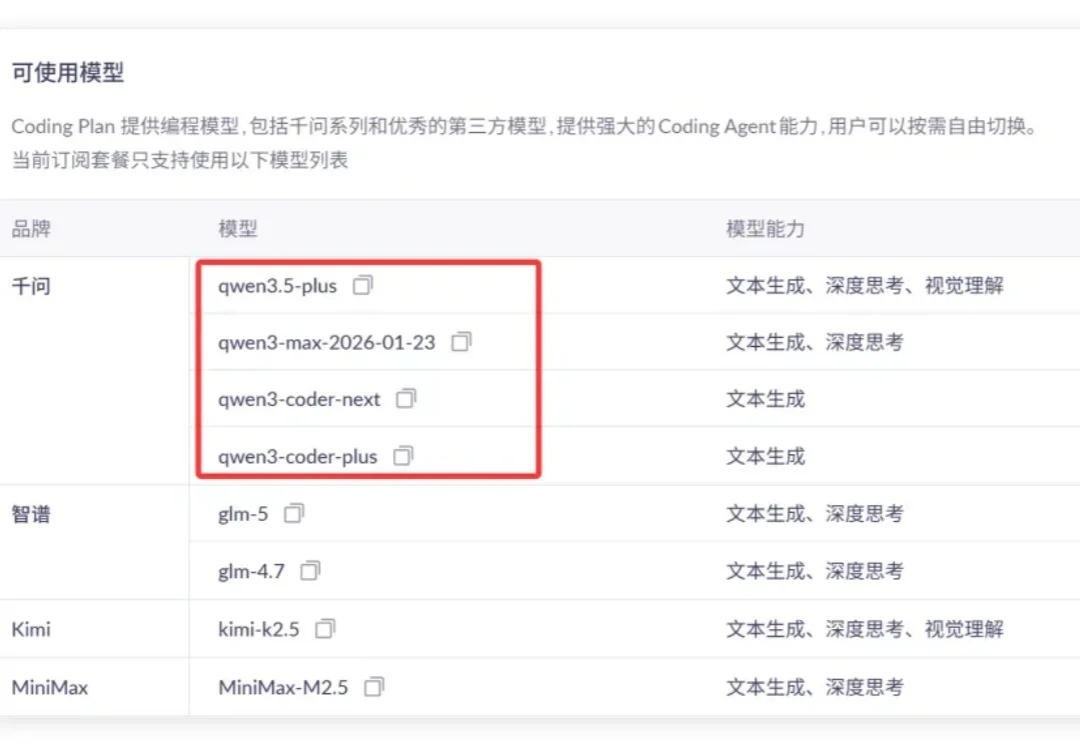
日嫖1000次!Qwen3.6反代API接入任意工具
日嫖1000次!Qwen3.6反代API接入任意工具昨天我发现 Qwen3.6“倒反天罡”。
来自主题: AI技术研报
8528 点击 2026-04-13 15:02
 搜索
搜索
昨天我发现 Qwen3.6“倒反天罡”。
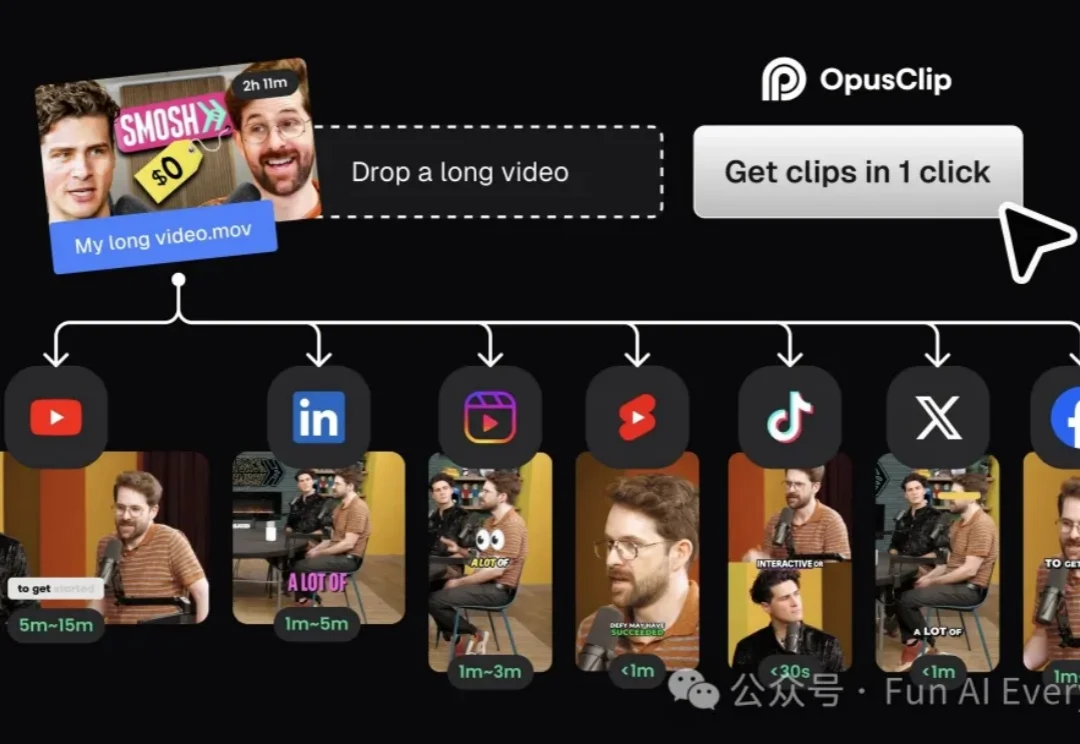
OpusClip 是一款把长视频、长内容自动剪成可发布的短视频片段的 AI 工具,服务内容创作者和企业内容团队。
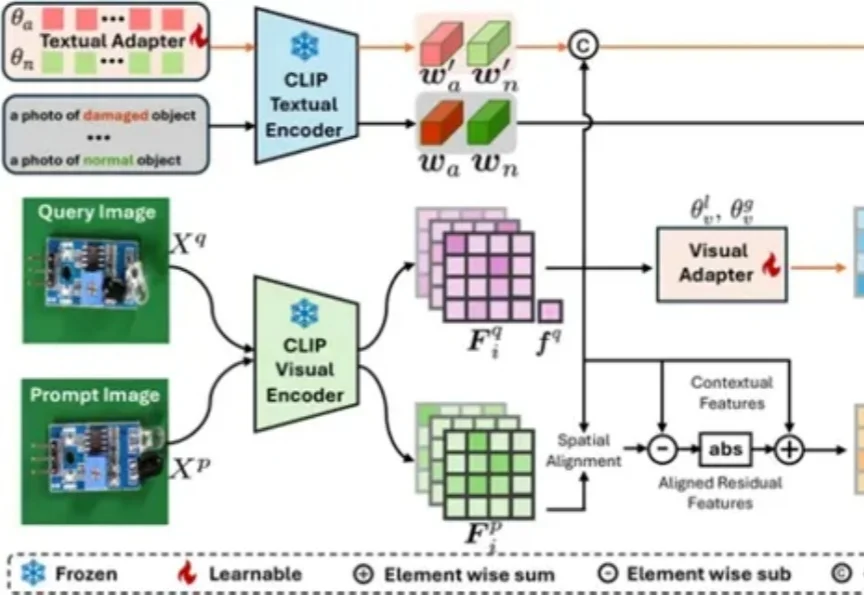
视觉模型用于工业“缺陷检测”等领域已经相对成熟,但当前普遍使用的传统模型在训练时对数据要求较高,需要大量的经过精细标注的数据才能训练出理想效果。
