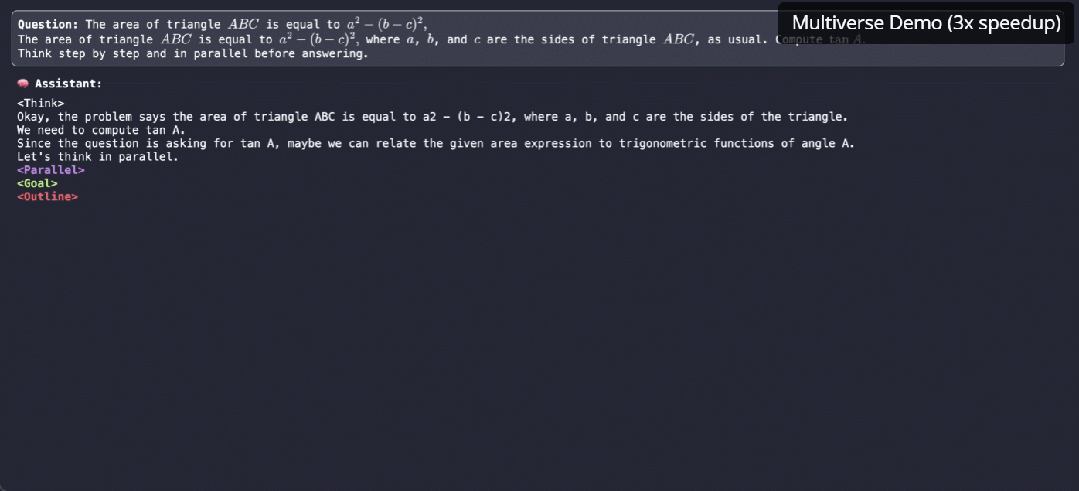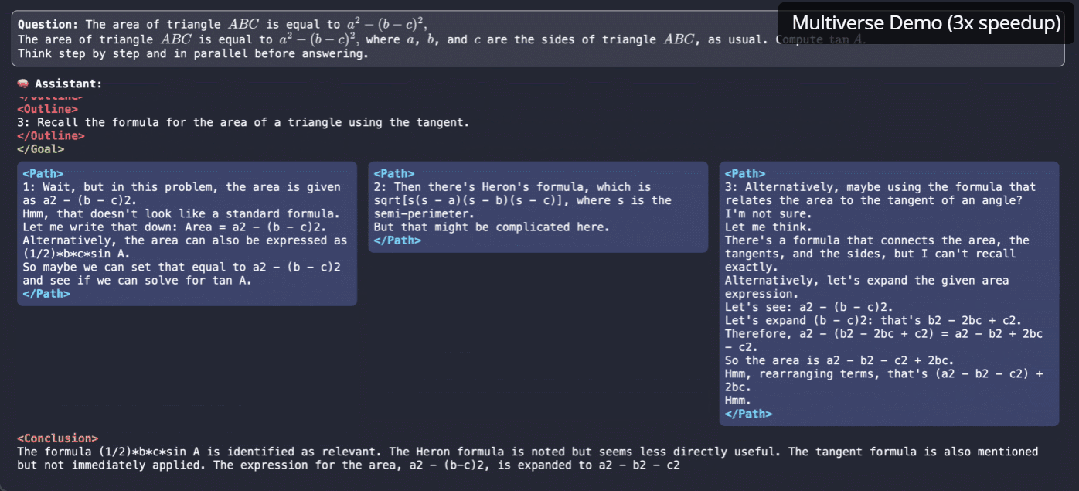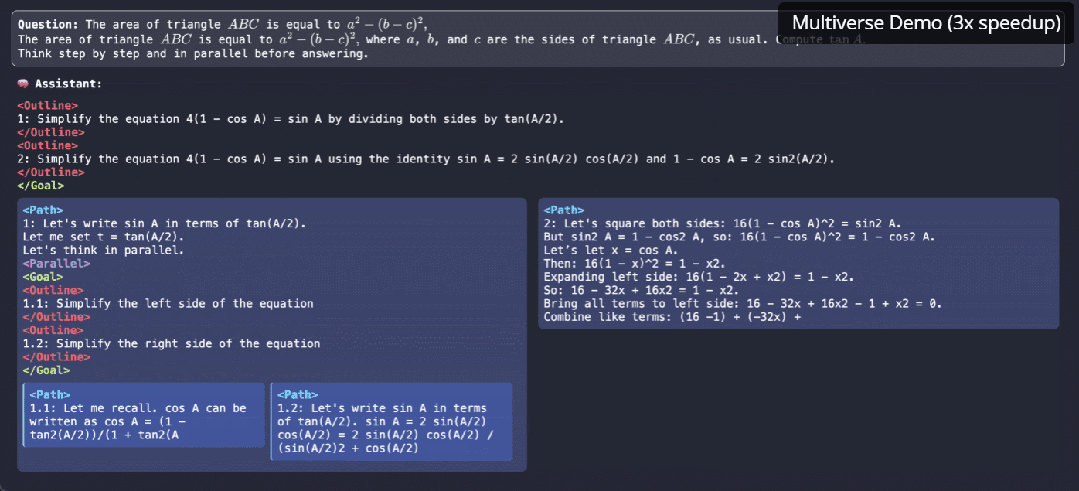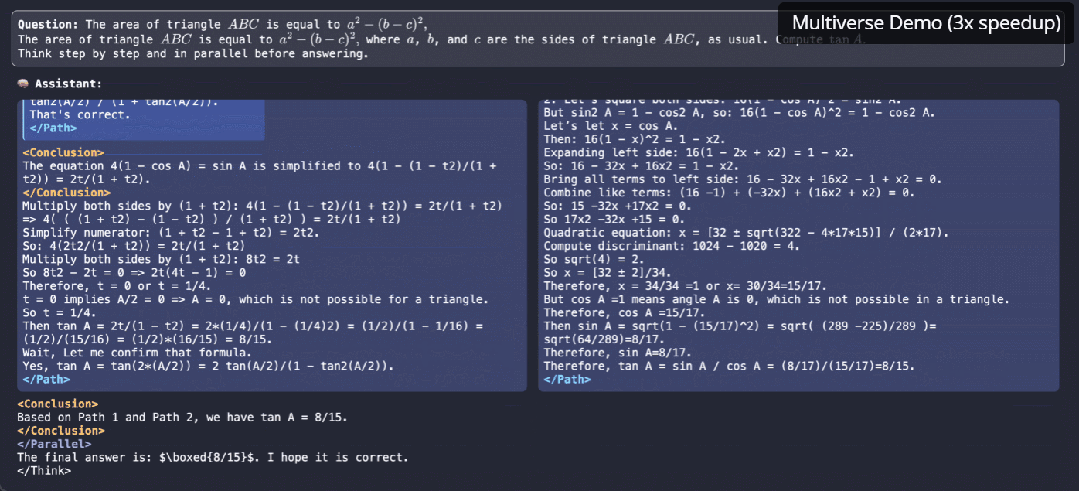
逐个token太慢!大模型原生并行出token,CMU、英伟达新作Multiverse
逐个token太慢!大模型原生并行出token,CMU、英伟达新作Multiverse原生并行生成不仅仅是加速,它是我们对 LLM 推理思考方式的根本转变。
来自主题: AI技术研报
11160 点击 2025-06-18 10:53
 搜索
搜索
原生并行生成不仅仅是加速,它是我们对 LLM 推理思考方式的根本转变。

