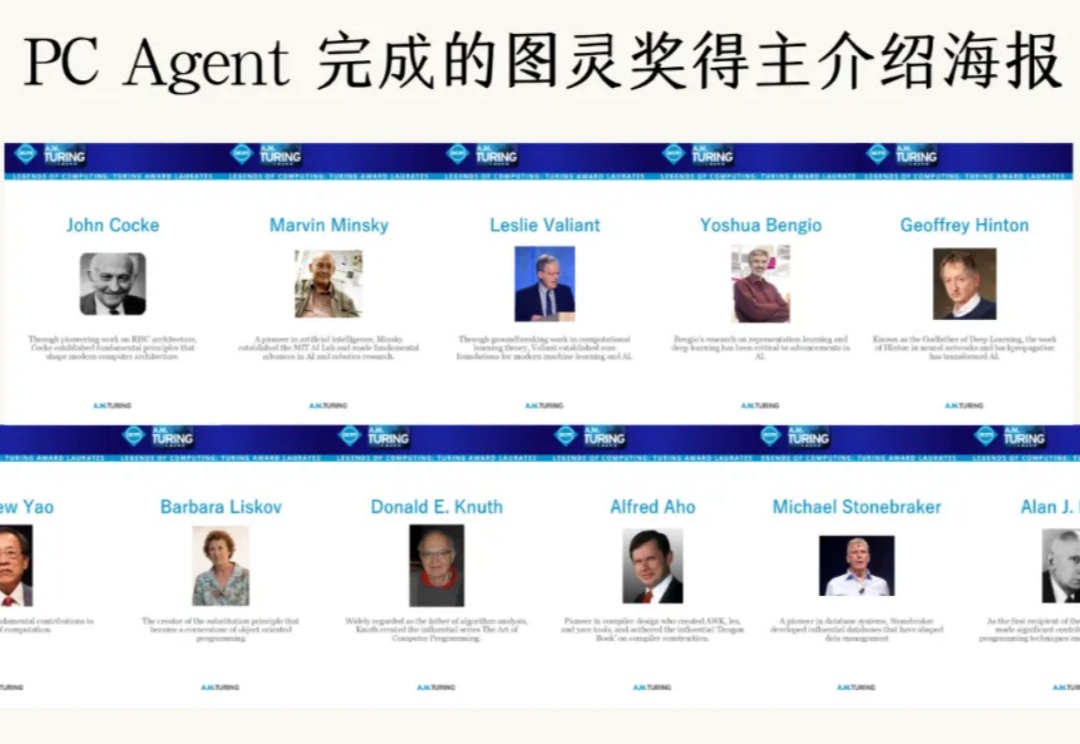
想象这样一个场景:深夜 11 点,你已经忙碌了一天,正准备休息,却想起明天早上还得分享一篇经典论文《Attention Is All You Need》,需要准备幻灯片。这时,你突然想到了自己的 AI 助手 —— PC Agent。
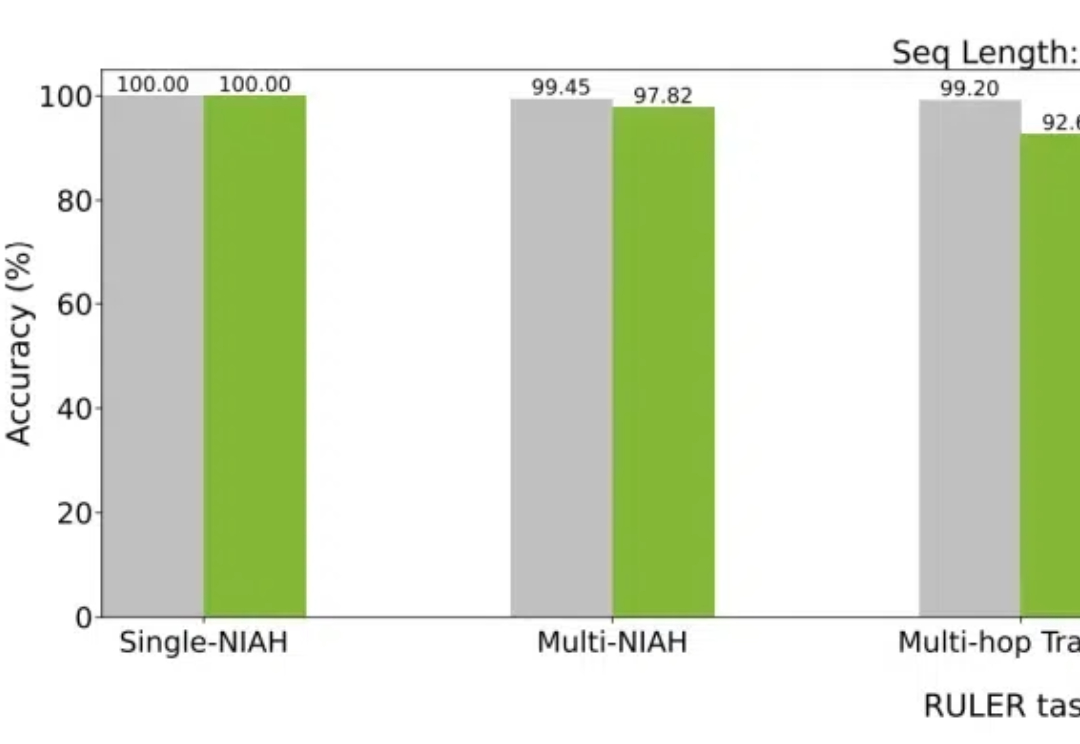
大模型如今已具有越来越长的上下文,而与之相伴的是推理成本的上升。英伟达最新提出的Star Attention,能够在不损失精度的同时,显著减少推理计算量,从而助力边缘计算。

随着scaling law撞墙新闻爆出,全球科技圈、资本市场关于大模型发展触及天花板的讨论愈演愈烈。那么,AI发展是否放缓?后续又将如何发展?商业模式如何突破?

随着大语言模型在长文本场景下的需求不断涌现,其核心的注意力机制(Attention Mechanism)也获得了非常多的关注。