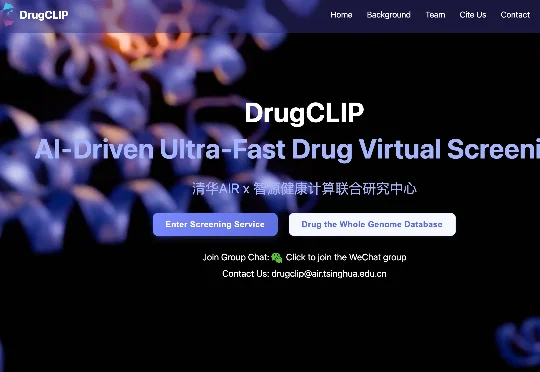
清华大学智能产业研究院(AIR)联合清华大学生命学院、清华大学化学系在Science上发表论文:《深度对比学习实现基因组级别药物虚拟筛选》。团队研发了一个AI驱动的超高通量药物虚拟筛选平台DrugCLIP。

2025年前盛行的闭源+重资本范式正被DeepSeek-R1与月之暗面Kimi K2 Thinking改写,二者以数百万美元成本、开源权重,凭MoE与MuonClip等优化,在SWE-Bench与BrowseComp等基准追平或超越GPT-5,并以更低API价格与本地部署撬动市场预期,促使行业从砸钱堆料转向以架构创新与稳定训练为核心的高效路线。

