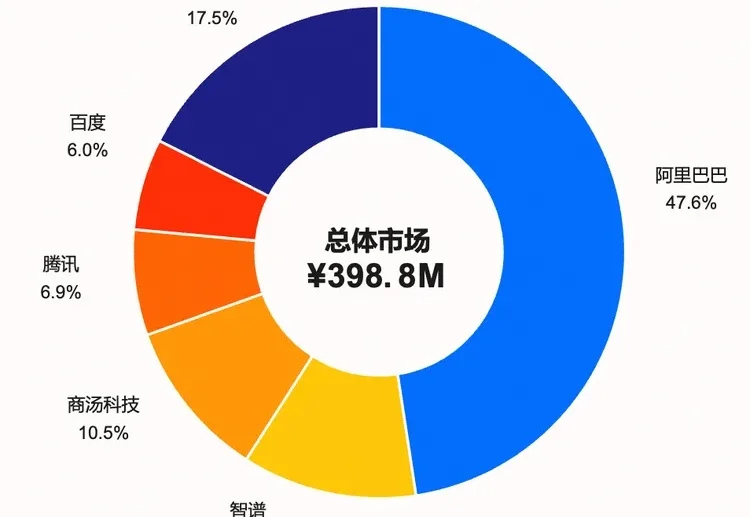
47.6%,阿里Qoder拿到了比跑分更硬的成绩
47.6%,阿里Qoder拿到了比跑分更硬的成绩对 AI Coding 来说,有人用,比任何 Benchmark 都管用,而有人持续付费,又比有人用更管用。
来自主题: AI资讯
5326 点击 2026-07-16 14:45
 搜索
搜索
对 AI Coding 来说,有人用,比任何 Benchmark 都管用,而有人持续付费,又比有人用更管用。
7月2日,字节 Seed 发布了一个 Agent评测项目 EdgeBench。看起来又是一个 benchmark,但它问了一个其他榜单不问的问题。EdgeBench 的切口就是把盲区里的东西放进评测,解答一个问题:把Agent扔进一个陌生环境,12小时后,你能变强多少?
为了解决这一问题,来自 University of Arizona、Zoom 与 Stony Brook University 的研究团队推出了 VISTA(VIsual Spec-To-App Benchmark), 首个面向 Visual Spec-to-Web-App Coding Agents 的端到端 Benchmark。

我们最近在重新思考一件事:到底什么样的 Benchmark,才值得今天继续做?

这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。

今年开年以来,不管是硅谷、还是国内的 AI 投资圈子,都不太敢投 AI 应用了。

根据我长期使用的观察,0.3 倍率说是用 Kiro 逆向出来的 Claude,2.0 倍率说是正经 Claude Max 号池接出来的。听起来后者肯定更靠谱。我一开始也这么想的。毕竟倍率差了快七倍,价格摆在那,总不至于拿假货糊弄人吧。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,

2026 年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到 benchmark 成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。

Mechanize 发布了一项硬核测试:给前沿 AI coding agents 24 小时,用 Rust 从零写一个完整的 Game Boy Advance 模拟器,再和顶级开源模拟器 Mesen2 逐帧对比打分。