近期,人工智能领域对“具身智能”的讨论持续升温——如何让AI不仅能“理解”语言,还能用“手”去感知世界、操作环境、完成任务?相比语言模型的迅猛发展,真正通向Agent的下一步,需要AI具备跨模态感知、动作控制与现实泛化能力。具身智能让AI不仅能“思考”,更能“感知”“行动”。

扩散建模+自回归,打通文本生成任督二脉!这一次,来自康奈尔、CMU等机构的研究者,提出了前所未有的「混合体」——Eso-LM。有人惊呼:「自回归危险了。」
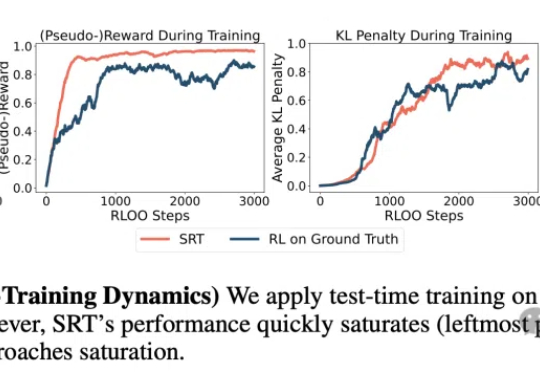
数据枯竭正成为AI发展的新瓶颈!CMU团队提出革命性方案SRT:让LLM实现无需人类标注的自我进化!SRT初期就能迭代提升数学与推理能力,甚至性能逼近传统强化学习的效果,揭示了其颠覆性潜力。