这年头,AI 创造的视觉世界真是炫酷至极。但真要跟细节较真儿,这些大模型的「眼力见儿」可就让人难绷了。
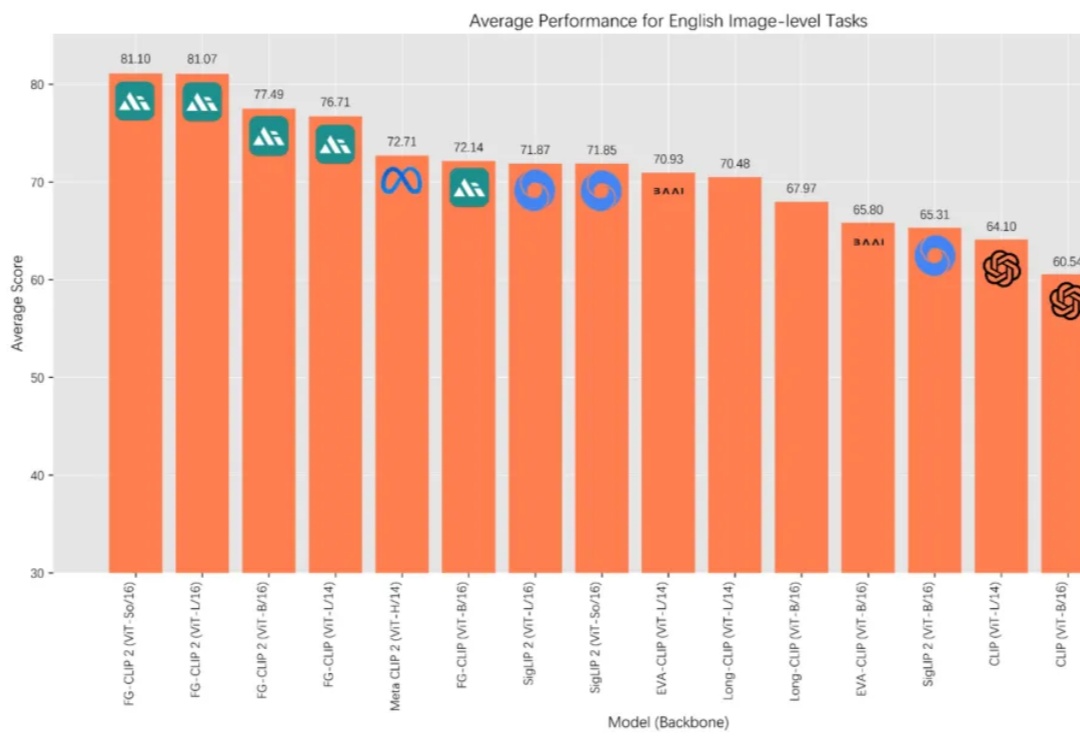
在 AI 多模态的发展历程中,OpenAI 的 CLIP 让机器第一次具备了“看懂”图像与文字的能力,为跨模态学习奠定了基础。如今,来自 360 人工智能研究院冷大炜团队的 FG-CLIP 2 正式发布并开源,在中英文双语任务上全面超越 MetaCLIP 2 与 SigLIP 2,并通过新的细粒度对齐范式,补足了第一代模型在细节理解上的不足。
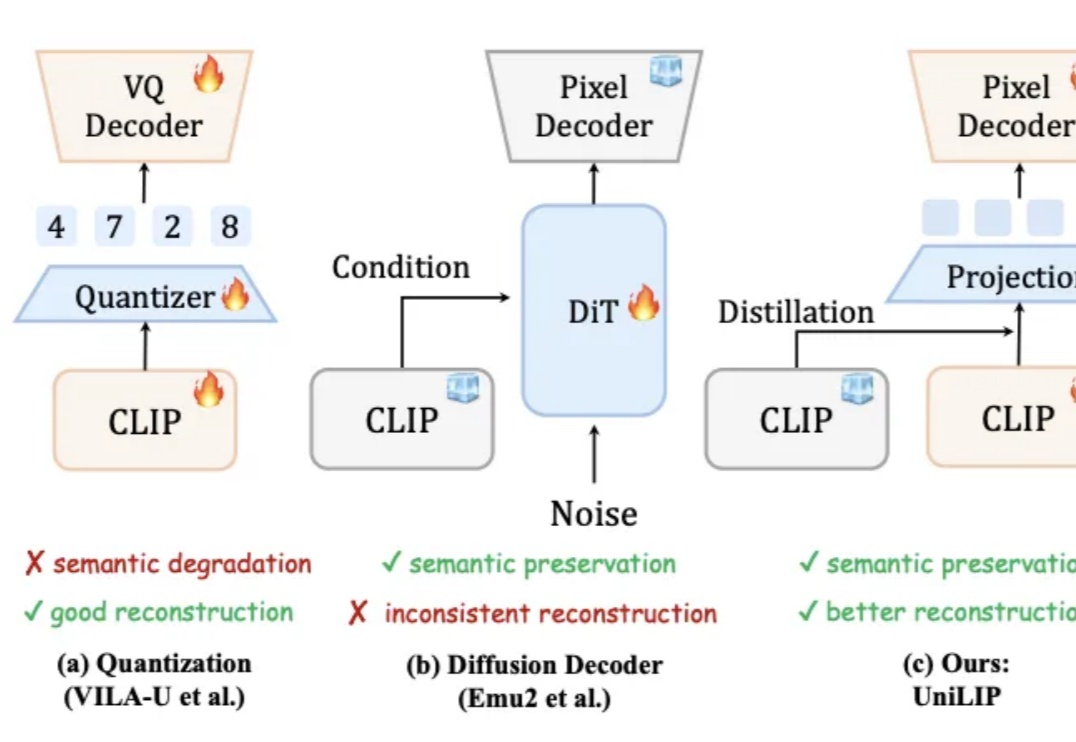
统一多模态模型要求视觉表征必须兼顾语义(理解)和细节(生成 / 编辑)。早期 VAE 因语义不足而理解受限。