
CMU辍学创业,她成了全球最年轻白手起家女亿万富翁!
CMU辍学创业,她成了全球最年轻白手起家女亿万富翁!她21岁创立AI公司,靠5%股份逆风翻盘!Lucy Guo如何从自学编程到辍学创业,超越Taylor Swift,成为全球最年轻的白手起家女亿万富翁?Scale AI最新估值为250亿美元,这也让联合创始人Lucy Guo凭借其股份身价暴涨。
来自主题: AI资讯
10325 点击 2025-04-26 11:27
 搜索
搜索
她21岁创立AI公司,靠5%股份逆风翻盘!Lucy Guo如何从自学编程到辍学创业,超越Taylor Swift,成为全球最年轻的白手起家女亿万富翁?Scale AI最新估值为250亿美元,这也让联合创始人Lucy Guo凭借其股份身价暴涨。

公考行测中的逻辑推理题,是不少考生的噩梦,这次,CMU团队就此为基础,打造了一套逻辑谜题挑战。实测后发现,o1、Gemini-2.5 Pro、Claude-3.7-Sonnet这些顶尖大模型全部惨败!最强的AI正确率也只有57.5%,而人类TOP选手却能接近满分。

2025 CSRankings新鲜出炉了!CMU稳坐全球第一,中国高校强势崛起,清华摘得第2,上交大与浙大并列第3,北大位居第5。中国在AI领域表现尤为抢眼,上交大、清华、北大、浙大包揽前四,中国科学院与哈工大也跻身全球前十。
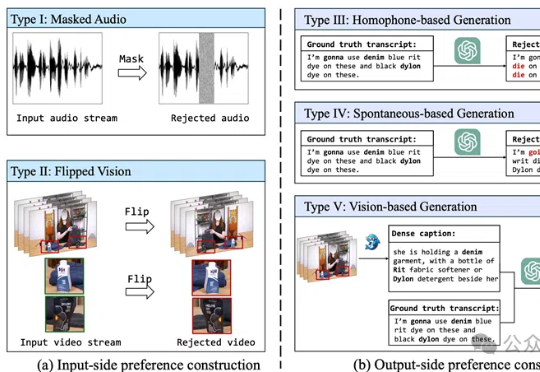
视觉+语音=更强的语音识别!BPO-AVASR通过优化音视频输入和输出偏好,提升语音识别在真实场景中的准确性,解决了传统方法在噪声、口语化和视觉信息利用不足的问题。

如今,哈佛斯坦福这类顶尖名校的中国毕业生,开始向DeepSeek等中国AI公司疯狂投简历了!与此同时,美国众议院则被曝出直接质问斯坦福、CMU等六所大学:为何招收如此多中国学生参加STEM项目?并且要求上交所有中国学生信息。
大语言模型(LLM)在推理领域的最新成果表明了通过扩展测试时计算来提高推理能力的潜力,比如 OpenAI 的 o1 系列。

CMU团队用LCPO训练了一个15亿参数的L1模型,结果令人震惊:在数学推理任务中,它比S1相对提升100%以上,在逻辑推理和MMLU等非训练任务上也能稳定发挥。更厉害的是,要求短推理时,甚至击败了GPT-4o——用的还是相同的token预算!

在面对复杂的推理任务时,SFT往往让大模型显得力不从心。最近,CMU等机构的华人团队提出了「批判性微调」(CFT)方法,仅在 50K 样本上训练,就在大多数基准测试中优于使用超过200万个样本的强化学习方法。

人类通过课堂学习知识,并在实践中不断应用与创新。那么,多模态大模型(LMMs)能通过观看视频实现「课堂学习」吗?新加坡南洋理工大学S-Lab团队推出了Video-MMMU——全球首个评测视频知识获取能力的数据集,为AI迈向更高效的知识获取与应用开辟了新路径。

英伟达卡内基梅隆大学一起,给宇树机器人“一雪前耻”了(doge)。只通过一个训练框架,机器人就能成为“学人精”,完成各种高难度敏捷动作。