2002年,在拿下中国高校第一个ACM(计算机领域最顶尖的程序设计大赛)金牌后,上海交大设立了“ACM班”,这个用最高竞赛命名的班级后来人尽皆知,成为中国AI人才的重要阵地。也在那年,李磊成为ACM班第一届的学生。在ACM班他第一次意识到,“原来计算机能帮助解决人类的这么多问题。”

AI 不允许有人不会搭乐高。

如何将一句简单的文字描述变成物理稳定的乐高模型?LegoGPT通过物理感知技术,确保98.8%的设计稳如磐石。
当您的Agent需要规划多步骤操作以达成目标时,比如游戏策略制定或旅行安排优化等等,传统规划方法往往需要复杂的搜索算法和多轮提示,计算成本高昂且效率不佳。来自Google DeepMind和CMU的研究者提出了一个简单却非常烧脑的问题:我们是否一直在用错误的方式选择示例来引导LLM学习规划?
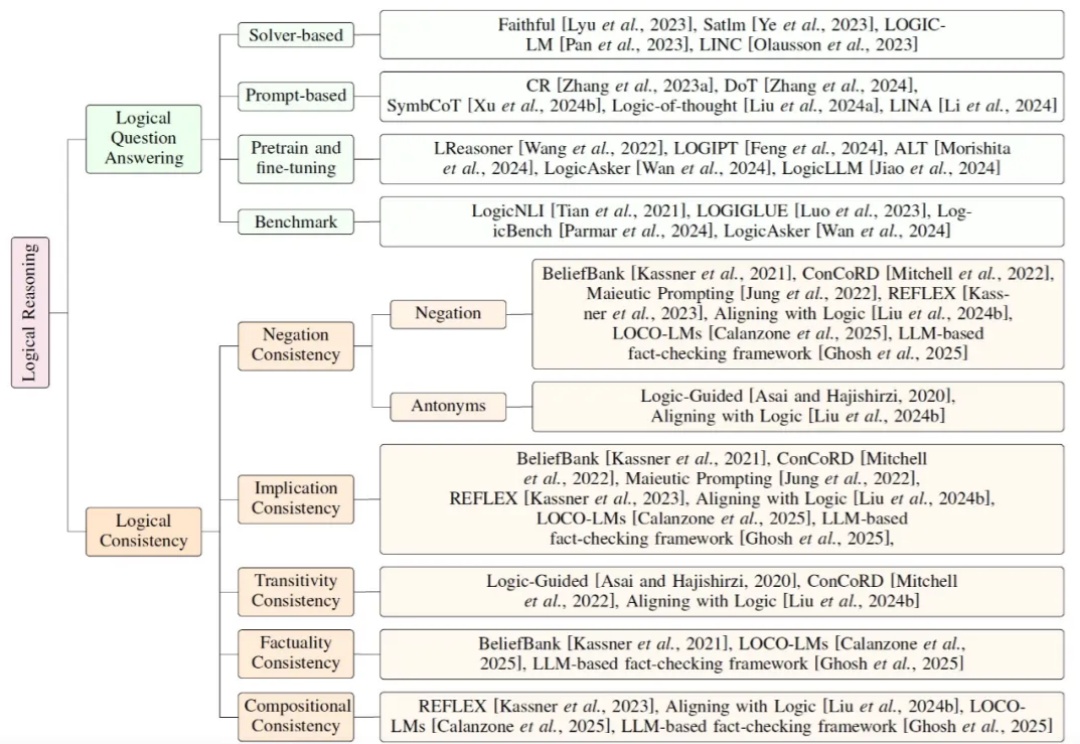
当前大模型研究正逐步从依赖扩展定律(Scaling Law)的预训练,转向聚焦推理能力的后训练。鉴于符号逻辑推理的有效性与普遍性,提升大模型的逻辑推理能力成为解决幻觉问题的关键途径。

颠覆LLM预训练认知:预训练token数越多,模型越难调!CMU、斯坦福、哈佛、普林斯顿等四大名校提出灾难性过度训练。