近期基于 CLIP 的统一编码器,面临理解与重建的权衡:直接量化 CLIP 特征会损害理解性能;而为冻结的 CLIP 训练解码器,又因特征细节缺失而无法精确重建。例如,RAE 使用冻结的 DINOv2 重建,PSNR 仅 19.23。
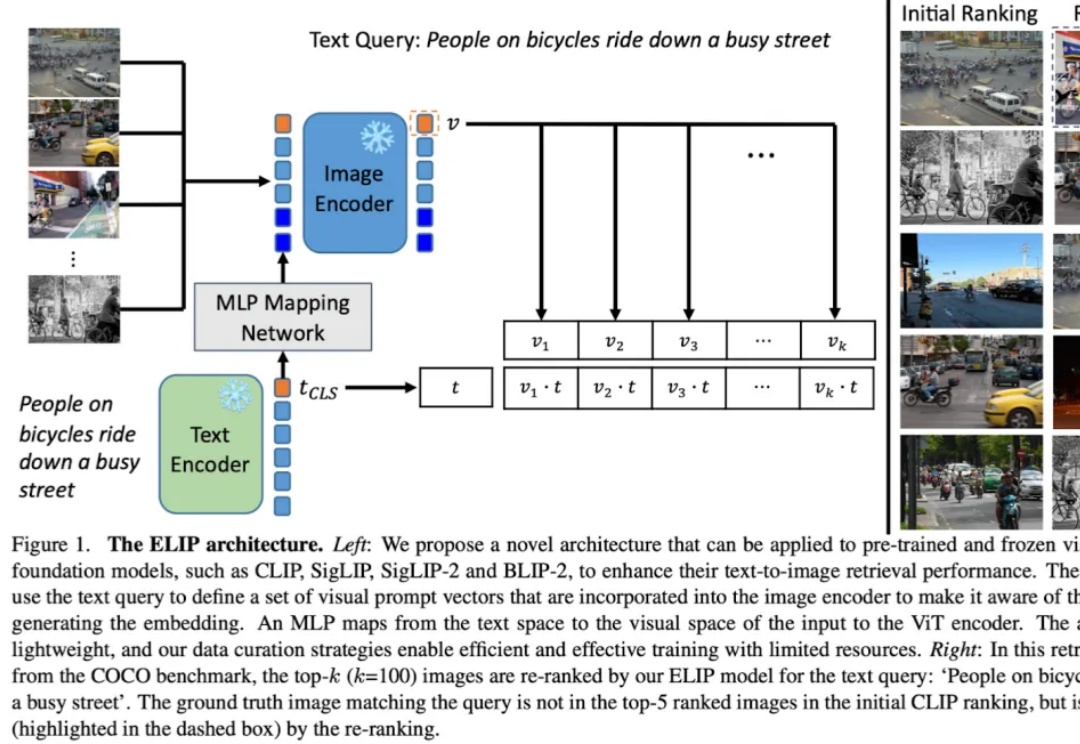
多模态图片检索是计算机视觉和多模态机器学习领域很重要的一个任务。现在大家做多模态图片检索一般会用 CLIP/SigLIP 这种视觉语言大模型,因为他们经过了大规模的预训练,所以 zero-shot 的能力比较强。

昨天在 Copilot 秋季发布会上,微软正式推出了 Mico——一个全新的 Copilot 虚拟角色,它被视为 AI 时代的 Clippy。 这不仅是 Copilot 的一次大整容,也像是在说微软,要继续押注我们需要一个 AI 伴侣,希望 AI 成为一种社交体验。